

MySQLのクエリの最適化について言えば、SELECT *を使用しない、NULLフィールドを使用しない、合理的にインデックスを作成する、フィールドに適切なデータ型を選択するなど、誰もが多くのスキルを蓄積していると思います。 ... . これらの最適化手法を本当に理解していますか?仕組みを理解していますか?実際のシナリオでパフォーマンスは本当に向上しているのでしょうか?私はそうは思わない。したがって、これらの最適化提案の背後にある原則を理解することが特に重要です。この記事を参考にして、これらの最適化提案を再検討し、実際のビジネス シナリオに合理的に適用できるようにしていただければ幸いです。
MySQL のさまざまなコンポーネントがどのように連携して動作するかを頭の中でアーキテクチャ図を構築できれば、MySQL サーバーを深く理解するのに役立ちます。次の図は、MySQL の論理アーキテクチャ図を示しています。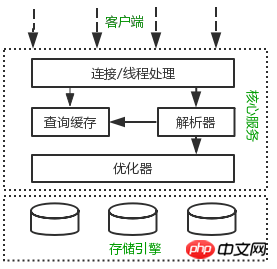
接続処理、認可認証、セキュリティ、その他の機能はすべてこの層で処理されます。
MySQL のコア サービスのほとんどは、クエリ解析、分析、最適化、キャッシュ、組み込み関数 (時間、数学、暗号化など) を含む中間層にあります。 ストアド プロシージャ、トリガー、ビューなどのすべてのクロスストレージ エンジン機能もこのレイヤーに実装されています。
最下層はストレージ エンジンで、MySQL でのデータの保存と取得を担当します。Linux の ファイル システム と同様に、各ストレージ エンジンには長所と短所があります。中間サービス層は、API を通じてストレージ エンジンと通信します。これらの API インターフェイス は、異なるストレージ エンジン間の違いを保護します。
MySQL クエリ プロセス 私たちは常に、MySQL がより高いクエリ パフォーマンスを獲得できることを望んでいます。最良の方法は、MySQL がクエリをどのように最適化して実行するかを理解することです。これを理解すると、多くのクエリ最適化作業は、実際には、MySQL オプティマイザーが期待どおりの合理的な方法で実行できるように、いくつかの原則に従っているだけであることがわかります。 MySQL にリクエストを送信するとき、MySQL は正確に何をしますか?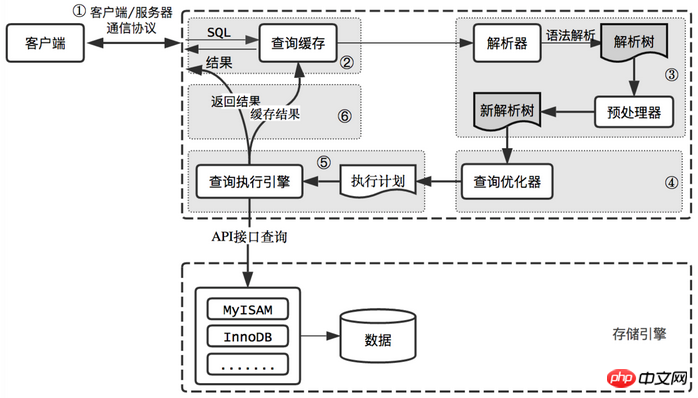
の送信を開始すると、もう一方の端はそれに応答する前にメッセージ全体を受信する必要があるため、メッセージを細かく分割して個別に送信することはできませんし、その必要もなく、制御する方法はありません。流れ。
クライアントはクエリリクエストを別のデータパケットでサーバーに送信するため、クエリステートメントが非常に長い場合は、max_
allowed_packet パラメータを設定する必要があります。ただし、クエリが大きすぎる場合、サーバーはそれ以上のデータの受信を拒否し、例外をスローすることに注意してください。
逆に、サーバーがユーザーに応答するデータは、通常、複数のデータ パケットで構成される大量のデータです。ただし、サーバーがクライアントのリクエストに応答するとき、クライアントは最初のいくつかの結果を取得してサーバーに送信の停止を要求するのではなく、返された結果全体を完全に受信する必要があります。したがって、実際の開発では、クエリをできるだけ単純にして必要なデータのみを返すことが非常に良い習慣であり、通信中のデータ パケットのサイズと数を減らすことが、SELECT の使用を避ける理由でもあります。 * クエリに LIMIT 制限を追加します。
クエリキャッシュ
クエリ キャッシュがオンになっている場合、クエリ ステートメントを解析する前に、MySQL はクエリ ステートメントがクエリ キャッシュ内のデータにヒットするかどうかをチェックします。現在のクエリがクエリ キャッシュにヒットした場合は、ユーザーの権限を一度確認した後、キャッシュ内の結果が直接返されます。この場合、クエリは解析されず、実行プランも生成されず、実行されません。
MySQL は、ハッシュ値インデックスを通じて reference テーブル (テーブルとして理解しないでください。HashMap に似たデータ構造と考えることができます) にキャッシュを保存します。このハッシュ値はクエリ自体を介して渡され、現在クエリ対象のデータベース、クライアント プロトコルのバージョン番号、および結果に影響を与える可能性のあるその他の情報が計算されます。したがって、2 つのクエリ間の文字の違い (例: スペース、コメント) により、キャッシュが失われます。
mysql ライブラリ内のユーザーカスタム関数、ストアド関数、ユーザー変数、一時テーブル、システムテーブルがクエリに含まれている場合、クエリ結果
はキャッシュされません。たとえば、関数 NOW() または CURRENT_DATE() は、クエリ時間が異なるため、異なるクエリ結果を返します。別の例として、CURRENT_USER または CONNECION_ID() を含むクエリ ステートメントは、ユーザーが異なるため、異なる結果が返されます。このようなクエリの結果をキャッシュしても意味がありません。
キャッシュなので期限切れになります クエリキャッシュはいつ期限切れになりますか? MySQL のクエリ キャッシュ システム は、クエリに含まれる各テーブルを追跡します。これらのテーブル (データまたは構造) が変更されると、このテーブルに関連するすべての キャッシュされたデータ が無効になります。このため、MySQL は書き込み操作中に対応するテーブルのすべてのキャッシュを無効にする必要があります。クエリ キャッシュが非常に大きいか断片化している場合、この操作によりシステムが大量に消費され、システムがしばらくフリーズする可能性があります。さらに、システム上のクエリ キャッシュの追加消費は、書き込み操作だけでなく読み取り操作でも発生します。
この SQL ステートメントがキャッシュにヒットしない場合でも、クエリ ステートメントは開始前にチェックする必要があります
クエリ結果をキャッシュできる場合、実行完了後に結果はキャッシュに保存され、追加のシステム消費量も発生します
これに基づいて、クエリのキャッシュは行われないことを知っておく必要があります。キャッシュと無効化により追加の消費がもたらされるのは、キャッシュによって消費されるリソースよりも大きい場合のみです。ただし、キャッシュをオンにすることでパフォーマンスが向上するかどうかを評価するのは非常に困難であり、この記事の範囲を超えています。システムにパフォーマンス上の問題がある場合は、クエリ キャッシュをオンにして、データベース設計を次のように最適化してみてください。
1 つの大きなテーブルを複数の小さなテーブルに置き換えます。設計してください
バッチ挿入で置換ループ単一挿入
キャッシュスペースのサイズを合理的に制御する一般的に、サイズを数十メガバイトに設定することがより適切です
特定のクエリ ステートメントは、SQL_CACHE および SQL_NO_CACHE
を通じてキャッシュする必要があります。最後のアドバイスは、特に書き込み集中型のアプリケーションの場合は、クエリ キャッシュを簡単にオンにしないことです。どうしてもそれができない場合は、query_cache_type を DEMAND に設定すると、SQL_CACHE を追加するクエリのみがキャッシュされ、他のクエリはキャッシュされなくなります。これにより、どのクエリをキャッシュする必要があるかを自由に制御できます。前の手順で生成された構文ツリーは正当であるとみなされ、オプティマイザーによってクエリ プランに変換されます。ほとんどの場合、クエリはさまざまな方法で実行でき、すべてが対応する結果を返します。オプティマイザーの役割は、その中から最適な実行プランを見つけることです。
MySQL はコストベースのオプティマイザーを使用します。これは、特定の実行プランを使用してクエリのコストを予測しようとし、コストが最小のものを選択します。 MySQL では、現在のセッションの last_query_cost の値をクエリすることで、現在のクエリの計算コストを取得できます。 mysql > 'last_query_cost' のようなステータスを表示します
| | 6391.799000 |
+-------- ----------+-------------+
の結果この例は、オプティマイザが上記のクエリを完了するにはデータ ページのランダム検索を約 6391 回行う必要があると考えていることを示しています。この結果は、各テーブルまたはインデックスのページ数、インデックスのカーディナリティ、インデックスとデータ行の長さ、インデックスの分布などの列統計に基づいて計算されます。
MySQL が間違った実行プランを選択する理由は数多くあります。たとえば、不正確な統計情報、管理を超えた運用コスト (ユーザー定義関数、ストアド プロシージャ) を考慮していないこと、MySQL が最適な実行と考えるものなどです。 (実行時間をできるだけ短くしたいが、MySQL はコストが小さいと思われる値を選択しますが、コストが小さいからといって実行時間が短いとは限りません) などなど。
MySQL のクエリ オプティマイザーは非常に複雑なコンポーネントであり、最適な実行プランを生成するために多くの最適化戦略を使用します。
テーブルの関連付け順序を再定義します (複数のテーブルをクエリする場合、必ずしも指定された順序である必要はありません)。 SQL ですが、関連付けの順序を指定するテクニックがいくつかあります)
MIN() 関数と MAX() 関数を最適化します (列の最小値を見つけます。列にインデックスがある場合は、列の左端を見つけるだけです)。 B+Tree インデックス、それ以外の場合は最大値を見つけることができます。特定の原則については以下を参照してください)
クエリを早期に終了します (例: Limit を使用する場合、クエリは条件を満たす結果セットが見つかった直後に終了します)。番号)
最適化されたソート (古いバージョンの MySQL では、2 つの送信ソートが使用されます。つまり、最初に行ポインターとソートが必要なフィールドを読み取り、メモリ内でそれらをソートしてからデータを読み取ります)新しいバージョンでは単一転送ソートが使用されます。つまり、すべてのデータ行を一度に読み取ってから、特定の列に従ってソートするため、I/O 集約型アプリケーションの場合、効率が大幅に向上します。
MySQL の継続的な開発に伴い、オプティマイザーの使用する最適化戦略も常に進化しています。ここでは、非常に一般的に使用される、わかりやすい最適化戦略をいくつか紹介します。他の最適化戦略については、ご自身で確認してください。 。
解析と最適化の段階が完了すると、MySQL は対応する実行プランを生成し、クエリ実行エンジンは実行プランに従って徐々に命令を実行して結果を取得します。実行プロセス全体のほとんどの操作は、ストレージ エンジンによって実装されたインターフェイスを呼び出すことで完了します。これらのインターフェイスは han
dl
クエリ実行の最後の段階は、結果をクライアントに返すことです。データをクエリできない場合でも、MySQL はクエリの影響を受ける行数や実行時間など、クエリに関する関連情報を返します。
クエリ キャッシュがオンになっており、このクエリをキャッシュできる場合、MySQL は結果もキャッシュに保存します。
結果セットをクライアントに返すことは、増分的かつ段階的な返却プロセスです。 MySQL は、最初の結果を生成したときに、徐々に結果セットをクライアントに返し始める可能性があります。このようにして、サーバーはあまりにも多くの結果を保存したり、大量のメモリを消費したりする必要がなく、クライアントも返された結果をできるだけ早く取得できます。なお、結果セットの各行は、①で説明した通信プロトコルに準拠したデータパケットとして送信され、送信処理中にMySQLのデータパケットがキャッシュされて送信される場合があります。バッチ。
MySQL のクエリ実行プロセス全体を要約してみましょう。これは一般に 6 つのステップに分かれています:
クライアントはクエリ リクエストを MySQL サーバーに送信します
サーバーは最初にクエリ キャッシュをチェックし、キャッシュにヒットすると、すぐに返されます。結果はキャッシュに保存されます。それ以外の場合は、次の段階に進みます
サーバーはSQLの解析と前処理を実行し、オプティマイザーが対応する実行プランを生成します
MySQLはストレージエンジンのAPIを呼び出して、実行プランに従ってクエリを実行します
クエリ結果をキャッシュしながら、クライアントに結果を返します
ここまで読んだ後は、いくつかの最適化方法を期待するかもしれません。はい、3 つの異なる最適化提案が以下に示されます。側面。ただし、待ってください。最初にもう 1 つアドバイスがあります。この記事で説明している内容を含め、最適化に関する「絶対的な真実」に耳を傾けるのではなく、実際のビジネス シナリオでの実行の前提条件をテストすることでそれを検証してください。計画と応答時間。
スキーム設計とデータ型の最適化
データ型を選択するときは、小さくてシンプルであるという原則に従ってください。通常、データ型が小さいほど、占有するディスクとメモリが少なくなり、処理に必要な CPU サイクルが少なくなります。たとえば、単純なデータ型は計算中に必要な CPU サイクルが少ないため、IP アドレスの格納には整数が使用され、時刻の格納には 文字列 の代わりに DATETIME が使用されます。
ここでは、理解しやすく間違いやすいヒントをいくつか紹介します:
一般に、NULL 可能な列を NOT NULL に変更してもパフォーマンスはあまり向上しませんが、この列は NOT NULL に設定する必要があります。
INT(11)などの整数型の幅を指定しても役に立ちません。 INT は 16 を記憶領域として使用するため、その表現範囲が決まっており、INT(1) と INT(20) は記憶と計算で同じになります。
UNSIGNED は、負の値が許可されていないことを意味し、正の数の上限の約 2 倍になる可能性があります。たとえば、TINYINT の記憶範囲は一般的に言えば、DECIMAL データ型を使用する必要はありません。財務データを保存する必要がある場合でも、BIGINT を使用できます。たとえば、1 万分の 1 まで正確にする必要がある場合は、データを 100 万倍し、TIMESTAMP を使用して 4 バイトの記憶域スペースを使用し、DATETIME を使用して 8 バイトの記憶域スペースを使用できます。したがって、TIMESTAMP は 1970 から 2038 までしか表現できませんが、これは DATETIME よりもはるかに狭い範囲であり、TIMESTAMP の値はタイム ゾーンによって異なります。
ほとんどの場合、列挙型を使用する必要はありません。欠点の 1 つは、列挙型の文字列リスト (列挙型オプション) の追加と削除には ALTER TABLE を使用する必要があることです (要素を追加する場合のみ)。テーブルを再構築せずにリストの最後まで)。
結果操作を実行します。新しいテーブルを作成してから、古いテーブルを削除します。特にメモリが不足していて、テーブルが大きく、インデックスが大きい場合は時間がかかります。もちろん、この問題を解決できる奇妙で卑劣なテクニックがいくつかあります。興味があれば、自分で調べてみてください。
インデックスは MySQL クエリのパフォーマンスを向上させる重要な方法ですが、インデックスが多すぎると、過剰なディスク使用量と過剰なメモリ使用量が発生し、アプリケーションの全体的なパフォーマンスに影響を与える可能性があります。後で問題を特定するために大量の SQL を監視する必要があり、インデックスを追加する時間は最初にインデックスを追加するのに必要な時間よりも明らかに長いため、後からインデックスを追加することは避けてください。インデックスの追加も非常に技術的であることがわかります。
以下では、高パフォーマンスのインデックスを作成するための一連の戦略と、各戦略の背後にある動作原理を示します。ただし、その前に、インデックス作成に関連するいくつかのアルゴリズムとデータ構造を理解しておくと、次の内容をよりよく理解できるようになります。
インデックス関連のデータ構造とアルゴリズム
通常、インデックスと呼ばれるものは、リレーショナル データベース でデータを検索するために現在最も一般的に使用され、効果的なインデックスである B ツリー インデックスを指します。 B-Tree という用語が使用されるのは、MySQL が CREATE TABLE またはその他のステートメントでこのキーワードを使用するためですが、実際には、異なるストレージ エンジンが異なるデータ構造を使用する可能性があります。たとえば、InnoDB は B+Tree を使用します。
B+TreeのBはバランス、つまりバランスを意味します。 B+ ツリー インデックスは、指定されたキー値を持つ特定の行を見つけることができないことに注意してください。検索対象のデータ行が存在するページのみが検索され、データベースはそのページをメモリに読み込んで検索します。メモリを取得し、最後に探しているデータを取得します。
B+Tree を紹介する前に、まず二分探索ツリーについて理解しましょう。これは、左側のサブツリーの値が常にルートの値より小さく、右側のサブツリーの値が常に小さくなります。ルートより大きい値は下図①の通りです。このレッスン ツリーで値 5 のレコードを検索する場合の一般的なプロセスは次のとおりです。まず、値が 6 (5 より大きい) であるルートを検索します。そのため、左側のサブツリーを検索して 3 を検索します。5 は次のとおりです。 3 より大きい場合は、3 Tree の正しいサブツリーを見つけます。合計 3 回見つけました。同様に、値が 8 のレコードを検索する場合も 3 回検索する必要があります。したがって、二分探索ツリーの平均検索回数は、(3 + 3 + 3 + 2 + 2 + 1) / 6 = 2.3 回になります。順次検索すると、値 2 のレコードを見つけるのに必要な回数は 1 回だけになります。ただし、検索値が 8 レコードの場合は 6 回必要なので、順次検索の平均検索回数は次のようになります: (1 + 2 + 3 + 4 + 5 + 6) / 6 = 3.3 回。これは、ほとんどの場合、平均検索速度が二分探索木は逐次探索の方が高速です。
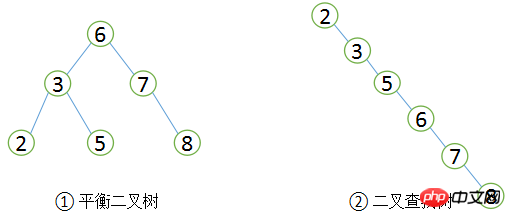
二分探索木と平衡二分木
二分探索木は同じ値で任意に構築できるので、当然、図②のような二分探索木を構築することができます。このバイナリ ツリーのクエリ効率は、順次検索の場合と同様です。二分検索数に対して最高のクエリ パフォーマンスが必要な場合は、二分検索ツリーのバランスが取れている、つまりバランス二分ツリー (AVL ツリー) が必要です。
バランスの取れた二分木は、まず二分探索木の定義に準拠する必要があり、次に、どのノードの 2 つのサブツリー間の高さの差も 1 を超えてはいけないという条件を満たす必要があります。明らかに、図②は平衡二分木の定義を満たしていませんが、図①は平衡二分木です。バランスの取れたバイナリ ツリーの検索パフォーマンスは比較的高くなります (クエリのパフォーマンスが優れているほど、メンテナンス コストも高くなります)。たとえば、図 1 のバランスの取れたバイナリ ツリーで、ユーザーが値 9 の新しいノードを挿入する必要がある場合、次の変更を行う必要があります。
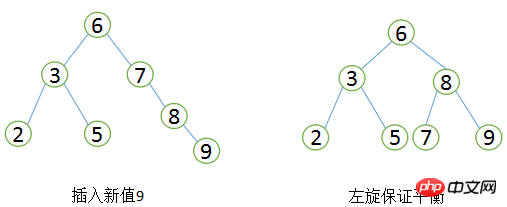
バランスのとれたバイナリ ツリーの回転
これは、左回転操作を通じて挿入されたツリーをバランスのとれたバイナリ ツリーに戻す最も単純なケースです。実際のアプリケーション シナリオでは、複数の回転が行われる場合があります。必須。この時点で、バランスのとれたバイナリ ツリーの検索効率は非常に優れており、実装は非常に簡単で、それに対応するメンテナンス コストは許容範囲内ですが、なぜ
MySQL Indexはバランスのとれたバイナリ ツリーを直接使用しないのでしょうか?
データベース内のデータが増加するにつれて、インデックス自体のサイズも増加し、すべてをメモリに保存することは不可能であるため、インデックスはインデックス ファイルの形式でディスクに保存されることがよくあります。この場合、インデックス検索プロセス中にディスク I/O 消費が発生し、メモリ アクセスに比べて I/O アクセスの消費量が数桁多くなります。何百万ものノードを持つバイナリ ツリーの深さを想像できますか?このような深い深さのバイナリ ツリーがディスク上に配置されている場合、ノードが読み取られるたびにディスクからの I/O 読み取りが必要となり、全体の検索時間は明らかに許容範囲外になります。では、検索プロセス中の I/O アクセスの数を減らすにはどうすればよいでしょうか?
効果的な解決策は、ツリーの深さを減らし、二分木を m 分木 (多方向
searchツリー) に変えることであり、B+Tree は多方向検索ツリーです。 B+Tree を理解する際に必要なのは、その 2 つの最も重要な機能だけです。まず、すべてのキーワード (データとして理解できる) はリーフ ノード (リーフ ページ) に保存され、非リーフ ノード (インデックス ページ) は保存されません。実データが格納され、すべてのレコード ノードがキー値の順にリーフ ノードの同じ層に格納されます。次に、すべてのリーフ ノードがポインタによって接続されます。下の図は、高さ 2 の簡略化された B+Tree を示しています。
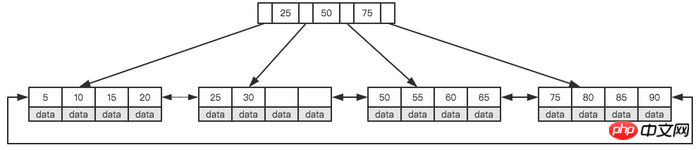
簡略化されたB+ツリー
これら 2 つの特徴を理解するにはどうすればよいですか? MySQL は、各ノードのサイズをページの整数倍に設定します (理由は後述します)。つまり、ノード領域のサイズが確実である場合、各ノードはより多くの内部ノードを格納できるため、各ノードの範囲は次のとおりです。インデックスはより大きく、より正確です。すべてのリーフ ノードにポインタ リンクを使用する利点は、間隔アクセスが可能であることです。たとえば、上の図で、20 より大きく 30 未満のレコードを検索する場合、ノード 20 を見つけるだけで済みます。ポインタをたどって、25 と 30 を順番に見つけます。リンクポインタが存在しない場合、区間検索はできません。これは、MySQL がインデックス ストレージ構造として B+Tree を使用する重要な理由でもあります。
MySQL がノード サイズをページの整数倍に設定する理由には、ディスクのストレージ原理を理解する必要があります。ディスク自体のアクセス速度は、機械的な動作損失に加えて、メイン メモリのアクセス速度の 100 万分の 1 であることがよくあります。ディスク I/O を最小限に抑えるために、ディスクは厳密にオンデマンドで読み取られないことがよくありますが、たとえ 1 バイトしか必要とされない場合でも、ディスクはこの位置から開始され、一定の長さのデータが順番に読み取られます。プリリードの長さは、通常はページの整数倍です。
引用
ページは、コンピューターが管理するメモリの論理ブロックであり、多くの場合、メイン メモリとディスク ストレージ領域を同じサイズの連続したブロックに分割します (多くの OS では、そのサイズがページです)。ページ (通常は 4K)。メインメモリとディスクはページ単位でデータをやり取りします。プログラムによって読み取られるデータがメインメモリにない場合、ページフォールト例外がトリガーされ、システムはディスクに読み取り信号を送信し、ディスクはデータの開始位置を見つけます。 1 つまたは複数のページを逆方向に読み取ってメモリにロードすると、異常終了し、プログラムは実行を続けます。
MySQL はディスク先読みの原理を巧みに利用してノードのサイズを 1 ページに等しく設定するため、各ノードが完全にロードされるために必要な I/O は 1 つだけです。この目標を達成するために、新しいノードが作成されるたびに、ページのスペースが直接適用され、ノードがページに物理的に格納されるようになり、コンピュータのストレージ割り当てがページに合わせて配置されます。ノードの読み取りに必要な I/O は 1 つだけです。 B+Tree の高さが h であると仮定すると、取得には最大でも h-1I/O (ルート ノードの常駐メモリ) と計算量 $O(h) = O(log_{M}N)$ が必要です。実際のアプリケーション シナリオでは、M は通常大きく、100 を超えることがよくあるため、ツリーの高さは一般に低く、通常は 3 以下です。
最後に、B+Tree ノードの操作を簡単に理解して、インデックスのメンテナンスについて一般的に理解しましょう。インデックスはクエリ効率を大幅に向上させますが、それでもインデックスの維持には多額のコストがかかります。インデックスの作成は特に重要です。
上記のツリーを例として取り上げますが、各ノードは 4 つの内部ノードのみを格納できると仮定します。まず、次の図に示すように、最初のノード 28 を挿入します。
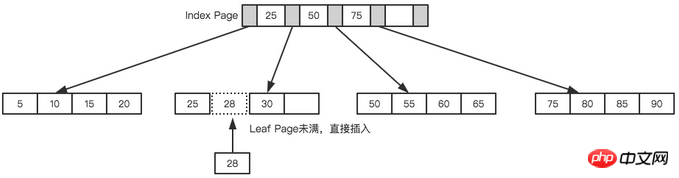
リーフ ページもインデックス ページもいっぱいではありません
次に、次のノード 70 を挿入します。インデックス ページをクエリした後、リーフ ノードは 50 と 70 の間に挿入する必要があることがわかりました。ただし、リーフ ノードはいっぱいです。この時点で、リーフ ノードの現在の開始点は 50 であるため、次の図に示すように、リーフ ノードは中間値に基づいて分割されます。
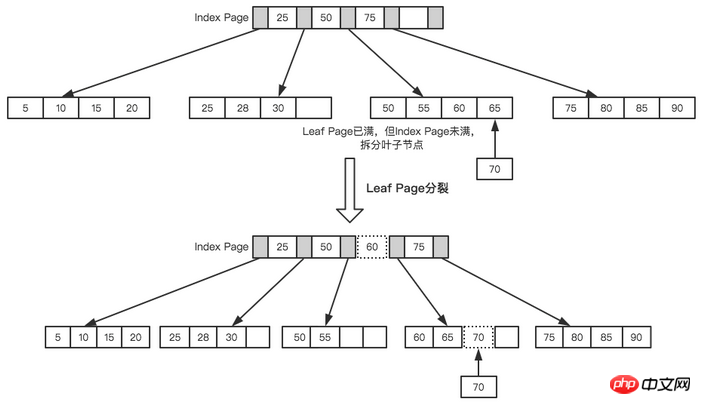
リーフページの分割
最後に、ノード 95 が挿入されます。この時点では、インデックス ページとリーフ ページがいっぱいであるため、次の図に示すように 2 つの分割が必要です。
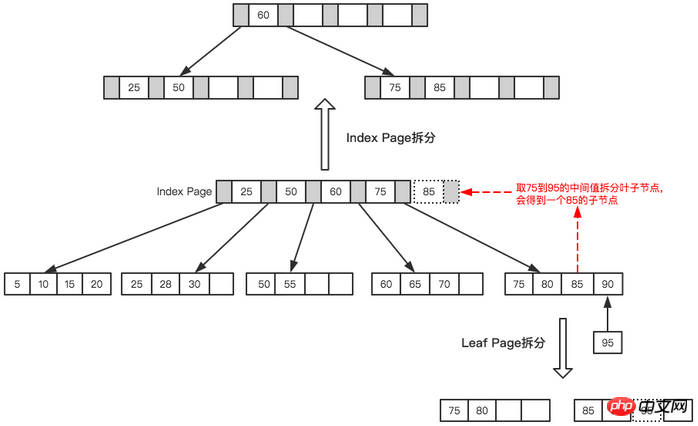
リーフページとインデックスページが分割されます
分割後、最終的にこのようなツリーが形成されます。
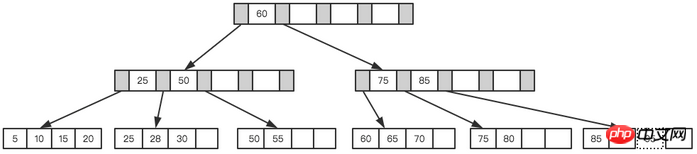
最終ツリー
B+ツリー バランスを維持するには、新しく挿入された値に対して多数の分割 ページング 操作が必要であり、ページ分割には I/O 操作が必要です。ページ分割操作を最大限に削減するために、B+Tree はバランスの取れたバイナリ ツリーと同様の回転機能も提供します。 LeafPage がいっぱいでも、その左右の兄弟ノードがいっぱいではない場合、B+Tree は分割操作を実行しようとはせず、レコードを現在のページの兄弟ノードに移動します。通常、ローテーション操作については、最初に左の兄弟がチェックされます。たとえば、上記の 2 番目の例では、70 を挿入すると、ページ分割は実行されず、左回転操作が実行されます。
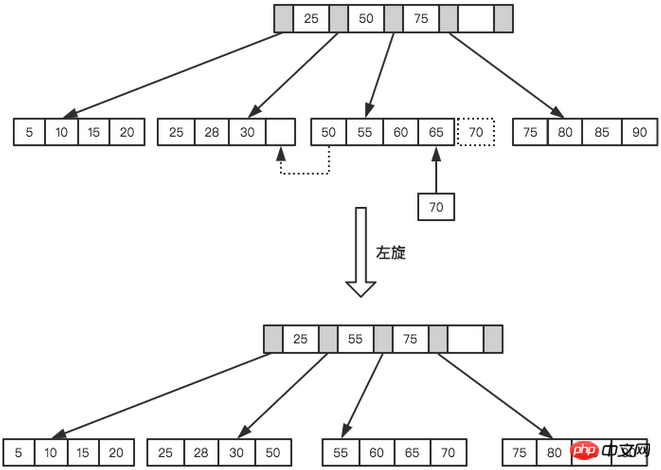
左回転操作
ローテーション操作により、ページ分割を最小限に抑えることができ、それによりインデックス保守プロセス中のディスク I/O 操作が削減され、インデックス保守効率も向上します。ノードの削除とノード タイプの挿入には回転と分割の操作が必要であることに注意してください。これについてはここでは説明しません。
ハイパフォーマンス戦略
上記を通じて、B+Tree のデータ構造については大体理解できたと思いますが、MySQL のインデックスはデータのストレージをどのように編成するのでしょうか?簡単な例で説明すると、次のデータ テーブルがあるとします。
Mysql コード
CREATE TABLE People(
last_name varchar(50) not null,
first_name varchar(5 0) not null、
生年月日が null ではない、
性別 enum(`m`,`f`) が null ではない、
key(last_name,first_name,dob)
);

式 の一部にすることも、関数のパラメータにすることもできないことを意味します。例:
Mysql コード2. プレフィックスインデックス
列が非常に長い場合は、通常、先頭に一部の文字にインデックスを付けることができます。これにより、インデックススペースが効果的に節約され、インデックス作成の効率が向上します。
3. 複数列のインデックスとインデックスの順序
ほとんどの場合、複数の列に独立したインデックスを確立してもクエリのパフォーマンスは向上しません。理由は非常に単純です。MySQL はクエリ効率を向上させるためにどのインデックスを選択すればよいかを認識していないため、MySQL 5.0 より前の古いバージョンではカラムのインデックスをランダムに選択しますが、新しいバージョンではマージされたインデックス戦略が採用されます。簡単な例を挙げると、映画のキャスト リストでは、actor_id 列と film_id 列に独立したインデックスが確立され、次のクエリがあります:
Mysql コード
MySQL の古いバージョンではインデックスがランダムに選択されますが、新しいバージョンでは次の最適化が行われます:
Mysql コード
インデックスがデータ ストレージをどのように編成するかについては前述しました。図からわかるように、複数列インデックスを使用する場合、インデックスの順序がクエリにとって重要であることは明らかです。インデックスの前に配置されると、条件を満たさないほとんどのデータは最初のフィールドで除外できます。
引用
インデックスの選択性とは、データ テーブル内のレコードの総数に対する一意のインデックス値の比率を指します。選択性が高いほど、クエリの効率が高くなります。これは、インデックスの選択性が高いほど、クエリ時に MySQL がより多くの行を除外できるためです。ユニークなインデックスの選択性は 1 です。このとき、インデックスの選択性は最高であり、パフォーマンスも最高です。
インデックスの選択性の概念を理解した後は、次のようにチェックするだけで、どのフィールドがより選択的であるかを判断するのは難しくありません。 customer_id = 584 (staff_id, customer_id) のインデックスを作成する必要がありますか、それとも順序を逆にする必要がありますか?次のクエリを実行します。選択度が 1 に近いフィールドが最初にインデックス付けされます。
Mysqlコード
select
countcount(個別のcustomer_id)/count(*)をcustomer_id_selectivityとして、
MySQL は、このクエリはインデックス (user_group_id, trade_amount) を選択します。特別な状況を考慮しなければ、これで問題はないようですが、実際には、このテーブルのデータのほとんどが から移行されています。新しいシステムと古いシステムの違いにより、データに互換性がなかったため、古いシステムから移行されたデータにはデフォルトのユーザー グループが割り当てられました。この場合、インデックスによってスキャンされる行数は基本的にテーブル全体のスキャンの場合と同じであり、インデックスは何の役割も果たしません。
一般的に言えば、経験則と推論はほとんどの場合に役立ち、開発と設計の指針となりますが、実際の状況はより複雑であることが多く、実際のビジネス シナリオにおける特殊な状況によっては設計全体が破壊される可能性があります。
4. 複数の範囲条件を避ける
インデックスの列順序が ORDER BY 句の順序と完全に一致し、すべての列の並べ替え方向も同じ場合にのみ、インデックスを使用して結果を並べ替えることができます。クエリで複数のテーブルを関連付ける必要がある場合、ORDER BY 句で参照されるすべてのフィールドが最初のテーブルのものである場合にのみ、インデックスを並べ替えに使用できます。 ORDER BY 句とクエリの制限は同じで、左端のプレフィックスの要件を満たす必要があります (例外が 1 つあり、左端の列が定数として指定されます。以下は簡単な例です)。それ以外の場合は、ソート操作を実行する必要があり、インデックスソートは使用できません。
Mysql コード
//左端の列は定数、インデックス: (date,staff_id,customer_id)
select Staff_id,customer_id from Demon where date = '2015-06-01' order by Staff_id, customer_id
7. 冗長なインデックスと重複したインデックス
冗長なインデックスとは、同じ列に同じ順序で作成された同じ種類のインデックスを指します。そのようなインデックスは可能な限り回避し、検出後すぐに削除する必要があります。たとえば、インデックス (A、B) がある場合、インデックス (A) を作成すると冗長インデックスになります。冗長インデックスは、テーブルに新しいインデックスを追加するときによく発生します。たとえば、新しいインデックス (A、B) を作成しますが、このインデックスは既存のインデックス (A) を拡張しません。
ほとんどの場合、新しいインデックスを作成するのではなく、既存のインデックスを拡張するようにしてください。ただし、既存のインデックスを拡張して大きくなりすぎて、そのインデックスを使用する他のクエリに影響を与えるなど、パフォーマンスを考慮して冗長インデックスが必要になるケースがまれにあります。
8. 長期間使用されていないインデックスを削除する
長期間使用されていないインデックスを定期的に削除することは、非常に良い習慣です。
最後に、インデックス作成が常に最良のツールであるとは限らないことを言いたいと思います。それは効果的です。非常に小さいテーブルの場合は、単純な全テーブル スキャンの方が効率的です。中規模から大規模のテーブルの場合、インデックスは非常に効果的です。非常に大きなテーブルの場合、インデックスの作成と維持のコストが増加するため、パーティション化されたテーブルなどの他の手法の方が効果的である可能性があります。最後に、テストを受ける前に説明するのは美徳です。
特定型クエリの最適化
COUNT() クエリの最適化
COUNT() は、2 つの異なる関数があります。1 つは、特定の列内の値の数をカウントすることです。もう 1 つは、特定の列の値の数をカウントすることです。2 つ目は、行の数をカウントすることです。列の値をカウントする場合、列の値は NULL 以外である必要があり、NULL はカウントされません。括弧内の式を空にすることができないことを確認すると、実際には行数がカウントされています。最も単純なことは、COUNT(*) を使用すると、想像したようにすべての列に展開されず、実際にはすべての列が無視され、すべての行が直接カウントされることです。
最も一般的な誤解はここにあり、かっこで列を指定しているにもかかわらず、統計結果が行数になることを期待しており、前者のパフォーマンスが優れていると誤って信じていることがよくあります。しかし、実際にはそうではありません。行数をカウントしたい場合は、COUNT(*) を直接使用してください。その方が意味が明確で、パフォーマンスも向上します。
場合によっては、完全に正確な COUNT 値を必要とせず、EXPLAIN の行数が適切な近似値で置き換えられる場合があり、EXPLAIN の実行には実際にクエリを実行する必要がないため、コストがかかります。とても低い。一般に、COUNT() を実行すると、正確なデータを取得するために多数の行をスキャンする必要があるため、MySQL レベルで実行できるのはインデックスをカバーすることだけです。問題を解決できない場合は、概要テーブルを追加するか、redis などの外部キャッシュ システムを使用するなど、アーキテクチャ レベルでのみ解決できます。
関連クエリを最適化する
ビッグ データ シナリオでは、テーブルは冗長フィールドを通じて関連付けられ、JOIN を直接使用するよりもパフォーマンスが向上します。関連クエリを本当に使用する必要がある場合は、次の点に特別な注意を払う必要があります:
ON 句と USING 句の列にインデックスがあることを確認してください。インデックスを作成するときは、関連付けの順序を考慮する必要があります。テーブル A とテーブル B が列 c を使用して関連付けられている場合、オプティマイザの関連付け順序が A、B であれば、テーブル A の対応する列にインデックスを作成する必要はありません。一般的に、他の理由がない限り、関連シーケンスの 2 番目のテーブルの対応する列にインデックスを作成するだけで済みます (具体的な理由は以下で分析されます)。
MySQL が最適化のためにインデックスを使用できるように、GROUP BY と ORDER BY の式には 1 つのテーブル内の列のみが含まれるようにしてください。
関連クエリを最適化する最初のヒントを理解するには、MySQL が関連クエリをどのように実行するかを理解する必要があります。現在の MySQL アソシエーション実行戦略は非常に単純です。これは、あらゆるアソシエーションに対してネストされたループ アソシエーション操作を実行します。つまり、最初にテーブル内の 1 つのデータをループアウトし、次にネストされたループ内の次のテーブルで一致する行を検索します。など、一致する動作がすべてのテーブルで見つかるまで続きます。次に、各テーブルの一致する行に基づいて、クエリに必要な列が返されます。
抽象的すぎますか?たとえば、上記の例を見て、次のようなクエリがあることを示します。 A. xx IN (5,6)
MySQL がクエリ内の関連付け順序 A および B に従って関連付け操作を実行すると仮定すると、次の疑似コードを使用して、MySQL がこのクエリを完了する方法を表すことができます。
MySQL コードouter_iterator = SELECT A.xx,A.c FROM A WHERE A.xx IN (5,6); (外側の行) {
SET
の使用を回避できます。次のクエリ: Mysql コードSELECT id FROM t LIMIT 10000, 10;
SELECT id FROM t WHERE id > 10000 LIMIT 10; に変更されます。その他の最適化方法には、事前に計算された要約テーブルの使用や、主キー列と並べ替えが必要な列のみを含む冗長テーブルへのリンクなどがあります。
UNION の最適化
UNION を処理するための MySQL の戦略は、最初に一時テーブルを作成し、次に各クエリ結果を一時テーブルに挿入し、最後にクエリを実行することです。したがって、多くの最適化戦略は UNION クエリ ではうまく機能しません。多くの場合、オプティマイザーがこれらの条件を最大限に活用して最初に最適化できるように、WHERE、LIMIT、ORDER BY およびその他の句を各サブクエリに手動で「プッシュ ダウン」する必要があります。
サーバーの重複排除が本当に必要な場合を除き、UNION ALL を使用する必要があります。ALL キーワードがない場合、MySQL は一時テーブルに DISTINCT オプションを追加します。これにより、一時テーブル全体のデータが一意になります。これを実行してください。コストが非常に高くなります。もちろん、ALL キーワードが使用されている場合でも、MySQL は常に結果を一時テーブルに格納し、それを読み取ってクライアントに返します。多くの場合、これは必要ありませんが、たとえば、各サブクエリの結果をクライアントに直接返すことができる場合があります。
結論
最適化プロセスの知識と組み合わせて、クエリがどのように実行されるか、どこに時間がかかるかを理解すると、誰もが MySQL をより深く理解し、一般的な最適化手法の背後にある原則を理解するのに役立ちます。この記事の原則と例が、理論と実践をより適切に結びつけ、より多くの理論的知識を実践に適用するのに役立つことを願っています。
他に言うことはありません。これについては頭の中でよく考えてください。しかし、その理由を考える人はほとんどいません。
共有するときにこの観点を放棄するプログラマはたくさんいます: ストアド プロシージャを使用しないようにしてください。ストアド プロシージャは保守が非常に難しく、使用コストも増加します。クライアント。クライアントはこれらのことを実行できるのに、なぜストアド プロシージャが必要なのでしょうか?
以上がMySQL 最適化の原則の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



