

オフラインデータ分析プロセスの概要
3 申請プロセスでは、コードの詳細にあまり注意を払わないでください広く使用されているデータ分析システム: 「Webログデータマイニング」
3.1 要件分析
3.1.1 ケース名
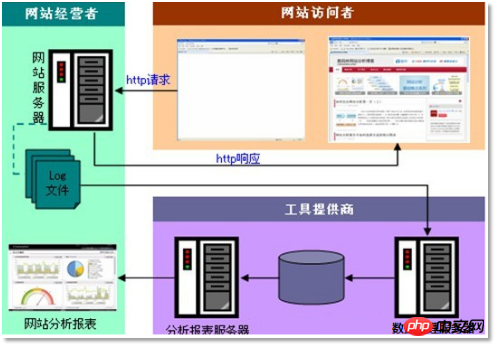 「Webサイトまたは
「Webサイトまたは
。
3.1.2 ケース要件の説明
「Web
Clickstream Log」には、Webサイトの運用に重要な情報が含まれており、ログ分析を通じて、Webサイトへのアクセス数やどのWebページであるかを知ることができます。訪問者数、どの Web ページが最も価値があるか、広告コンバージョン率、訪問者ソース情報、訪問者端末情報など。3.1.3 データソース
この場合のデータは主に ユーザーのクリック動作によって記録されます
取得方法: jsの
プログラムページ上で監視したいタグ バインディング イベントは、ユーザーがタグをクリックするかタグに移動する限りトリガーでき、ajaxリクエストがバックグラウンドのサーブレット
プログラムに送信されます。log4jは、web
サーバー(nginx、tomcatなど)上に成長ログファイルが形成されるように、イベント情報を記録するために使用されます。 は次のようになります: 58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver =1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
このケースは典型的なBIシステムと似ています非常に似ている、全体的に ただし、このケースは大量のデータを扱うことを前提としているため、プロセスの各リンクで使用されるテクノロジーは従来とはまったく異なりますBI以降のコースも同様です。 最初の説明: 1) データ収集: 収集プログラムのカスタマイズ開発、またはオープンソースフレームワークの使用 FLUME 2) データ前処理: mapreduce のカスタマイズ開発。 プログラムはhadoopcluster 3で実行されます3) データウェアハウステクノロジー: Hive4) ベースの 4) データエクスポート: sqoop データのインポートおよびエクスポートツールベースonhadoop 5)data視覚化:カスタマイズされた開発webプログラムまたはその他の製品およびその他の製品の使用hadoopエコシステム内のソースプロダクト 3. 2 ... b) ./sqoop export --connect jdbc: mysql://localhost:3306/weblogdb --username root --password root --table t_display_xx --export-dir /user /hive/warehouse/uv/dt=2014-08-03 プロジェクトの最終効果 データ処理プロセスが完了した後、さまざまな統計指標のレポートは定期的に出力されますが、実際の運用では、これらのレポート データを視覚化の形式で表示する必要があります。この場合、 プログラムを使用してデータの視覚化を実現します 効果は次のとおりです。 : 3.2 データ処理プロセス
3.2.1 フローチャート分析


統計結果を mysql にインポートする


以上がオフラインデータ分析プロセスの概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7480
7480
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 CSV ファイルを読み取り、pandas を使用してデータ分析を実行する
Jan 09, 2024 am 09:26 AM
CSV ファイルを読み取り、pandas を使用してデータ分析を実行する
Jan 09, 2024 am 09:26 AM
Pandas は、さまざまな種類のデータ ファイルを簡単に読み取り、処理できる強力なデータ分析ツールです。その中でも、CSV ファイルは最も一般的でよく使用されるデータ ファイル形式の 1 つです。この記事では、Pandas を使用して CSV ファイルを読み取り、データ分析を実行する方法と、具体的なコード例を紹介します。 1. 必要なライブラリをインポートする まず、以下に示すように、Pandas ライブラリと必要になる可能性のあるその他の関連ライブラリをインポートする必要があります。 importpandasaspd 2. Pan を使用して CSV ファイルを読み取ります。
 複数の Toutiao アカウントを開くにはどうすればよいですか? Toutiao アカウントを申請するプロセスはどのようなものですか?
Mar 22, 2024 am 11:00 AM
複数の Toutiao アカウントを開くにはどうすればよいですか? Toutiao アカウントを申請するプロセスはどのようなものですか?
Mar 22, 2024 am 11:00 AM
モバイルインターネットの人気により、Toutiao は私の国で最も人気のあるニュース情報プラットフォームの 1 つになりました。多くのユーザーは、さまざまなニーズを満たすために Toutiao プラットフォームで複数のアカウントを持つことを望んでいます。では、複数の Toutiao アカウントを開くにはどうすればよいでしょうか?この記事ではToutiaoアカウントを複数開設する方法と申請手順を詳しく紹介します。 1. 複数の Toutiao アカウントを開くにはどうすればよいですか?複数の Toutiao アカウントを開設する方法は次のとおりです。 Toutiao プラットフォームでは、ユーザーはさまざまな携帯電話番号を使用してアカウントを登録できます。各携帯電話番号で登録できる Toutiao アカウントは 1 つだけです。つまり、ユーザーは複数の携帯電話番号を使用して複数のアカウントを登録できます。 2. 電子メール登録: 別の電子メール アドレスを使用して Toutiao アカウントを登録します。携帯電話番号の登録と同様に、各メール アドレスでも Toutiao アカウントを登録できます。 3. サードパーティのアカウントでログインします
 最新のWin11サウンドチューニング方法を紹介
Jan 08, 2024 pm 06:41 PM
最新のWin11サウンドチューニング方法を紹介
Jan 08, 2024 pm 06:41 PM
最新の win11 にアップデートした後、システムのサウンドが少し変わったように感じますが、調整方法がわからないという人が多いので、このサイトでは、最新の win11 サウンド調整方法を紹介します。操作は難しくなく、選択肢も豊富ですので、ぜひダウンロードして試してみてください。最新のコンピュータ システム Windows 11 のサウンドを調整する方法 1. まず、デスクトップの右下隅にあるサウンド アイコンを右クリックし、「再生設定」を選択します。 2. 次に設定を入力し、再生バーの「スピーカー」をクリックします。 3. 次に、右下の「プロパティ」をクリックします。 4. プロパティの「拡張」オプションバーをクリックします。 5. この時、「すべての効果音を無効にする」の前にある√にチェックが入っている場合は、チェックを外します。 6. その後、以下の効果音を選択して設定し、クリックします。
 Douyin スリープアンカーは儲かりますか?睡眠ライブストリーミングの具体的な手順は何ですか?
Mar 21, 2024 pm 04:41 PM
Douyin スリープアンカーは儲かりますか?睡眠ライブストリーミングの具体的な手順は何ですか?
Mar 21, 2024 pm 04:41 PM
今日のペースの速い社会では、睡眠の質の問題に悩まされる人がますます増えています。ユーザーの睡眠の質を向上させるために、特別な睡眠アンカーのグループがDouyinプラットフォームに登場しました。ライブ配信を通じてユーザーと交流し、睡眠のヒントを共有し、視聴者が安らかに眠りにつくのを助けるリラックスできる音楽やサウンドを提供します。では、このスリープアンカーは儲かるのだろうか?この記事ではこの問題に焦点を当てます。 1.Douyin スリープアンカーは儲かりますか? Douyin スリープアンカーは確かに一定の利益を得ることができます。まず、ライブ配信ルームの投げ銭機能を通じてギフトや送金を受け取ることができ、これらの特典はファンの数と視聴者の満足度によって異なります。次に、Douyin プラットフォームは、生放送の視聴数、いいね、シェア、その他のデータに基づいてアンカーに一定のシェアを与えます。一部のスリープアンカーは、
 PyCharm 初心者ガイド: 置換関数の包括的な分析
Feb 25, 2024 am 11:15 AM
PyCharm 初心者ガイド: 置換関数の包括的な分析
Feb 25, 2024 am 11:15 AM
PyCharm は、開発効率を大幅に向上させる豊富な機能とツールを備えた強力な Python 統合開発環境です。その中でも置換機能は開発プロセスで頻繁に使用される機能の 1 つであり、開発者がコードを迅速に修正し、コードの品質を向上させるのに役立ちます。この記事では、初心者がこの関数をよりよく習得して使用できるように、特定のコード例と組み合わせて PyCharm の置換関数を詳細に紹介します。置換関数の概要 PyCharm の置換関数は、開発者がコード内の指定されたテキストを迅速に置換するのに役立ちます
 コンピューター上のプリンタードライバーの場所に関する詳細情報
Jan 08, 2024 pm 03:29 PM
コンピューター上のプリンタードライバーの場所に関する詳細情報
Jan 08, 2024 pm 03:29 PM
多くのユーザーは、コンピューターにプリンター ドライバーをインストールしていますが、そのドライバーを見つける方法がわかりません。そこで、今日は、コンピューターのプリンタードライバーの場所について詳しくご紹介します。まだ知らない人のために、プリンタードライバーの場所を見てみましょう。元の意味を変えずに内容を書き換える場合、言語は中国語に書き換えられ、元の文章が表示される必要はありません。まず、サードパーティのソフトウェアを使用して検索することをお勧めします。 2. 右上隅の「ツールボックス」を見つけます。下の「デバイスマネージャー」をクリックします。書き換えられた文: 3. 下部にある [デバイス マネージャー] を見つけてクリックします。 4. 次に、[印刷キュー] を開いてプリンター デバイスを見つけます。今回はプリンターの名前とモデルです。 5. プリンター デバイスを右クリックすると、更新またはアンインストールできます。
 Samsung S24aiの機能を詳しく紹介
Jun 24, 2024 am 11:18 AM
Samsung S24aiの機能を詳しく紹介
Jun 24, 2024 am 11:18 AM
2024 年は AI 携帯電話元年です。AI スマート テクノロジーにより、携帯電話はますます効率的かつ便利に使用できるようになります。最近、今年の初めにリリースされたGalaxy S24シリーズは、生成AIエクスペリエンスを再び改善しました。以下で詳細な機能の紹介を見てみましょう。 1. 生成 AI は Samsung Galaxy S24 シリーズを強力に強化します。Galaxy S24 シリーズは、Galaxy AI によって強化され、多くのインテリジェント アプリケーションをもたらします。これらの機能は Samsung One UI6.1 と緊密に統合されており、ユーザーはいつでも便利なインテリジェントなエクスペリエンスを得ることができ、パフォーマンスが大幅に向上します。携帯電話の効率と使いやすさ。 Galaxy S24 シリーズで先駆けて開発されたサークルアンド検索機能は、長押しするだけで実現できる機能です。
 ドージコインとは
Apr 01, 2024 pm 04:46 PM
ドージコインとは
Apr 01, 2024 pm 04:46 PM
Dogecoin は、インターネット ミームに基づいて作成された暗号通貨であり、固定供給上限がなく、速い取引時間、低い取引手数料、そして大規模なミーム コミュニティを備えています。用途には、少額の取引、チップ、慈善寄付が含まれます。しかし、その無限の供給、市場のボラティリティ、ジョークコインとしての地位は、リスクと懸念ももたらします。ドージコインとは何ですか? Dogecoin は、インターネットのミームやジョークに基づいて作成された暗号通貨です。起源と歴史: Dogecoin は、2 人のソフトウェア エンジニア、ビリー マーカスとジャクソン パーマーによって 2013 年 12 月に作成されました。当時人気だった「Doge」ミームからインスピレーションを得た、片言の英語を話す柴犬をフィーチャーしたコミカルな写真。特徴と利点: 無制限の供給: ビットコインなどの他の暗号通貨とは異なります。
