

http プロトコルは、インターネットで最も重要かつ基本的なプロトコルの 1 つであり、当社のクローラーは頻繁に http プロトコルを処理する必要があります。以下の記事では主に Python の入門と HTTP プロトコルについて詳しく紹介していますので、必要な方はぜひ参考にしてください。
はじめに
クローラーの基本原理は、ブラウザーをシミュレートして HTTP リクエストを行うことです。 HTTP プロトコルを理解することが、クローラーを作成するために必要な基礎です。求人 Web サイトのクローラーの立場にも明記されています。 HTTP プロトコルの仕様に習熟し、クローラーを作成する必要があります。まず HTTP プロトコルから始める必要があります
HTTP プロトコルとは何ですか?
閲覧するすべての Web ページは、HTTP プロトコルに基づいて表示されます。HTTP プロトコルは、インターネット アプリケーションにおけるクライアント (ブラウザ) とサーバー間のデータ通信用のプロトコルです。このプロトコルは、クライアントがサーバーに要求を送信する形式を規定し、サーバーから返される応答の形式も規定します。
誰もがプロトコルに従ってリクエストを開始し、応答結果を返す限り、誰でも HTTP プロトコルに基づいて独自の Web クライアント (ブラウザ、クローラー) と Web サーバー (Nginx、Apache など) を実装できます。
HTTP プロトコル自体は非常に単純です。クライアントはリクエストをアクティブに開始することのみが可能であり、サーバーはリクエストを受信して処理した後に応答結果を返すことが規定されています。同時に、HTTP は状態プロトコルであり、プロトコル自体はクライアントの履歴を記録しません。リクエストレコード。

HTTPプロトコルはリクエスト形式とレスポンス形式をどのように指定しますか?言い換えれば、クライアントはどの形式で HTTP リクエストを正しく開始できるでしょうか?クライアントが正しく解析できるように、サーバーは応答結果をどの形式で返しますか?
HTTP リクエスト
HTTP リクエストは、リクエスト行、リクエストヘッダー、リクエストボディの 3 つの部分グループで構成されています。ヘッダーとリクエスト本文はオプションであり、すべてのリクエストに必要なわけではありません。

リクエストライン
リクエストラインは、リクエストメソッド(メソッド)、リクエストURL(URI)、HTTPプロトコルバージョンの3つの部分で構成されます。スペースで区切ります。
HTTP プロトコルで最も一般的に使用されるリクエスト メソッドは、GET、POST、PUT、DELETE です。 GET メソッドはサーバーからリソースを取得するために使用され、クローラの 90% は GET リクエストに基づいてデータをクロールします。
リクエスト URL は、リソースが配置されているサーバーのパス アドレスを指します。たとえば、上記の例は、クライアントがリソースindex.html を取得したいことを示しており、そのパスはルート ディレクトリ (/) の下にあります。サーバー foofish.net。リクエストヘッダー
リクエストラインによって運ばれる情報の量は非常に限られているため、クライアントはサーバーに対して多くのことを伝える必要があり、それをリクエストヘッダー(ヘッダー)に含める必要があります。リクエスト ヘッダーは次の情報を提供するために使用されます。サーバーは、クライアントの ID を示すために使用されるユーザー エージェントなどの追加情報を提供します。これにより、リクエストがブラウザーからのものなのか、クローラーからのものなのか、Chrome ブラウザーからのものなのか、またはクローラーからのものなのかをサーバーに知らせます。ファイアフォックス。 HTTP/1.1 では 47 のヘッダー フィールド タイプが指定されています。 HTTP ヘッダー フィールドの形式は Python の辞書タイプに非常に似ており、コロンで区切られたキーと値のペアで構成されます。例:User-Agent: Mozilla/5.0
リクエストボディ
リクエストボディは、ユーザーがログインするときに必要なユーザー名とパスワード、ファイルアップロードデータ、フォーム情報など、クライアントによってサーバーに送信される実際のコンテンツです。ユーザー情報登録時に提出していただきます。 ここで、Python が提供するオリジナルの API ソケット モジュールを使用して、サーバーへの HTTP リクエストをシミュレートしますwith socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
# 1. 与服务器建立连接
s.connect(("www.seriot.ch", 80))
# 2. 构建请求行,请求资源是 index.php
request_line = b"GET /index.php HTTP/1.1"
# 3. 构建请求首部,指定主机名
headers = b"Host: seriot.ch"
# 4. 用空行标记请求首部的结束位置
blank_line = b"\r\n"
# 请求行、首部、空行这3部分内容用换行符分隔,组成一个请求报文字符串
# 发送给服务器
message = b"\r\n".join([request_line, headers, blank_line])
s.send(message)
# 服务器返回的响应内容稍后进行分析
response = s.recv(1024)
print(response)HTTP レスポンス
サーバーはリクエストを受信して処理した後、レスポンスの内容をクライアントに返します同様に、ブラウザが正しく解析するには、応答コンテンツも固定形式に従う必要があります。 HTTP 応答も、HTTP 要求形式に対応する、応答行、応答ヘッダー、応答本文の 3 つの部分で構成されます。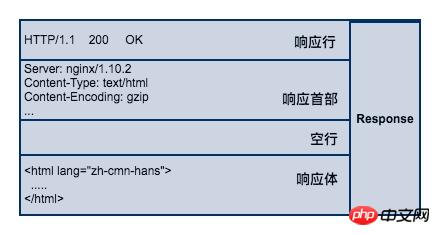
响应行
响应行同样也是3部分组成,由服务端支持的 HTTP 协议版本号、状态码、以及对状态码的简短原因描述组成。
状态码是响应行中很重要的一个字段。通过状态码,客户端可以知道服务器是否正常处理的请求。如果状态码是200,说明客户端的请求处理成功,如果是500,说明服务器处理请求的时候出现了异常。404 表示请求的资源在服务器找不到。除此之外,HTTP 协议还很定义了很多其他的状态码,不过它不是本文的讨论范围。
响应首部
响应首部和请求首部类似,用于对响应内容的补充,在首部里面可以告知客户端响应体的数据类型是什么?响应内容返回的时间是什么时候,响应体是否压缩了,响应体最后一次修改的时间。
响应体
响应体(body)是服务器返回的真正内容,它可以是一个HTML页面,或者是一张图片、一段视频等等。
我们继续沿用前面那个例子来看看服务器返回的响应结果是什么?因为我只接收了前1024个字节,所以有一部分响应内容是看不到的。
b'HTTP/1.1 200 OK\r\n Date: Tue, 04 Apr 2017 16:22:35 GMT\r\n Server: Apache\r\n Expires: Thu, 19 Nov 1981 08:52:00 GMT\r\n Set-Cookie: PHPSESSID=66bea0a1f7cb572584745f9ce6984b7e; path=/\r\n Transfer-Encoding: chunked\r\n Content-Type: text/html; charset=UTF-8\r\n\r\n118d\r\n <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">\n\n <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">\n <head>\n\t <meta http-equiv="Content-Type" content="text/html;charset=iso-8859-1" /> \n\t <meta http-equiv="content-language" content="en" />\n\t ... </html>
从结果来看,它与协议中规范的格式是一样的,第一行是响应行,状态码是200,表明请求成功。第二部分是响应首部信息,由多个首部组成,有服务器返回响应的时间,Cookie信息等等。第三部分就是真正的响应体 HTML 文本。
至此,你应该对 HTTP 协议有一个总体的认识了,爬虫的行为本质上就是模拟浏览器发送HTTP请求,所以要想在爬虫领域深耕细作,理解 HTTP 协议是必须的。
【相关推荐】
1. python爬虫入门(4)--详解HTML文本的解析库BeautifulSoup
2. python爬虫入门(3)--利用requests构建知乎API
3. python爬虫入门(2)--HTTP库requests
以上がPython クローラー入門 (1) - HTTP プロトコルをすぐに理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



