

MySQL での圧縮の使用シナリオとソリューション

データ分散特性により、保存されるデータの繰り返し率が高いほど圧縮率が高くなります。通常、文字型データ (CHAR、VARCHAR、TEXT、または BLOB) の方が高い圧縮率を持ちます。一方、一部のバイナリ データや既に圧縮されているデータの圧縮率はあまり良くありません
はじめに
圧縮転送プロトコル、圧縮列ソリューション、圧縮テーブル ソリューションなど、MySQL 圧縮の使用シナリオとソリューションについて説明します。
MySQL 圧縮関連のコンテンツに関しては、次のような圧縮関連のシナリオが考えられます:
1. クライアントとサーバー間で送信されるデータの量が多すぎるため、帯域幅を節約するために圧縮する必要があります
2. MySQL の特定の列に大量のデータがあるため、特定の列のデータのみが圧縮されます
3. MySQL の 1 つまたは複数のテーブルにデータが多すぎるため、テーブルのデータを圧縮する必要があります。ディスク領域の使用量を減らすために、圧縮して保存する必要があります
このいくつかの問題には、MySQL 側で適切な解決策があります。最初の問題については、MySQL の圧縮プロトコルを使用して解決できます。2 つ目の問題については、MySQL の圧縮機能と解凍機能を使用できます。最も複雑な問題については、現在、myisam、innodb、tokudb、MyRocks などのエンジンがすべてテーブル圧縮をサポートしています。この記事では、MySQL 圧縮メカニズムに関連するこのような問題について詳しく説明します。主な内容は次のとおりです:
1. MySQL 圧縮プロトコルの概要
1. 適用可能なシナリオ
MySQL 圧縮プロトコルに適したシナリオMySQL である場合、サーバーとクライアント間で送信されるデータの量が多い、または利用可能な帯域幅が高くない場合は、次の 2 つのシナリオが考えられます:
a. 大量のデータのクエリと帯域幅の不足 (データのエクスポート時など)。 );
b. コピー時の binlog の量が大きすぎます。ログの圧縮とコピーのために、slave_compressed_protocol パラメーターを有効にします。
2. 圧縮プロトコルの概要
圧縮プロトコルは MySQL 通信プロトコルの一部であり、データ送信用の圧縮プロトコルを有効にするには、MySQL サーバーとクライアントの両方が zlib アルゴリズムをサポートする必要があります。圧縮プロトコルを有効にすると、CPU 負荷がわずかに増加します。 「圧縮プロトコルの有効化」を使用して、-C パラメーターまたは --compress=true パラメーターを使用してクライアントの圧縮機能を有効にします。 -C または compress=true オプションが有効な場合、サーバー セグメントに接続するときに、サーバーとのネゴシエーション後 (3 回のハンドシェイク後)、サーバー機能フラグ ビット 0x0020 (CLIENT_COMPRESS) が送信されます。サポートされています。圧縮の使用により、データ パケットの形式が変更されます。具体的な変更点は次のとおりです。
非圧縮データ パケットの形式:

圧縮されたデータ パケットの形式:

圧縮データ パケット形式 圧縮データグラム形式と非圧縮データグラム形式があります。これは、CPU オーバーヘッドを削減するために MySQL によって行われた最適化です。コンテンツが50バイト未満の場合は圧縮されませんが、50バイトを超える場合は圧縮機能が有効になります。具体的なルールは次のとおりです:
3 番目のフィールドの値が 0x00 に等しい場合、現在のパッケージが圧縮されていないことを意味するため、n * バイトの内容は 1 になります。 * バイト、n * バイト、つまり、リクエストの種類 * byte 的内容为 1 * byte,n * byte,即请求类型和请求内容。
当第三个字段的值大于 0x00 的时候,表示当前包已采用 zlib 压缩,因此使用的时候需要对 n * byte 进行解压,解压后内容为 1 * byte,n * とリクエストの内容。
3 番目のフィールドの値が 0x00 より大きい場合、現在のパッケージが zlib によって圧縮されていることを意味するため、それを使用する場合は、n * バイトを解凍する必要があり、解凍されたコンテンツは1 * バイト、n * バイトで、リクエストのタイプとリクエストの内容です。
3. 解決策の実践
クライアントの接続時に -C または --compress=true パラメーターを追加します。同期用の圧縮プロトコルのサポートを追加する場合は、slave_compressed_protocol=1 を設定する必要があります。以下は、圧縮プロトコルを使用して MySQL サーバーに接続する例です:
MySQL -h hostip -uroot -p password --compress MySQLdump -h hostip -uroot -p password -default-character-set=utf8 --compress --single-transaction dbname tablename > tablename.sql
マスター/スレーブ レプリケーションで圧縮送信を有効にする必要がある場合は、スレーブ マシンでslave_compressed_protocol=1 パラメーターを有効にすると、大丈夫ですよ。
4. 圧縮効果
MySQLdump の --compress オプションを使用して圧縮転送の効果を観察することも、マスター/スレーブ レプリケーションのslave_compressed_protocol パラメーターを使用して圧縮転送の効果を観察することもできます。ここで効果を確認してください。これ以上のスクリーンショットはありません。
2. MySQL 列圧縮ソリューションMySQL は現在、列の直接圧縮をサポートしていません。イメージ内の Tencent の TMySQL は列を直接圧縮できます。ここでは、MySQL がビジネスレベルで提供する圧縮・解凍機能を利用して、カラムの圧縮・解凍操作を行うという救国の方法を主に紹介します。つまり、特定の列を圧縮するには、書き込み時に COMPRESS 関数を呼び出してその列の内容を圧縮し、それを対応する列に格納する必要があります。読み取り時には、UNCOMPRESSED 関数を使用して、圧縮されたコンテンツを解凍します。
🎜1. 該当するシナリオ🎜针对 MySQL 中某个列或者某几个列数据量特别大,一般都是 varchar、text、char 等数据类型。
2、压缩函数简介
MySQL 的压缩函数 COMPRESS 压缩一个字符串,然后返回一个二进制串。使用该函数需要 MySQL 服务端支持压缩,否则会返回 NULL,压缩字段最好采用 varbinary 或者 blob 字段类型保存。使用 UNCOMPRESSED 函数对压缩过的数据进行解压。注意,采用这种方式需要在业务侧做少量改造。压缩后的内容存储方式如下:
a、空字符串就以空字符串存储
b、非空字符串存储方式为前 4 个 bype 保存未压缩的字符串,紧接着保存压缩的字符串
3、方案实践
字段压缩方案涉及到的几个相关的函数如下:
压缩函数
COMPRESS()
解压缩函数
UNCOMPRESS()
字符串长度函数
LENGTH()
未解压字符串长度函数
UNCOMPRESSED_LENGTH()
实践步骤:
a、创建一张测试表
CREATE TABLE IF NOT EXISTS `test`.`test_compress` ( `id` int unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `content` blob NOT NULL COMMENT '内容列', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 COMMENT='压缩测试表';
b、网表中插入压缩的数据
insert into `test`.`test_compress`(content) values(COMPRESS(REPEAT('a',1000)));
c、读取压缩的数据
select UNCOMPRESS(content) from `test`.`test_compress`;
d、查询对应的长度和内容
复制代码 代码如下:
SELECT UNCOMPRESSED_LENGTH(content) AS length, LENGTH(content) AS compress_length, UNCOMPRESS(content), content FROM `test`.`test_compress`
4、压缩效果
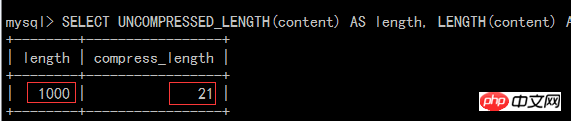
从上面截图可以看出压缩效果比较好,针对 text、char、varchr、blob 等,如果里面重复的数据越多压缩效果就越好。
三、InnoDB 表压缩方案解决方案
1、适用场景
采用压缩表一般都用在由于数据量太大,磁盘空间不足,负载主要体现在 IO 上,而服务器的 CPU 又有比较多的余量的场景。
2、表压缩简介 a、为什么需要压缩
目前很多表都支持压缩,比如 Myisam、InnoDB、TokuDB、MyRocks 。由于使用 InnoDB 主要是不需要做什么改动,对线上完全透明,压缩方案也非常成熟,因此这里只对 InnoDB 做详细说明。对于 TokuDB 和 MyRocks 的压缩方案将在 MySQL 的压缩方案(二)中撰文说明。
在 SSD 没有大量横行的时候,数据库几乎都是 IO 负载型的,在 CPU 有大量余量的时候,磁盘 IO 的瓶颈就已经凸显出来。而数据的大量存储,尤其是日志型数据和监控类型的数据,会导致磁盘空间快速增长。硬盘不够用也会在很多业务中凸显出来。一种比较好的方式就诞生了,那就是通过牺牲少量 CPU 资源,采用压缩来减少磁盘空间占用,以及优化 IO 和带宽。尤其针对读多些少的业务。
SSD 出来后,数据库的 IO 负载有所降低,但是对于磁盘空间的问题还是没有很好的解决。因此压缩表使用还是非常的广泛。这也就是为什么那么多的引擎都支持压缩的原因。而 innodb 在 MySQL 5.5 的时候就支持了压缩功能,只是压缩比比较低,通常在 50%左右。而 tokuDB 能达到 80%左右,MyRocks 的压缩比能达到 70%左右。
注意:压缩比和你存储的数据组成有很大的关系,并不是所有的数据都能达到上面所说的压缩比。如果大部分都是字符串,并且重复的数据比较多,压缩比会很好。
b、innodb 的压缩介绍
使用 innodb 压缩的前提条件是,innodb_file_per_table 这个参数要启用,innodb_file_format 这个参数设置成 Barracuda。
你可以使用 ROW_FORMAT=COMPRESSED 来 create 或者 alter 表来开启 innodb 的压缩功能,如果没有指定 KEY_BLOCK_SIZE 的大小,默认 KEY_BLOCK_SIZE 为 innodb_page_size 大小的一半,也可以通过指定 KEY_BLOCK_SIZE=n 参数来开启 innodb 的压缩功能,n 可以为 1、2、4、8、16,单位是 K。n 的值越小,压缩比越高,消耗的 CPU 资源也越多。注意 32K 或者 64K 的页不支持压缩。启用压缩后,索引数据也同样会被压缩。
你也可以通过调整 innodb_compression_level 来设置压缩的级别,级别从 1~9,默认是 6。级别越低,意味着压缩比越高,同时也意味着需要更多的 CPU 资源。
c、压缩算法
innodb 压缩借助的是著名的 zlib 库,采用 L777 压缩算法,这种算法在减少数据大小和 CPU 利用方面很成熟高效。同时这种算法是无损的,因此原生的未压缩的数据总是能够从压缩文件中重构,LZ777 实现原理是查找重复数据的序列号然后进行压缩,所以数据模式决定了压缩效率,一般而言,用户的数据能够被压缩 50%以上。
d、压缩表在 buffer_pool 中如何处理
在 buffer_pool 缓冲池中,压缩的数据通过 KEY_BLOCK_SIZE 的大小的页来保存,如果要提取压缩的数据或者要更新压缩数据对应的列,则会创建一个未压缩页来解压缩数据,然后在数据更新完成后,会将为压缩页的数据重新写入到压缩页中。内存不足的时候,MySQL 会讲对应的未压缩页踢出去。因此如果你启用了压缩功能,你的 buffer_pool 缓冲池中可能会存在压缩页和未压缩页,也可能只存在压缩页。不过可能仍然需要将你的 buffer_pool 缓冲池调大,以便能同时能保存压缩页和未压缩页。
MySQL 采用最少使用(LRU)算法来确定将哪些页保留在内存中,哪些页剔除出去,因此热数据会更多地保留在内存中。当压缩表被访问的时候,MySQL 使用自适应的 LRU 算法来维持内存中压缩页和非压缩页的平衡。当系统 IO 负载比较高的时候,这种算法倾向于讲未压缩的页剔除,一面腾出更多的空间来存放更多的压缩页。当系统 CPU 负载比较高的时候,MySQL 倾向于将压缩页和未压缩页都剔除出去,这个时候更多的内存用来保留热的数据,从而减少解压的操作。
e、如何评估 KEY_BLOCK_SIZE 是否合适
为了更深入地了解压缩表对性能的影响,在 Information Schema 库中有对应的表可以用来评估内存的使用和压缩率等指标。INNODB_CMP 是收集的是某一类的 KEY_BLOCK_SIZE 压缩表的整体状况的信息,汇总的是所有 KEY_BLOCK_SIZE 压缩表的统计。而 INNODB_CMP_PER_INDEX 表则是收集各个表和索引的压缩情况信息,这些信息对于在某个时间评估某个表的压缩效率或者诊断性能问题很有帮助。INNODB_CMP_PER_INDEX 表的收集会导致系统性能受到影响,必须 innodb_cmp_per_index_enabled 选项才会记录,生产环境最好不要开启。
我们可以通过观察 INNODB_CMP 表的压缩失败情况,如果失败比较多,则需要调大 KEY_BLOCK_SIZE。一般建议 KEY_BLOCK_SIZE 设置为 8。
3、方案实践
a、设置好 innodb_file_per_table 和 innodb_file_format 参数
SET GLOBAL innodb_file_per_table=1;SET GLOBAL innodb_file_format=Barracuda;
b、创建对应的压缩表
复制代码 代码如下:
CREATE TABLE compress_test (c1 INT PRIMARY KEY,content varchar(255)) ROW_FORMAT=COMPRESSEDKEY_BLOCK_SIZE=8;
如果是已经存在的表,则通过 alter 来修改,SQL 如下:
ALTER TABLE compress_test ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
4、压缩效果
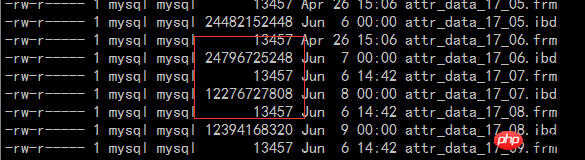
压缩效果通过线上的一个监控的表修改为压缩后的文件大小来说明,压缩前后对比如下:
以上がMySQL での圧縮の使用シナリオとソリューションの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7708
7708
 15
1640
14
1394
52
1288
25
1232
29
15
1640
14
1394
52
1288
25
1232
29

 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
 MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
WebアプリケーションにおけるMySQLの主な役割は、データを保存および管理することです。 1.MYSQLは、ユーザー情報、製品カタログ、トランザクションレコード、その他のデータを効率的に処理します。 2。SQLクエリを介して、開発者はデータベースから情報を抽出して動的なコンテンツを生成できます。 3.MYSQLは、クライアントサーバーモデルに基づいて機能し、許容可能なクエリ速度を確保します。
 MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをエレガントにインストールするための鍵は、公式のMySQLリポジトリを追加することです。特定の手順は次のとおりです。MYSQLの公式GPGキーをダウンロードして、フィッシング攻撃を防ぎます。 mysqlリポジトリファイルを追加:rpm -uvh https://dev.mysql.com/get/mysql80-community-rease-el7-3.noarch.rpm update yumリポジトリキャッシュ:yumアップデートインストールmysql:yumインストールmysql-server startup mysql sportin
