

この記事では主に MySQL で遅い SQL ステートメントを見つける方法を紹介します 必要な友達は、 mysql で遅い SQL ステートメントを見つける方法を参照してください。これは、多くの人にとって問題になる可能性があります。MySQL は、実行効率の低い SQL ステートメントを見つけるために低速クエリ ログを使用します。このログ ファイルを表示して、実行時間が long_query_
time秒を超えるすべての SQL ステートメントのファイルを見つけます。以下は、MySQL で遅い SQL ステートメントをクエリする方法の概要です 1. MySQL データベース
非効率な SQL ステートメントを時間内にキャプチャするのに役立ついくつかの構成オプションがあります1。slow_query_log パラメータが設定されています。 ONにすると、時間が一定値を超えた実行SQL文を捕捉します。
2、long_query_time
SQL文の実行時間がこの値を超えた場合、ログに記録されます。1以下に設定することをお勧めします。
3、slow_query_log_file
ログのファイル名。
4、log_queries_not_using_indexes
このパラメータは ON に設定されており、
indexesを使用しないすべての SQL ステートメントをキャプチャできますが、この SQL ステートメントは非常に高速に実行される可能性があります。
2. mysql の SQL ステートメントの効率を検出する方法
1. クエリ ログを通じて (1)、Windows で MySQL のスロー クエリを有効にする
Windows システムの MySQL の
設定ファイルは通常、私の .ini です。 [mysqld] を検索し、次のように
コードを追加しますlog-slow-queries = F:/MySQL/log/mysqlslowquery。 log
long_query_time = 2(2)、Linux
でMySQLスロークエリを有効にします。WindowsシステムのMySQL設定ファイルは通常my.cnfで、[mysqld]を見つけて次のようにコードを追加します
log-slow-クエリ=/データ/mysqldata/slowquery。 log
long_query_time=2説明
log-slow-queries = F:/MySQL/log/mysqlslowquery。
は、スロー クエリ ログが保存される場所です。通常、このディレクトリは MySQL 実行アカウントに対して書き込み権限を持っている必要があります。
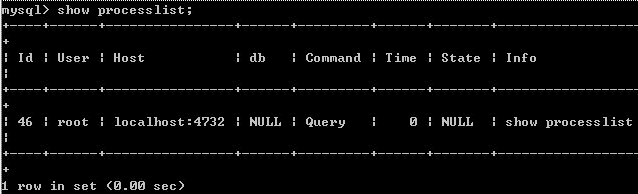
long_query_time=2 は、クエリに時間がかかることを意味します。 2 秒。 2.show processlist
コマンド
WSHOW PROCESSLIST は、実行中のスレッドを表示します。 mysqladmin processlist ステートメントを使用してこの情報を取得することもできます。
ID 列 このクエリ /*/mysqladmin kill プロセス番号を kill する場合に便利です。
ユーザー列
には、root でない場合、このコマンドはその権限内の SQL ステートメントのみを表示します。
ホスト列
には、このステートメントがどの IP とどのポートから送信されたかが表示されます。問題のあるステートメントを発行したユーザーを追跡するために使用されます。
db 列
は、このプロセスが現在接続しているデータベースを示します。
コマンド列
には、現在の接続(通常はsleep、
query、connect)で実行されたコマンドが表示されます。
状態の継続時間、単位は秒です。
state 列 は、現在の接続を使用する SQL ステートメントのステータスを表示します。これは非常に重要な列です。すべてのステータスの説明は、SQL ステートメントの実行における特定の状態にすぎないことに注意してください。たとえば、
情報列
の表示が完了する前に、tmpテーブルへのコピー、結果の並べ替え、データの終了などの状態を経る必要がある場合があります。この SQL 文は長さに制限があるため、表示が不完全ですが、問題文を判断するための重要な根拠となります。
このコマンドで最も重要なのは、mysql によってリストされる状態には主に次のものが含まれます。
テーブルのチェック
データテーブルをチェックします(これは自動です)。
テーブルを閉じる
テーブル内の変更されたデータはディスクにフラッシュされ、使い終わったテーブルは閉じられます。これは簡単な操作ですが、そうでない場合は、ディスク領域がいっぱいであるか、ディスクに高い負荷がかかっているかを確認する必要があります。
Connect Out
レプリケーションスレーブサーバーがマスターサーバーに接続しています。
ディスク上の tmp テーブルにコピーしています
一時的な結果セットが tmp_table_size より大きいため、メモリを節約するために一時テーブルがメモリ ストレージからディスク ストレージに変換されています。
Creating tmp table
クエリ結果を保存するために一時テーブルを作成しています。
deleting from main table
サーバーは複数テーブルdeleteの最初の部分を実行中で、最初のテーブルが削除されたところです。
参照テーブルからの削除
サーバーは複数テーブルの削除の 2 番目の部分を実行しており、他のテーブルからレコードを削除しています。
Flushing tables
FLUSH TABLES を実行し、他のスレッドがデータ テーブルを閉じるのを待ちます。
強制終了
強制終了リクエストがスレッドに送信されると、スレッドは強制終了フラグをチェックし、次の強制終了リクエストを放棄します。 MySQL は各メイン ループ で kill フラグをチェックしますが、場合によっては、スレッドが短期間で終了する可能性があります。スレッドが別のスレッドによってロックされている場合、kill リクエストはロックが解放されるとすぐに有効になります。
ロック
他のクエリによりロックされています。
データの送信
SELECT クエリのレコードが処理され、結果がクライアントに送信されます。
Sorting for group
は GROUP BY でソートしています。
order
の並び替え ORDER BYの並び替え。
テーブルを開く
このプロセスは、他の要因によって妨げられない限り、迅速に行われます。たとえば、ALTER TABLE または LOCK TABLE ステートメントが実行されるまで、他のスレッドでデータ テーブルを開くことはできません。テーブルを開こうとしています。
重複の削除
SELECT DISTINCT クエリが実行されていますが、MySQL は前の段階でそれらの重複レコードを最適化できません。したがって、MySQL は結果をクライアントに送信する前に重複レコードを再度削除する必要があります。
テーブルの再オープン
テーブルのロックは取得されていますが、テーブルの構造が変更されるまでロックは取得できません。ロックが解放され、データ テーブルが閉じられ、データ テーブルを再度オープンしようとしました。
ソートによる修復
修復指示はインデックスを作成するためのソートです。
keycacheによる修復 修復命令はインデックス
キャッシュを利用して新しいインデックスを一つずつ作成しています。ソートによる修復よりも遅くなります。 up
dateの行を検索中
updateの条件を満たすレコードを検索しています。 UPDATE が関連レコードを変更する前に完了する必要があります。 Sleeping
は、クライアントが新しいリクエストを送信するのを待機しています。
システム ロック
は、外部システム ロックを取得するのを待機しています。現在、同じテーブルを同時にリクエストする複数の mysqld サーバーを実行していない場合は、 --skip-external-locking パラメーターを追加して外部システム ロックを無効にすることができます。
ロックのアップグレード
INSERT DELAYED は、新しいレコードを挿入するためにロック テーブルを取得しようとしています。
更新
とは、一致するレコードを
検索し、それらを変更することです。
GET_LOCK()を待っています。
テーブルを待機中
このスレッドは、データ テーブルの構造が変更されたため、新しい構造を取得するにはデータ テーブルを再度開く必要があることが通知されます。次に、データ テーブルを再度開くには、他のすべてのスレッドがテーブルを閉じるまで待つ必要があります。この通知は、FLUSH TABLES tbl_name、ALTER TABLE、RENAME TABLE、REPAIR TABLE、ANALYZE TABLE、または OPTIMIZE TABLE の状況で生成されます。
waiting for han
dler insert INSERT DELAYED は保留中の挿入操作をすべて処理し、新しいリクエストを待機しています。
ほとんどの状態は非常に高速な操作に対応します。1 つのスレッドが数秒間同じ状態にある限り、問題がある可能性があるため、確認する必要があります。
上記にリストされていない他のステータスもありますが、それらのほとんどはサーバーにエラーがあるかどうかを確認するためにのみ役立ちます。
たとえば、図に示すように:
explain select surname,first_name form a,b where a.id=b.id

EXPLAIN 列の説明
table データを表示しますこの行はどのテーブルに関するものですか type これは、接続に使用されるタイプを示す重要な列です。結合タイプは最良のものから順に const、eq_reg、ref、range、indexhe であり、ALL
possible_keysはこのテーブルに適用できるインデックスを示します。空の場合、インデックスは作成できません。関連するドメインの WHERE ステートメントから適切なステートメントを選択できますkey実際に使用されるインデックス。 key_len によって使用されるインデックスの長さを無視させることができます。精度を失うことなく、長さが短いほど優れています ref インデックスのどの列が使用されているかを示します。可能であれば、定数を示します rowsMYSQL は、要求されたデータを返すためにチェックする必要があるとみなします 行数 追加 MYSQL がクエリを解析する方法に関する追加情報。表 4.3 で説明しますが、ここで見られる悪い例は一時的な使用とファイルソートの使用です。つまり、MYSQL はインデックスをまったく使用できず、その結果、取得が非常に遅くなります追加の列によって返される説明
Distinct MYSQL が行結合に一致する行を見つけると、それ以上検索しません 存在しませんMYSQL は、一致する行を見つけるとLEFT JOIN を最適化しますLEFT JOIN 基準、もう検索しません
各Record(index map:#) の範囲をチェックします 理想的なインデックスが見つからないため、前のテーブルの行の組み合わせごとに、MYSQL はどれをチェックしますかインデックスが使用されており、それを使用してテーブルから返すことができます。これは、インデックスを使用した接続の中で最も遅い接続の 1 つです
ファイルソートの使用
これが表示された場合は、クエリを最適化する必要があります。 MYSQL では、返された行をソートする方法を見つけるために追加の手順が必要です。結合タイプとソートキー値を格納する行ポインターに基づいてすべての行をソートし、条件に一致するすべての行をソートします
インデックスの使用
実際のデータを読み取らずにインデックス内の情報のみを使用するテーブルから列データが返されます。アクション、これは、テーブルの要求されたすべての列が同じインデックスの一部である場合に発生します
一時的な使用
これが表示された場合、クエリを最適化する必要があります。ここで、MYSQL は結果を保存するための一時テーブルを作成する必要があります。これは、通常、GROUP BY の代わりに ORDER BY が実行されるときに発生します。
Where 句を使用して、比較される行を制限します。次のテーブル ユーザーに一致するか、またはユーザーに戻ります。これは、テーブル内のすべての行を返す必要がなく、結合タイプが ALL またはインデックスである場合、またはクエリに問題がある場合に発生する可能性があります (効率の順に並べ替えられた)
const。
テーブル内のレコード このクエリに一致する最大値 (インデックスは主キーまたは一意のインデックスにすることができます)。行が 1 つしかないため、この値は実際には定数です。MYSQL は最初にこの値を読み取り、次にそれを定数として扱うからです
eq_ref
接続では、MYSQL がクエリを実行するときに、前のテーブルの各レコードを結合します。テーブルからのレコード。クエリがすべてのインデックスを主キーまたは一意キーとして使用する場合に使用されます
ref
この結合タイプは、クエリが一意キーまたは主キーではないキーを使用する場合にのみ使用されます。またはこれらのタイプの一部 (左端のプレフィックスを使用する場合に発生する など)。前のテーブルの行結合ごとに、すべてのレコードがテーブルから読み取られます。このタイプは、インデックスに基づいて一致するレコードの数に大きく依存します。少ないほど良いです
範囲
この結合タイプは、> または < を使用して何かを検索する場合と同様に、インデックスを使用して範囲内の行を返します。
index
この接続タイプは、前のテーブルの各レコード結合の完全なスキャンを実行します (通常、インデックスはテーブルのデータより小さいため、ALL よりも優れています)
ALL
この接続タイプは、それぞれのレコード結合の完全なスキャンを実行します以前のレコードの結合。これは一般に悪化するため、できるだけ避ける必要があります
MySQL - 遅い SQL を確認する MySQL が遅い SQL ログ ファイルを表示できるかどうかを確認します(1) 遅い SQL ログが有効になっているかどうかを確認します
mysql> show variables like 'log_slow_queries'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | log_slow_queries | ON | +------------------+-------+ 1 row in set (0.00 sec)
(2) 查看执行慢于多少秒的SQL会记录到日志文件中
mysql> show variables like 'long_query_time'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | long_query_time | 1 | +-----------------+-------+ 1 row in set (0.00 sec)
这里value=1, 表示1秒
2. 配置my.ini文件(inux下文件名为my.cnf), 查找到[mysqld]区段,增加日志的配置,如下示例:
[mysqld]
log="C:/temp/mysql.log"
log_slow_queries="C:/temp/mysql_slow.log"
long_query_time=1
log指示日志文件存放目录;
log_slow_queries指示记录执行时间长的sql日志目录;
long_query_time指示多长时间算是执行时间长,单位s。
Linux下这些配置项应该已经存在,只是被注释掉了,可以去掉注释。但直接添加配置项也OK啦。
查询到效率低的 SQL 语句 后,可以通过 EXPLAIN 或者 DESC 命令获取 MySQL 如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序,比如我们想计算 2006 年所有公司的销售额,需要关联 sales 表和 company 表,并且对 profit 字段做求和( sum )操作,相应 SQL 的执行计划如下:
mysql> explain select sum(profit) from sales a,company b where a.company_id = b.id and a.year = 2006\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: a type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 12 Extra: Using where *************************** 2. row *************************** id: 1 select_type: SIMPLE table: b type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 12 Extra: Using where 2 rows in set (0.00 sec)
每个列的解释如下:
•select_type :表示 SELECT 的 类型,常见的取值有 SIMPLE (简单表,即不使用表连接或者子查询)、 PRIMARY (主查询,即外层的查询)、 UNION ( UNION 中的第二个或者后面的查询语句)、 SUBQUERY (子查询中的第一个 SELECT )等。
•table :输出结果集的表。
•type :表示表的连接类型,性能由好到差的连接类型为 system (表中仅有一行,即常量表)、 const (单表中最多有一个匹配行,例如 primary key 或者 unique index )、 eq_ref (对于前面的每一行,在此表中只查询一条记录,简单来说,就是多表连接中使用 primary key 或者 unique index )、 ref (与 eq_ref 类似,区别在于不是使用 primary key 或者 unique index ,而是使用普通的索引)、 ref_or_null ( 与 ref 类似,区别在于条件中包含对 NULL 的查询 ) 、 index_merge ( 索引合并优化 ) 、 unique_subquery ( in 的后面是一个查询主键字段的子查询)、 index_subquery ( 与 unique_subquery 类似,区别在于 in 的后面是查询非唯一索引字段的子查询)、 range (单表中的范围查询)、 index (对于前面的每一行,都通过查询索引来得到数据)、 all (对于前面的每一行,都通过全表扫描来得到数据)。
•possible_keys :表示查询时,可能使用的索引。
•key :表示实际使用的索引。
•key_len :索引字段的长度。
•rows :扫描行的数量。
•Extra :执行情况的说明和描述。
在上面的例子中,已经可以确认是 对 a 表的全表扫描导致效率的不理想,那么 对 a 表的 year 字段创建索引,具体如下:
mysql> create index idx_sales_year on sales(year);
Query OK, 12 rows affected (0.01 sec)
Records: 12 Duplicates: 0 Warnings: 0
创建索引后,这条语句的执行计划如下:
mysql> explain select sum(profit) from sales a,company b where a.company_id = b.id and a.year = 2006\G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: a type: ref possible_keys: idx_sales_year key: idx_sales_year key_len: 4 ref: const rows: 3 Extra: *************************** 2. row *************************** id: 1 select_type: SIMPLE table: b type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 12 Extra: Using where 2 rows in set (0.00 sec)
可以发现建立索引后对 a 表需要扫描的行数明显减少(从全表扫描减少到 3 行),可见索引的使用可以大大提高数据库的访问速度,尤其在表很庞大的时候这种优势更为明显,使用索引优化 sql 是优化问题 sql 的一种常用基本方法,在后面的章节中我们会具体介绍如何使索引来优化 sql 。
本文主要介绍的是MySQL慢查询分析方法,前一段日子,我曾经设置了一次记录在MySQL数据库中对慢于1秒钟的SQL语句进行查询。想起来有几个十分设置的方法,有几个参数的名称死活回忆不起来了,于是重新整理一下,自己做个笔记。
对于排查问题找出性能瓶颈来说,最容易发现并解决的问题就是MySQL慢查询以及没有得用索引的查询。
OK,开始找出MySQL中执行起来不“爽”的SQL语句吧。
MySQL慢查询分析方法一:
这个方法我正在用,呵呵,比较喜欢这种即时性的。
MySQL5.0以上的版本可以支持将执行比较慢的SQL语句记录下来。
MySQL> show variables like 'long%';
注:这个long_query_time是用来定义慢于多少秒的才算“慢查询”
+-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+ 1 row in set (0.00 sec) MySQL> set long_query_time=1; 注: 我设置了1, 也就是执行时间超过1秒的都算慢查询。 Query OK, 0 rows affected (0.00 sec) MySQL> show variables like 'slow%'; +---------------------+---------------+ | Variable_name | Value | +---------------------+---------------+ | slow_launch_time | 2 | | slow_query_log | ON | 注:是否打开日志记录 | slow_query_log_file | /tmp/slow.log | 注: 设置到什么位置 +---------------------+---------------+ 3 rows in set (0.00 sec) MySQL> set global slow_query_log='ON'
注:打开日志记录
一旦slow_query_log变量被设置为ON,MySQL会立即开始记录。
/etc/my.cnf 里面可以设置上面MySQL全局变量的初始值。
long_query_time=1 slow_query_log_file=/tmp/slow.log
MySQL慢查询分析方法二:
MySQLdumpslow命令
/path/MySQLdumpslow -s c -t 10 /tmp/slow-log
这会输出记录次数最多的10条SQL语句,其中:
-s, 是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar,表示相应的倒叙;
-t, 是top n的意思,即为返回前面多少条的数据;
-g, 后边可以写一个正则匹配模式,大小写不敏感的;
比如
/path/MySQLdumpslow -s r -t 10 /tmp/slow-log
得到返回记录集最多的10个查询。
/path/MySQLdumpslow -s t -t 10 -g “left join” /tmp/slow-log
得到按照时间排序的前10条里面含有左连接的查询语句。
简单点的方法:
打开 my.ini ,找到 [mysqld] 在其下面添加 long_query_time = 2 log-slow-queries = D:/mysql/logs/slow.log #设置把日志写在那里,可以为空,系统会给一个缺省的文件 #log-slow-queries = /var/youpath/slow.log linux下host_name-slow.log log-queries-not-using-indexes long_query_time 是指执行超过多长时间(单位是秒)的sql会被记录下来,这里设置的是2秒。
以下是mysqldumpslow常用参数说明,详细的可应用mysqldumpslow -help查询。 -s,是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序(从大到小),ac、at、al、ar表示相应的倒叙。 -t,是top n的意思,即为返回前面多少条数据。 www.jb51.net -g,后边可以写一个正则匹配模式,大小写不敏感。 接下来就是用mysql自带的慢查询工具mysqldumpslow分析了(mysql的bin目录下 ),我这里的日志文件名字是host-slow.log。 列出记录次数最多的10个sql语句 mysqldumpslow -s c -t 10 host-slow.log 列出返回记录集最多的10个sql语句 mysqldumpslow -s r -t 10 host-slow.log 按照时间返回前10条里面含有左连接的sql语句 mysqldumpslow -s t -t 10 -g "left join" host-slow.log 使用mysqldumpslow命令可以非常明确的得到各种我们需要的查询语句,对MySQL查询语句的监控、分析、优化起到非常大的帮助
在日常开发当中,经常会遇到页面打开速度极慢的情况,通过排除,确定了,是数据库的影响,为了迅速查找具体的SQL,可以通过Mysql的日志记录方法。
-- 打开sql执行记录功能
set global log_output='TABLE'; -- 输出到表
set global log=ON; -- 打开所有命令执行记录功能general_log, 所有语句: 成功和未成功的.
set global log_slow_queries=ON; -- 打开慢查询sql记录slow_log, 执行成功的: 慢查询语句和未使用索引的语句
set global long_query_time=0.1; -- 慢查询时间限制(秒)
set global log_queries_not_using_indexes=ON; -- 记录未使用索引的sql语句
-- 查询sql执行记录
select * from mysql.slow_log order by 1; -- 执行成功的:慢查询语句,和未使用索引的语句
select * from mysql.general_log order by 1; -- 所有语句: 成功和未成功的.
-- 关闭sql执行记录
set global log=OFF;
set global log_slow_queries=OFF;
-- long_query_time参数说明
-- v4.0, 4.1, 5.0, v5.1 到 5.1.20(包括):不支持毫秒级别的慢查询分析(支持精度为1-10秒);
-- 5.1.21及以后版本 :支持毫秒级别的慢查询分析, 如0.1;
-- 6.0 到 6.0.3: 不支持毫秒级别的慢查询分析(支持精度为1-10秒);
-- 6.0.4及以后:支持毫秒级别的慢查询分析;
通过日志中记录的Sql,迅速定位到具体的文件,优化sql看一下,是否速度提升了呢?
本文针对MySQL数据库服务器查询逐渐变慢的问题, 进行分析,并提出相应的解决办法,具体的分析解决办法如下:会经常发现开发人员查一下没用索引的语句或者没有limit n的语句,这些没语句会对数据库造成很大的影...
本文针对MySQL数据库服务器查询逐渐变慢的问题, 进行分析,并提出相应的解决办法,具体的分析解决办法如下:
会经常发现开发人员查一下没用索引的语句或者没有limit n的语句,这些没语句会对数据库造成很大的影响,例如一个几千万条记录的大表要全部扫描,或者是不停的做filesort,对数据库和服务器造成io影响等。这是镜像库上面的情况。
而到了线上库,除了出现没有索引的语句,没有用limit的语句,还多了一个情况,mysql连接数过多的问题。说到这里,先来看看以前我们的监控做法
1. 部署zabbix等开源分布式监控系统,获取每天的数据库的io,cpu,连接数
2. 部署每周性能统计,包含数据增加量,iostat,vmstat,datasize的情况
3. Mysql slowlog收集,列出top 10
以前以为做了这些监控已经是很完美了,现在部署了mysql节点进程监控之后,才发现很多弊端
第一种做法的弊端: zabbix太庞大,而且不是在mysql内部做的监控,很多数据不是非常准备,现在一般都是用来查阅历史的数据情况
第二种做法的弊端:因为是每周只跑一次,很多情况没法发现和报警
第三种做法的弊端: 当节点的slowlog非常多的时候,top10就变得没意义了,而且很多时候会给出那些是一定要跑的定期任务语句给你。。参考的价值不大
那么我们怎么来解决和查询这些问题呢
对于排查问题找出性能瓶颈来说,最容易发现并解决的问题就是MYSQL的慢查询以及没有得用索引的查询。
OK,开始找出mysql中执行起来不“爽”的SQL语句吧。
方法一: 这个方法我正在用,呵呵,比较喜欢这种即时性的。
Mysql5.0以上的版本可以支持将执行比较慢的SQL语句记录下来。
mysql> show variables like 'long%'; 注:这个long_query_time是用来定义慢于多少秒的才算“慢查询”
+-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+ 1 row in set (0.00 sec) mysql> set long_query_time=1; 注: 我设置了1, 也就是执行时间超过1秒的都算慢查询。 Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'slow%'; +---------------------+---------------+ | Variable_name | Value | +---------------------+---------------+ | slow_launch_time | 2 | | slow_query_log | ON | 注:是否打开日志记录 | slow_query_log_file | /tmp/slow.log | 注: 设置到什么位置 +---------------------+---------------+ 3 rows in set (0.00 sec)
mysql> set global slow_query_log='ON' 注:打开日志记录
一旦slow_query_log变量被设置为ON,mysql会立即开始记录。
/etc/my.cnf 里面可以设置上面MYSQL全局变量的初始值。
long_query_time=1
slow_query_log_file=/tmp/slow.log
方法二:mysqldumpslow命令
/path/mysqldumpslow -s c -t 10 /tmp/slow-log
这会输出记录次数最多的10条SQL语句,其中:
-s, 是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar,表示相应的倒叙;
-t, 是top n的意思,即为返回前面多少条的数据;
-g, 后边可以写一个正则匹配模式,大小写不敏感的;
比如
/path/mysqldumpslow -s r -t 10 /tmp/slow-log
得到返回记录集最多的10个查询。
/path/mysqldumpslow -s t -t 10 -g “left join” /tmp/slow-log
得到按照时间排序的前10条里面含有左连接的查询语句。
最后总结一下节点监控的好处
1. 轻量级的监控,而且是实时的,还可以根据实际的情况来定制和修改
2. 设置了过滤程序,可以对那些一定要跑的语句进行过滤
3. 及时发现那些没有用索引,或者是不合法的查询,虽然这很耗时去处理那些慢语句,但这样可以避免数据库挂掉,还是值得的
4. 在数据库出现连接数过多的时候,程序会自动保存当前数据库的processlist,DBA进行原因查找的时候这可是利器
5. 使用mysqlbinlog 来分析的时候,可以得到明确的数据库状态异常的时间段
有些人会建义我们来做mysql配置文件设置
调节tmp_table_size 的时候发现另外一些参数
Qcache_queries_in_cache 在缓存中已注册的查询数目
Qcache_inserts 被加入到缓存中的查询数目
Qcache_hits 缓存采样数数目
Qcache_lowmem_prunes 因为缺少内存而被从缓存中删除的查询数目
Qcache_not_cached 没有被缓存的查询数目 (不能被缓存的,或由于 QUERY_CACHE_TYPE)
Qcache_free_memory 查询缓存的空闲内存总数
Qcache_free_blocks 查询缓存中的空闲内存块的数目
Qcache_total_blocks 查询缓存中的块的总数目
Qcache_free_memory 可以缓存一些常用的查询,如果是常用的sql会被装载到内存。那样会增加数据库访问速度
以上がMySQL で遅い SQL ステートメントを見つける方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



