

クロール処理中、一部のページはログイン前のクロールが禁止されています。このとき、ログインをシミュレートする必要があります。次の記事では主にPythonクローラーを使用してZhihuログインをシミュレートする方法についてのチュートリアルを紹介します。紹介記事はとても詳しく書かれていますので、必要な方は参考にしてください。以下を見てみましょう。
はじめに
クローラーを頻繁に作成する人なら誰でも、一部のページではログイン前のクロールが禁止されていることを知っています。たとえば、Zhihu のトピック ページにはアクセスするためにログインが必要であり、「ログイン」は Cookie と切り離せないものです。 HTTP のテクノロジー。
ログイン原理
Cookie の原理は非常に単純です。HTTP はステートレス プロトコルであるため、ステートレス HTTP プロトコル上で セッション 状態を維持するために、サーバーに現在の状態を知らせます。 Cookie テクノロジーは、サーバーがクライアントに割り当てる識別子に相当します。
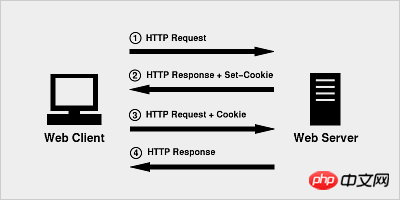
ブラウザが初めてHTTPリクエストを開始するとき、Cookie情報は含まれません
サーバーはHTTPレスポンスとCookie情報で応答し、それを一緒にブラウザに返します
ブラウザ No. 2 番目のリクエストでは、サーバーから返された Cookie 情報が一緒にサーバーに送信され、サーバーが HTTP リクエストを受信し、リクエスト ヘッダーに Cookie フィールドがあることを検出します。以前にこのユーザーと取引しました。
Zhihuを使用したことのある人なら誰でも、ログインするにはユーザー名、パスワード、確認コードを入力するだけでよいことを知っています。もちろん、これは私たちが見ているものにすぎません。背後に隠された技術的な詳細は、ブラウザを使用して確認する必要があります。ここで Chrome を使用して、フォームに記入した後に何が起こったのかを確認します。
(すでにログインしている場合は、まずログアウトしてください) まず、Zhihu ログイン ページ www.zhihu.com/#signin に入り、Chrome 開発者ツールバーを開き (F12 キーを押します)、まず間違った確認コードを入力してみてくださいそしてブラウザがどのようにリクエストを送信するかを観察します。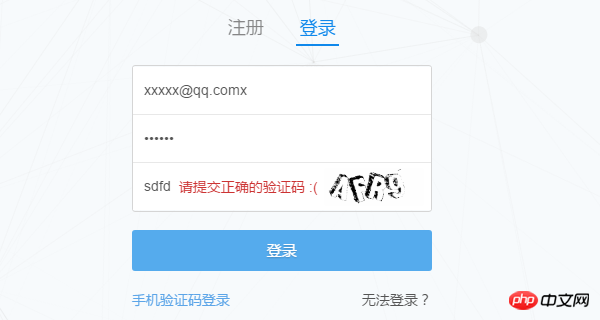
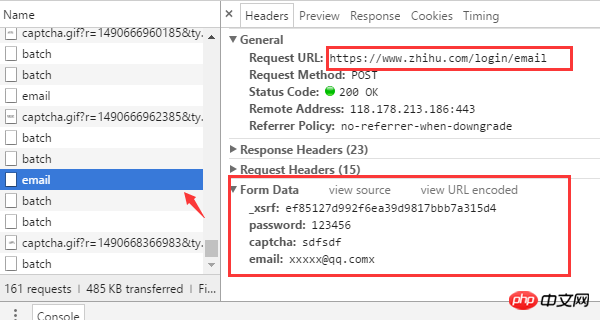
ログイン URL アドレスは https://www.zhihu.com/login/email です
ログインに必要なフォーム データは 4 です: ユーザー名 (電子メール)、パスワード (パスワード)、確認コード (キャプチャ)、_xsrf。
認証コードを取得するためのURLアドレスは https://www.zhihu.com/captcha.gif?r=1490690391695&type=login
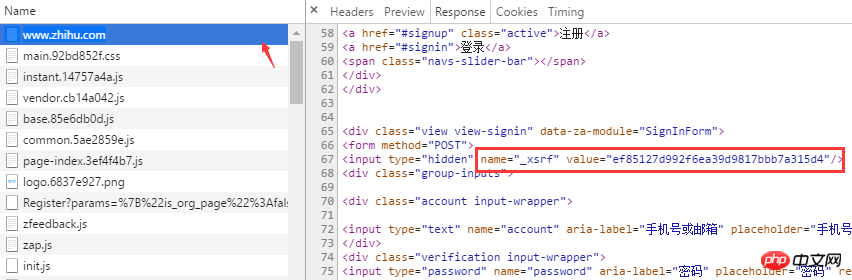
_xsrf とは何ですか? CSRF (クロスサイト リクエスト フォージェリ) 攻撃に精通している場合は、xsrf がクロスサイト リクエスト フォージェリを防ぐために使用される一連の擬似乱数であることを知っておく必要があります。通常、これを確認するには、ページ上で「xsrf」を検索すると、_xsrf が隠れた input タグ内にあり、そのときに必要なデータがわかりました。これを取得した後、Python を使用してブラウザのログインをシミュレートするコードの作成を開始できます。ログイン時に依存する 2 つのサードパーティ ライブラリは、リクエストと BeautifulSoup です。まず、HTTP Cookie の自動処理に使用できる
pip install beautifulsoup4==4.5.3 pip install requests==2.13.0
 最初の実行では Cookie が存在しないため、Cookie 情報をセッション オブジェクトを通じて送信できます。起こる。
最初の実行では Cookie が存在しないため、Cookie 情報をセッション オブジェクトを通じて送信できます。起こる。
from http import cookiejar
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
try:
session.cookies.load(ignore_discard=True)
except LoadError:
print("load cookies failed")xsrfが配置されているタグはすでに見つかりました。BeatifulSoupのfindメソッドを使用すると、非常に簡単に値を取得できます
def get_xsrf():
response = session.get("https://www.zhihu.com", headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
xsrf = soup.find('input', attrs={"name": "_xsrf"}).get("value")
return xsrfりー
ログイン 一切参数准备就绪之后,就可以请求登录接口了。 请求成功后,session 会自动把 服务端的返回的cookie 信息填充到 session.cookies 对象中,下次请求时,客户端就可以自动携带这些cookie去访问那些需要登录的页面了。 auto_login.py 示例代码 【相关推荐】 1. python爬虫入门(4)--详解HTML文本的解析库BeautifulSoup 2. python爬虫入门(3)--利用requests构建知乎API 3. python爬虫入门(2)--HTTP库requests 以上がPython クローラーを使用して Zhihu ログインをシミュレートする例を共有するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。def login(email, password):
login_url = 'www.zhihu.com/login/email'
data = {
'email': email,
'password': password,
'_xsrf': get_xsrf(),
"captcha": get_captcha(),
'remember_me': 'true'}
response = session.post(login_url, data=data, headers=headers)
login_code = response.json()
print(login_code['msg'])
for i in session.cookies:
print(i)
session.cookies.save()# encoding: utf-8
# !/usr/bin/env python
"""
作者:liuzhijun
"""
import time
from http import cookiejar
import requests
from bs4 import BeautifulSoup
headers = {
"Host": "www.zhihu.com",
"Referer": "www.zhihu.com/",
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87'
}
# 使用登录cookie信息
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
try:
print(session.cookies)
session.cookies.load(ignore_discard=True)
except:
print("还没有cookie信息")
def get_xsrf():
response = session.get("www.zhihu.com", headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
xsrf = soup.find('input', attrs={"name": "_xsrf"}).get("value")
return xsrf
def get_captcha():
"""
把验证码图片保存到当前目录,手动识别验证码
:return:
"""
t = str(int(time.time() * 1000))
captcha_url = 'www.zhihu.com/captcha.gif?r=' + t + "&type=login"
r = session.get(captcha_url, headers=headers)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
captcha = input("验证码:")
return captcha
def login(email, password):
login_url = 'www.zhihu.com/login/email'
data = {
'email': email,
'password': password,
'_xsrf': get_xsrf(),
"captcha": get_captcha(),
'remember_me': 'true'}
response = session.post(login_url, data=data, headers=headers)
login_code = response.json()
print(login_code['msg'])
for i in session.cookies:
print(i)
session.cookies.save()
if name == 'main':
email = "xxxx"
password = "xxxxx"
login(email, password)
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



