
jdk1.7.0_79
ほとんどの人はスレッド プールを使用する可能性があり、スレッド プールが使用される理由も知っています。タスクは非同期で実行する必要があり、スレッドは均一に管理する必要があるだけです。スレッド プールからスレッドを取得することについては、タスクを実行するためにスレッドが必要な場合、スレッド プールにアイドル状態のスレッドがあれば、そのスレッドが実行されることだけを知っている人が多いかもしれません。アイドル状態のスレッドがない場合は、そのまま実行されます。実際、スレッド プールの実行原理はそれほど単純ではありません。
スレッドプールクラス-ThreadPoolExecutorはJava同時実行パッケージで提供されています。実際、多くの人はExecutorsfactoryクラスによって提供されるスレッドプールを使用するかもしれません: newFixedThreadPool、newSingleThreadPool、 newCachedThreadPool、これら 3 つのスレッド プールは ThreadPoolExecutor のサブクラスではありません。まず、ソース コードを確認して、 が合計 4 つあることを確認します。施工方法。
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)
corePoolSize: コアスレッドプール内のスレッド数 maximumPoolSize: スレッドプールスレッドの最大数 keepAliveTime: スレッドアクティビティ保持時間、スレッドプールのワーカースレッドがアイドル状態になった後に生存し続ける時間。
単位:スレッドアクティビティの保持時間の単位。
workQueue: タスクキューで使用するブロッキングキューを指定します
corePoolSize
とmaximumPoolSizeは、どちらも指定したスレッドプール内のスレッド数を渡すだけで良いようです。パラメータを使用してスレッド プールを作成できます。もちろん、Java には、上記の一般的に使用されるスレッド プール クラスが用意されています。必要に応じて カスタム スレッド プールを自分で作成したい場合は、スレッド プールに関連するいくつかのパラメータを自分で「構成」する必要があります。 タスクがスレッドプールに渡されて処理される場合、スレッドプールの実行原理は以下の図のようになります『JavaThe Art of Concurrent Programming』を参照してください。 ①
まずコアを判定します スレッドプールに実行可能なスレッドがあるか確認し、アイドル状態のスレッドがある場合はタスクを実行するスレッドを作成します。②コアスレッドプールに実行可能なスレッドがない場合、タスクはタスクキューに投入されます。 ③タスクキュー(制限付き)も満杯だが、実行中のスレッド数がスレッドプールの最大数に満たない場合、タスクを実行するために新しいスレッドが作成されますが、実行中のスレッド数が上限に達している場合スレッド プールの最大数に達すると、現時点ではタスクを実行するためのスレッドは作成されません。
つまり、実際には、スレッドプールは単にスレッドプールにタスクを投げるだけではなく、スレッドプールにスレッドがあればタスクが実行され、スレッドがなければ待機します。 スレッド プールの原則を統合するために、上記で一般的に使用される 3 つのスレッド プールについて学びましょう: 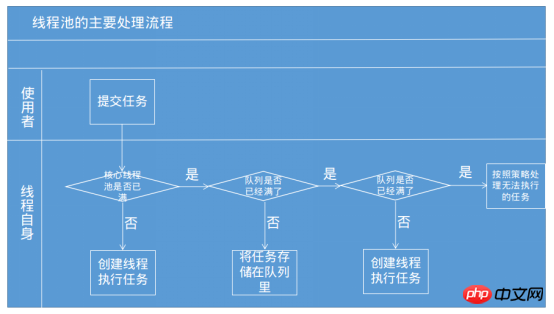
Executors.newFixedThreadPool:固定数のスレッドでスレッド プールを作成します。
りー可以看到newFixedThreadPool中调用的是ThreadPoolExecutor类,传递的参数corePoolSize= maximumPoolSize=nThread。回顾线程池的执行原理,当一个任务提交到线程池中,首先判断核心线程池里有没有空闲线程,有则创建线程,没有则将任务放到任务队列(这里是有界阻塞队列LinkedBlockingQueue)中,如果任务队列已经满了的话,对于newFixedThreadPool来说,它的最大线程池数量=核心线程池数量,此时任务队列也满了,将不能扩展创建新的线程来执行任务。
Executors.newSingleThreadExecutor:创建只包含一个线程的线程池。
//Executors# newSingleThreadExecutorpublic static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegateExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
}只有一个线程的线程池好像有点奇怪,并且并没有直接将返回ThreadPoolExecutor,甚至也没有直接将线程池数量1传递给newFixedThreadPool返回。那就说明这个只含有一个线程的线程池,或许并没有只包含一个线程那么简单。在其源码注释中这么写到:创建只有一个工作线程的线程池用于操作一个无界队列(如果由于前驱节点的执行被终止结束了,一个新的线程将会继续执行后继节点线程)任务得以继续执行,不同于newFixedThreadPool(1)不会有额外的线程来重新继续执行后继节点。也就是说newSingleThreadExecutor自始至终都只有一个线程在执行,这和newFixedThreadPool一样,但如果线程终止结束过后newSingleThreadExecutor则会重新创建一个新的线程来继续执行任务队列中的线程,而newFixedThreaPool则不会。
Executors.newCachedThreadPool:根据需要创建新线程的线程池。
//Executors#newCachedThreadPoolpublic static ExecutorService newCachedThreadPool() {
return new ThreadPooExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}可以看到newCachedThread返回的是ThreadPoolExecutor,其参数核心线程池corePoolSize = 0, maximumPoolSize = Integer.MAX_VALUE,这也就是说当任务被提交到newCachedThread线程池时,将会直接把任务放到SynchronousQueue任务队列中,maximumPool从任务队列中获取任务。注意SynchronousQueue是一个没有容量的队列,也就是说每个入队操作必须等待另一个线程的对应出队操作,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,newCachedThreadPool会不断创建线程,线程多并不是一件好事,严重会耗尽CPU和内存资源。
题外话:newFixedThreadPool、newSingleThreadExecutor、newCachedThreadPool,这三者都直接或间接调用了ThreadPoolExecutor,为什么它们三者没有直接是其子类,而是通过Executors来实例化呢?这是所采用的静态工厂方法,在java.util.Connections接口中同样也是采用的静态工厂方法来创建相关的类。这样有很多好处,静态工厂方法是用来产生对象的,产生什么对象没关系,只要返回原返回类型或原返回类型的子类型都可以,降低API数目和使用难度,在《Effective Java》中的第1条就是静态工厂方法。
回到ThreadPoolExecutor,首先来看它的继承关系:

ThreadPoolExecutor它的顶级父类是Executor接口,只包含了一个方法——execute,这个方法也就是线程池的“执行”。
//Executor#executepublic interface Executor {void execute(Runnable command);
}Executor#execute的实现则是在ThreadPoolExecutor中实现的:
//ThreadPoolExecutor#executepublic void execute(Runnable command) { if (command == null) throw new NullPointerException();
int c = ctl.get();
…
}一来就碰到个不知所云的ctl变量它的定义:
private final AtomicInteger ctl = new AtlmicInteger(ctlOf(RUNNING, 0));
这个变量使用来干嘛的呢?它的作用有点类似我们在《7.ReadWriteLock接口及其实现ReentrantReadWriteLock》中提到的读写锁有读、写两个同步状态,而AQS则只提供了state一个int型变量,此时将state高16位表示为读状态,低16位表示为写状态。这里的clt同样也是,它表示了两个概念:
workerCount:当前有效的线程数
runState:当前线程池的五种状态,Running、Shutdown、Stop、Tidying、Terminate。
int型变量一共有32位,线程池的五种状态runState至少需要3位来表示,故workCount只能有29位,所以代码中规定线程池的有效线程数最多为229-1。
//ThreadPoolExecutorprivate static final int COUNT_BITS = Integer.SIZE – 3; //32-3=29,线程数量所占位数private static final int CAPACITY = (1 << COUNT_BITS) – 1; //低29位表示最大线程数,229-1//五种线程池状态private static final int RUNNING = -1 << COUNT_BITS; /int型变量高3位(含符号位)101表RUNINGprivate static final int SHUTDOWN = 0 << COUNT_BITS; //高3位000private static final int STOP = 1 << COUNT_BITS; //高3位001private static final int TIDYING = 2 << COUNT_BITS; //高3位010private static final int TERMINATED = 3 << COUNT_BITS; //高3位011
再次回到ThreadPoolExecutor#execute方法:
1 //ThreadPoolExecutor#execute 2 public void execute(Runnable command) { 3 if (command == null)
4 throw new NullPointerException(); 5 int c = ctl.get(); //由它可以获取到当前有效的线程数和线程池的状态 6 /*1.获取当前正在运行线程数是否小于核心线程池,是则新创建一个线程执行任务,否则将任务放到任务队列中*/ 7 if (workerCountOf(c) < corePoolSize){ 8 if (addWorker(command, tre)) //在addWorker中创建工作线程执行任务 9 return ;10 c = ctl.get();11 }12 /*2.当前核心线程池中全部线程都在运行workerCountOf(c) >= corePoolSize,所以此时将线程放到任务队列中*/13 if (isRunning(c) && workQueue.offer(command)) { //线程池是否处于运行状态,且是否任务插入任务队列成功14 int recheck = ctl.get();15 if (!isRunning(recheck) && remove(command)) //线程池是否处于运行状态,如果不是则使刚刚的任务出队16 reject(command); //抛出RejectedExceptionException异常17 else if (workerCountOf(recheck) == 0)18 addWorker(null, false);19 }20 /*3.插入队列不成功,且当前线程数数量小于最大线程池数量,此时则创建新线程执行任务,创建失败抛出异常*/21 else if (!addWorker(command, false)){22 reject(command); //抛出RejectedExceptionException异常23 }24 }上面代码注释第7行的即判断当前核心线程池里是否有空闲线程,有则通过addWorker方法创建工作线程执行任务。addWorker方法较长,筛选出重要的代码来解析。
1 //ThreadPoolExecutor#addWorker 2 private boolean addWorker(Runnable firstTask, boolean core) { 3 /*首先会再次检查线程池是否处于运行状态,核心线程池中是否还有空闲线程,都满足条件过后则会调用compareAndIncrementWorkerCount先将正在运行的线程数+1,数量自增成功则跳出循环,自增失败则继续从头继续循环*/ 4 ... 5 if (compareAndIncrementWorkerCount(c)) 6 break retry; 7 ... 8 /*正在运行的线程数自增成功后则将线程封装成工作线程Worker*/ 9 boolean workerStarted = false;10 boolean workerAdded = false;11 Worker w = null;12 try {13 final ReentrantLock mainLock = this.mainLock; //全局锁14 w = new Woker(firstTask); //将线程封装为Worker工作线程15 final Thread t = w.thread;16 if (t != null) {17 mainLock.lock(); //获取全局锁18 /*当持有了全局锁的时候,还需要再次检查线程池的运行状态等*/19 try {20 int c = clt.get();21 int rs = runStateOf(c); //线程池运行状态22 if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)){ //线程池处于运行状态,或者线程池关闭且任务线程为空23 if (t.isAlive()) //线程处于活跃状态,即线程已经开始执行或者还未死亡,正确的应线程在这里应该是还未开始执行的24 throw new IllegalThreadStateException();25 workers.add(w); //private final HashSet<Worker> wokers = new HashSet<Worker>();包含线程池中所有的工作线程,只有在获取了全局的时候才能访问它。将新构造的工作线程加入到工作线程集合中26 int s = worker.size(); //工作线程数量27 if (s > largestPoolSize)28 largestPoolSize = s;29 workerAdded = true; //新构造的工作线程加入成功30 }31 } finally {32 mainLock.unlock();33 }34 if (workerAdded) {35 t.start(); //在被构造为Worker工作线程,且被加入到工作线程集合中后,执行线程任务,注意这里的start实际上执行Worker中run方法,所以接下来分析Worker的run方法36 workerStarted = true;37 }38 }39 } finally {40 if (!workerStarted) //未能成功创建执行工作线程41 addWorkerFailed(w); //在启动工作线程失败后,将工作线程从集合中移除42 }43 return workerStarted;44 }在上面第35代码中,工作线程被成功添加到工作线程集合中后,则开始start执行,这里start执行的是Worker工作线程中的run方法。
//ThreadPoolExecutor$Worker,它继承了AQS,同时实现了Runnable,所以它具备了这两者的所有特性private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
final Thread thread;
Runnable firstTask;
public Worker(Runnable firstTask) {
setState(-1); //设置AQS的同步状态为-1,禁止中断,直到调用runWorker this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); //通过线程工厂来创建一个线程,将自身作为Runnable传递传递 }
public void run() {
runWorker(this); //运行工作线程 }
}ThreadPoolExecutor#runWorker,在此方法中,Worker在执行完任务后,还会循环获取任务队列里的任务执行(其中的getTask方法),也就是说Worker不仅仅是在执行完给它的任务就释放或者结束,它不会闲着,而是继续从任务队列中获取任务,直到任务队列中没有任务可执行时,它才退出循环完成任务。理解了以上的源码过后,往后线程池执行原理的第二步、第三步的理解实则水到渠成。
以上がThreadPoolExecutor スレッド プールの原理とその実行メソッドの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



