

Javaでバッファソースコードを解析する

この記事は主にJavaのバッファソースコードの解析に関する関連情報を紹介します。必要な方は
Javaのバッファソースコードの解析
バッファ
バッファのクラス図は次のとおりです。 :
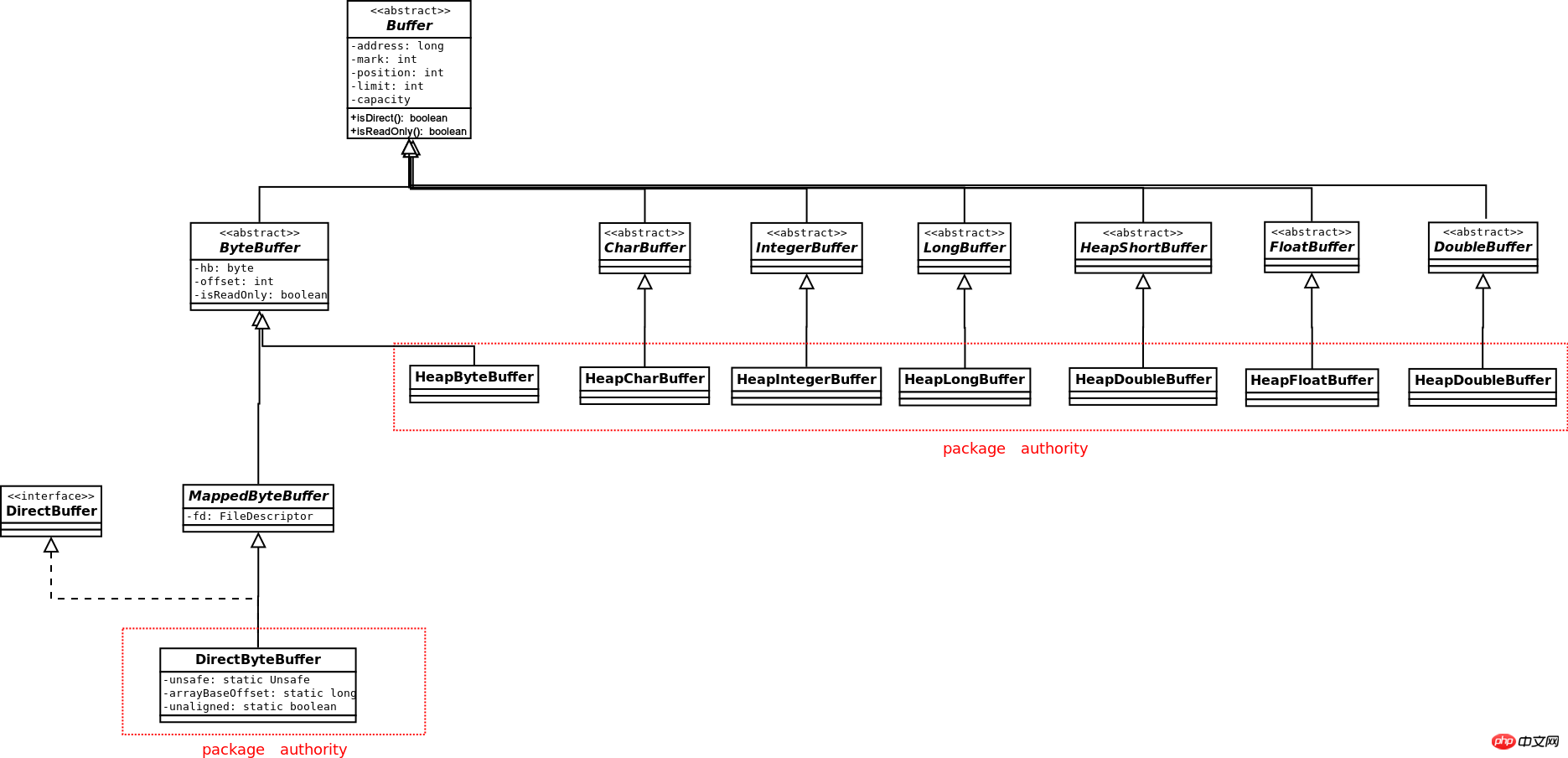
ブール型を除き、他の基本的な データ型 には対応するバッファーがありますが、チャネルと対話できるのは ByteBuffer のみです。 ByteBuffer のみがダイレクト バッファを生成でき、他のデータ型のバッファはヒープ タイプのバッファのみを生成できます。 ByteBuffer は、他のデータ型のビュー バッファを生成できます。ByteBuffer 自体が Direct である場合、生成される各ビュー バッファも Direct です。
ダイレクトおよびヒープタイプのバッファの本質
最初の選択肢は、JVM が IO 操作を実行する方法について説明することです。
JVM は、オペレーティング システム コールを通じて IO 操作を完了する必要があります。たとえば、読み取りシステム コールを通じてファイルの読み取りを完了できます。 read のプロトタイプは次のとおりです: ssize_t read(int fd, void *buf, size_t nbytes) は、他の IO システム コールと同様に、通常、パラメーターの 1 つとしてバッファーを必要とし、バッファーは連続している必要があります。
バッファは、ダイレクトとヒープの 2 つのカテゴリに分類されます。これらの 2 つのタイプのバッファについては、以下で説明します。
ヒープ
ヒープタイプ バッファはJVMヒープ上に存在します。メモリのこの部分のリサイクルと配置は通常のオブジェクトと同じです。ヒープ タイプのバッファ オブジェクトにはすべて、基本データ タイプ (たとえば、final **[] hb) に対応する配列属性が含まれており、その配列はヒープ タイプ バッファの基礎となるバッファです。
ただし、主に以下の 2 つの理由により、Heap 型 Buffer をシステムコールのバッファパラメータとして直接使用することはできません。
JVM は GC 中にバッファを移動 (コピー整理) する場合があり、バッファのアドレスは固定されていません。
システムコールを行うとき、バッファーは連続的である必要がありますが、配列は連続的でなくても構いません (JVM 実装では連続的である必要はありません)。
そのため、IO にヒープ タイプのバッファを使用する場合、JVM は一時的なダイレクト タイプのバッファを生成し、データをコピーして、オペレーティング システム呼び出しを行うためのパラメータとして一時的なダイレクトの
バッファを使用する必要があります。これは、主に次の 2 つの理由により、効率が非常に低くなります:
データをヒープ タイプのバッファから一時的に作成されたダイレクト バッファにコピーする必要がある。
は大量の Buffer オブジェクトを生成するため、GC の頻度が増加する可能性があります。したがって、IO 操作中に、バッファを再利用することで最適化を実行できます。
Direct
ダイレクト型バッファはヒープ上には存在しませんが、JVMによってmallocを通じて直接割り当てられる連続メモリです。メモリのこの部分はダイレクトメモリとなり、JVMが作成時に使用します。 IO システムコール。バッファとしてメモリを直接呼び出します。
-XX:MaxDirectMemorySize、この構成を通じて、割り当て可能な最大直接メモリ サイズを設定できます (MappedByteBuffer によって割り当てられたメモリは、この構成の影響を受けません)。
ダイレクト メモリのリサイクルは、ヒープ メモリのリサイクルとは異なります。ダイレクト メモリが不適切に使用されると、OutOfMemoryError が発生しやすくなります。 Java には、直接メモリをアクティブに解放するための明示的なメソッドが用意されていません。sun.misc.Unsafe クラスは、基礎となる直接メモリ操作を実行でき、このクラスを通じてダイレクト メモリをアクティブに解放および管理できます。同様に、効率を向上させるためにダイレクト メモリを再利用する必要があります。
MappedByteBuffer と DirectByteBuffer の関係
これは少し逆です: 権利上、MappedByteBuffer は DirectByteBuffer のサブクラスである必要がありますが、仕様を明確かつシンプルに保つため、また最適化の目的からは、逆の方法で行う方が簡単です。これは、DirectByteBuffer がパッケージのプライベート クラスであるため機能します (この段落は MappedByteBuffer のソース コードから引用しています)
実際、MappedByteBuffer はマップされたバッファーですが (仮想メモリを自分で見てください)、DirectByteBuffer はそれを示すだけです。メモリのこの部分は、JVM によって直接メモリ領域に割り当てられた連続バッファが常にマップされるわけではありません。つまり、MappedByteBuffer は DirectByteBuffer のサブクラスである必要がありますが、利便性と最適化のために、MappedByteBuffer は DirectByteBuffer の親クラスとして使用されます。さらに、MappedByteBuffer は論理的に DirectByteBuffer のサブクラスである必要があり、MappedByteBuffer メモリの GC はダイレクト メモリの GC と似ていますが (ヒープ GC とは異なります)、割り当てられた MappedByteBuffer のサイズは -XX:MaxDirectMemorySize の影響を受けません。パラメータ。
MappedByteBuffer はメモリ マップされたファイル操作をカプセル化します。つまり、ファイル IO 操作のみを実行できます。 MappedByteBuffer は、mmap に基づいて生成されたマッピング バッファです。バッファのこの部分は、対応するファイル ページにマッピングされ、ユーザー モードでは直接メモリに属し、MappedByteBuffer を通じて直接操作できます。ファイル ページでは、オペレーティング システムは、対応するメモリ ページを呼び出したり呼び出したりすることによって、ファイルの書き込みと書き込みを完了します。
MappedByteBuffer
FileChannel.map(MapModeモード、longposition、longsize)を通じてMappedByteBufferを取得します。MappedByteBufferの生成処理をソースコードとともに説明します。
FileChannel.mapのソースコード:
public MappedByteBuffer map(MapMode mode, long position, long size)
throws IOException
{
ensureOpen();
if (position < 0L)
throw new IllegalArgumentException("Negative position");
if (size < 0L)
throw new IllegalArgumentException("Negative size");
if (position + size < 0)
throw new IllegalArgumentException("Position + size overflow");
//最大2G
if (size > Integer.MAX_VALUE)
throw new IllegalArgumentException("Size exceeds Integer.MAX_VALUE");
int imode = -1;
if (mode == MapMode.READ_ONLY)
imode = MAP_RO;
else if (mode == MapMode.READ_WRITE)
imode = MAP_RW;
else if (mode == MapMode.PRIVATE)
imode = MAP_PV;
assert (imode >= 0);
if ((mode != MapMode.READ_ONLY) && !writable)
throw new NonWritableChannelException();
if (!readable)
throw new NonReadableChannelException();
long addr = -1;
int ti = -1;
try {
begin();
ti = threads.add();
if (!isOpen())
return null;
//size()返回实际的文件大小
//如果实际文件大小不符合,则增大文件的大小,文件的大小被改变,文件增大的部分默认设置为0。
if (size() < position + size) { // Extend file size
if (!writable) {
throw new IOException("Channel not open for writing " +
"- cannot extend file to required size");
}
int rv;
do {
//增大文件的大小
rv = nd.truncate(fd, position + size);
} while ((rv == IOStatus.INTERRUPTED) && isOpen());
}
//如果要求映射的文件大小为0,则不调用操作系统的mmap调用,只是生成一个空间容量为0的DirectByteBuffer
//并返回
if (size == 0) {
addr = 0;
// a valid file descriptor is not required
FileDescriptor dummy = new FileDescriptor();
if ((!writable) || (imode == MAP_RO))
return Util.newMappedByteBufferR(0, 0, dummy, null);
else
return Util.newMappedByteBuffer(0, 0, dummy, null);
}
//allocationGranularity的大小在我的系统上是4K
//页对齐,pagePosition为第多少页
int pagePosition = (int)(position % allocationGranularity);
//从页的最开始映射
long mapPosition = position - pagePosition;
//因为从页的最开始映射,增大映射空间
long mapSize = size + pagePosition;
try {
// If no exception was thrown from map0, the address is valid
//native方法,源代码在openjdk/jdk/src/solaris/native/sun/nio/ch/FileChannelImpl.c,
//参见下面的说明
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError x) {
// An OutOfMemoryError may indicate that we've exhausted memory
// so force gc and re-attempt map
System.gc();
try {
Thread.sleep(100);
} catch (InterruptedException y) {
Thread.currentThread().interrupt();
}
try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError y) {
// After a second OOME, fail
throw new IOException("Map failed", y);
}
}
// On Windows, and potentially other platforms, we need an open
// file descriptor for some mapping operations.
FileDescriptor mfd;
try {
mfd = nd.duplicateForMapping(fd);
} catch (IOException ioe) {
unmap0(addr, mapSize);
throw ioe;
}
assert (IOStatus.checkAll(addr));
assert (addr % allocationGranularity == 0);
int isize = (int)size;
Unmapper um = new Unmapper(addr, mapSize, isize, mfd);
if ((!writable) || (imode == MAP_RO)) {
return Util.newMappedByteBufferR(isize,
addr + pagePosition,
mfd,
um);
} else {
return Util.newMappedByteBuffer(isize,
addr + pagePosition,
mfd,
um);
}
} finally {
threads.remove(ti);
end(IOStatus.checkAll(addr));
}
}map0のソースコード実装:
JNIEXPORT jlong JNICALL
Java_sun_nio_ch_FileChannelImpl_map0(JNIEnv *env, jobject this,
jint prot, jlong off, jlong len)
{
void *mapAddress = 0;
jobject fdo = (*env)->GetObjectField(env, this, chan_fd);
//linux系统调用是通过整型的文件id引用文件的,这里得到文件id
jint fd = fdval(env, fdo);
int protections = 0;
int flags = 0;
if (prot == sun_nio_ch_FileChannelImpl_MAP_RO) {
protections = PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_RW) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_PV) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_PRIVATE;
}
//这里就是操作系统调用了,mmap64是宏定义,实际最后调用的是mmap
mapAddress = mmap64(
0, /* Let OS decide location */
len, /* Number of bytes to map */
protections, /* File permissions */
flags, /* Changes are shared */
fd, /* File descriptor of mapped file */
off); /* Offset into file */
if (mapAddress == MAP_FAILED) {
if (errno == ENOMEM) {
//如果没有映射成功,直接抛出OutOfMemoryError
JNU_ThrowOutOfMemoryError(env, "Map failed");
return IOS_THROWN;
}
return handle(env, -1, "Map failed");
}
return ((jlong) (unsigned long) mapAddress);
} FileChannel.map()のziseパラメータは長いですが、sizeの最大サイズはIntegerです。 MAX_VALUE 、つまり、最大 2G のスペースのみをマッピングできます。実際、オペレーティング システムによって提供される MMAP はより大きな領域を割り当てることができますが、JAVA は 2G に制限されており、ByteBuffer などのバッファーは最大サイズ 2G のバッファーしか割り当てることができません。
MappedByteBuffer は、mmap を通じて生成されるバッファーです。バッファーのこの部分はオペレーティング システムによって直接作成および管理されます。最後に、JVM により、オペレーティング システムが unmmap を通じてメモリのこの部分を直接解放できます。
Haep****Buffer
以下では、Heap タイプの Buffer の詳細を説明するために ByteBuffer を例に挙げます。
このタイプのバッファは次の方法で生成できます:
ByteBuffer.allocate(int Capacity)
ByteBuffer.wrap(byte[] array) 受信配列を基礎となるバッファとして使用し、配列はバッファに影響し、バッファを変更すると配列にも影響します。
ByteBuffer.wrap(byte[] array, int offset, int length)
受信配列の一部を基礎となるバッファーとして使用します。配列の対応する部分を変更するとバッファーに影響し、バッファーも変更されます。配列にも影響します。
DirectByteBuffer
DirectByteBufferは、ByteBuffer.allocateDirect(int Capacity)によってのみ生成できます。
ByteBuffer.allocateDirect() のソース コードは次のとおりです:
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}DirectByteBuffer() のソース コードは次のとおりです:
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
//直接内存是否要页对齐,我本机测试的不用
boolean pa = VM.isDirectMemoryPageAligned();
//页的大小,本机测试的是4K
int ps = Bits.pageSize();
//如果页对齐,则size的大小是ps+cap,ps是一页,cap也是从新的一页开始,也就是页对齐了
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
//JVM维护所有直接内存的大小,如果已分配的直接内存加上本次要分配的大小超过允许分配的直接内存的最大值会
//引起GC,否则允许分配并把已分配的直接内存总量加上本次分配的大小。如果GC之后,还是超过所允许的最大值,
//则throw new OutOfMemoryError("Direct buffer memory");
Bits.reserveMemory(size, cap);
long base = 0;
try {
//是吧,unsafe可以直接操作底层内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {、
//没有分配成功,把刚刚加上的已分配的直接内存的大小减去。
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}unsafe.allocateMemory() のソース コードは openjdk/src/openjdk/ にありますホットスポット/src/share/vm /prims/unsafe.cpp。具体的なソース コードは次のとおりです。
UNSAFE_ENTRY(jlong, Unsafe_AllocateMemory(JNIEnv *env, jobject unsafe, jlong size))
UnsafeWrapper("Unsafe_AllocateMemory");
size_t sz = (size_t)size;
if (sz != (julong)size || size < 0) {
THROW_0(vmSymbols::java_lang_IllegalArgumentException());
}
if (sz == 0) {
return 0;
}
sz = round_to(sz, HeapWordSize);
//最后调用的是 u_char* ptr = (u_char*)::malloc(size + space_before + space_after),也就是malloc。
void* x = os::malloc(sz, mtInternal);
if (x == NULL) {
THROW_0(vmSymbols::java_lang_OutOfMemoryError());
}
//Copy::fill_to_words((HeapWord*)x, sz / HeapWordSize);
return addr_to_java(x);
UNSAFE_ENDJVM は、malloc を通じて連続バッファを割り当てます。バッファのこの部分は、オペレーティング システム呼び出しのバッファ パラメータとして直接使用できます。
以上がJavaでバッファソースコードを解析するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7476
7476
 15
1377
52
77
11
19
32
15
1377
52
77
11
19
32


 Java の乱数ジェネレーター
Aug 30, 2024 pm 04:27 PM
Java の乱数ジェネレーター
Aug 30, 2024 pm 04:27 PM
Java の乱数ジェネレーターのガイド。ここでは、Java の関数について例を挙げて説明し、2 つの異なるジェネレーターについて例を挙げて説明します。
 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
Java は、初心者と経験豊富な開発者の両方が学習できる人気のあるプログラミング言語です。このチュートリアルは基本的な概念から始まり、高度なトピックに進みます。 Java Development Kit をインストールしたら、簡単な「Hello, World!」プログラムを作成してプログラミングを練習できます。コードを理解したら、コマンド プロンプトを使用してプログラムをコンパイルして実行すると、コンソールに「Hello, World!」と出力されます。 Java の学習はプログラミングの旅の始まりであり、習熟が深まるにつれて、より複雑なアプリケーションを作成できるようになります。
