

Python クローラーをゼロから作成した全記録

最初の9回の記事は基礎から書き方まで詳しく紹介していますので、10回目の記事ではクローラープログラムの書き方をステップバイステップで詳しく記録していきます。本校のウェブサイトについて:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html
スコアを確認するには、ログインする必要があり、各科目のスコアが表示されます。ただし、加重平均点である成績点は表示されません。
 このように評定点を手動で計算するのは、明らかに非常に面倒です。したがって、Python を使用してこの問題を解決するクローラーを作成できます。
このように評定点を手動で計算するのは、明らかに非常に面倒です。したがって、Python を使用してこの問題を解決するクローラーを作成できます。
まずツールを準備しましょう:HttpFoxプラグイン。
これは、ページのリクエストとレスポンスの時間と内容、およびブラウザで使用される COOKIE を分析する http プロトコル分析プラグインです。
例として、Firefox にインストールするだけで、次のような効果が得られます:
 対応する情報を非常に直感的に表示できます。
対応する情報を非常に直感的に表示できます。
「開始」をクリックして検出を開始し、「停止」をクリックして検出を一時停止し、「クリア」をクリックしてコンテンツをクリアします。
通常、使用する前に、[停止] をクリックして一時停止し、[クリア] をクリックして画面をクリアし、現在のページにアクセスして取得したデータが表示されていることを確認します。
ログイン時にどのような情報が送信されるかを確認するには、山東大学のスコア照会 Web サイトにアクセスしてみましょう。
まず、ログイン ページに移動し、httpfox を開いてクリアし、[開始] をクリックして検出を開始します:
 個人情報を入力した後、httpfox がオンになっていることを確認し、[OK] をクリックして情報を送信し、ログに記録しますで。
個人情報を入力した後、httpfox がオンになっていることを確認し、[OK] をクリックして情報を送信し、ログに記録しますで。
この時点で、httpfox が 3 つの情報を検出したことがわかります:
 この時点で、ページにアクセスした後にフィードバックされたデータが確実にキャプチャされるように、ログインをシミュレートできるように、停止ボタンをクリックします。クローラーをするとき。
この時点で、ページにアクセスした後にフィードバックされたデータが確実にキャプチャされるように、ログインをシミュレートできるように、停止ボタンをクリックします。クローラーをするとき。
一見すると、GET が 2 つ、POST が 1 つで、合計 3 つのデータが得られましたが、それらが何なのか、どのように使用するのかはまだわかりません。
そのため、キャプチャしたコンテンツを 1 つずつ確認する必要があります。
最初にPOST情報を見てみましょう:
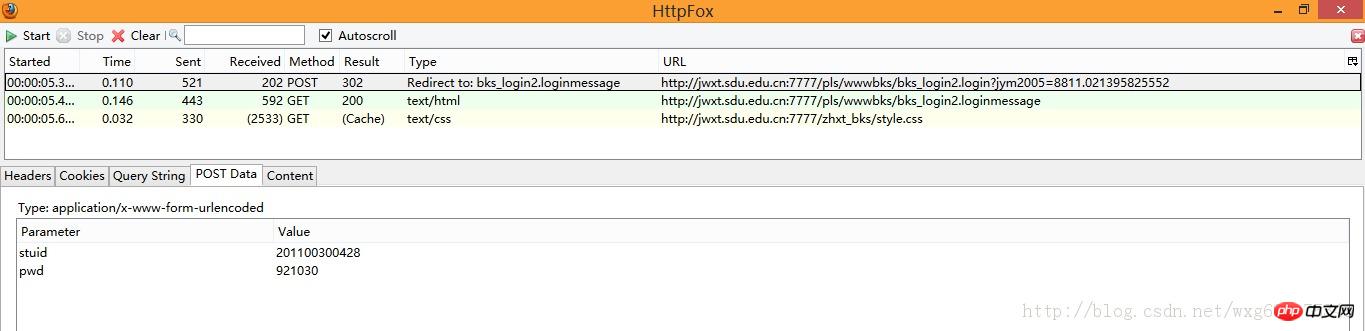
POST情報なので、PostDataを見るだけで済みます。
stid と pwd の 2 つの POST データがあることがわかります。
そして、Type の Redirect to から、POST 完了後に bks_login2.loginmessage ページにジャンプすることがわかります。
このデータは、「OK」をクリックした後に送信されたフォームデータであることがわかります。
Cookie ラベルをクリックすると、Cookie 情報が表示されます:

はい、ACCOUNT Cookie が受信されました。セッション終了後に自動的に破棄されます。
それでは、送信後にどのような情報を受け取りましたか?
次の 2 つの GET データを見てみましょう。
まず最初のコンテンツを見てみましょう。コンテンツタグをクリックして、受け取ったコンテンツを表示します。 -HTML ソース コードは間違いなく公開されています:

これは単にページの HTML ソース コードであるようです。Cookie をクリックすると、Cookie 関連の情報が表示されます:

。ああ、HTML ページの元のコンテンツは、Cookie 情報が送信された後に受信されました。
最後に受信したメッセージを見てみましょう:
 大まかに見てみると、これは style.css という単なる CSS ファイルであるはずですが、これは私たちにはあまり影響しません。
大まかに見てみると、これは style.css という単なる CSS ファイルであるはずですが、これは私たちにはあまり影響しません。
サーバーに送信したデータと受信したデータがわかったので、基本的なプロセスは次のとおりです:
まず、学生 ID とパスワードを送信します--- > ;その後、Cookie の値を返し、Cookie をサーバーに送信します--->ページ情報を返します。成績ページからデータを取得し、正規表現を使用して成績と単位を個別に抽出し、加重平均を計算します。
OK、非常に単純なサンプル用紙のように見えます。それでは試してみましょう。
しかし、実験の前に、POST データがどこに送信されるかという未解決の問題がまだあります。
元のページをもう一度見てください:
明らかに、これは HTML フレームワークを使用して実装されています。つまり、アドレス バーに表示されるアドレスは、右側のフォームを送信するアドレスではありません。
それでは、どうすれば本当の住所を取得できるのでしょうか - 。 - 右クリックしてページのソース コードを表示します:
はい、そうです。name="w_right" を持つものが目的のログイン ページです。
Web サイトの元のアドレスは:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html
したがって、実際のフォーム送信アドレスは次のようになります:
http://jwxt .sdu.edu.cn:7777/zhxt_bks/xk_login.html
入力してみると、

清華大学のコース選択システムであることが判明しました。 。 。おそらくうちの学校はページを作るのが面倒だったので、そのまま借りただけだと思います。 。結果的にはタイトルも変更されませんでした。 。 。
しかし、このページはまだ必要なページではありません。POST データが送信されるページは、フォームの ACTION で送信されるページである必要があるためです。
つまり、POST データが送信される場所を知るためにソース コードをチェックする必要があります:

そうですね、視覚的に言うと、これは POST データが送信されるアドレスです。
アドレスバーに配置します。完全なアドレスは次のようになります:
http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login
(取得方法は非常に簡単です。Firefox で参照します。ブラウザでリンクを直接クリックすると、リンクのアドレスが表示されます)
5. 試してみましょう
次のタスクは、Python を使用して POST データの送信をシミュレートし、返された Cookie 値。
Cookieの操作については、次のブログ投稿を参照してください:
http://www.jb51.net/article/57144.htm
最初にPOSTデータを準備し、次にCookie受信を準備し、次に書き込みますソース コードは次のとおりです。
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#需要POST的数据#
postdata=urllib.urlencode({
'stuid':'201100300428',
'pwd':'921030'
})
#自定义一个请求#
req = urllib2.Request(
url = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login',
data = postdata
)
#访问该链接#
result = opener.open(req)
#打印返回的内容#
print result.read()この後、実行結果を見てみましょう:

これで、シミュレートされたログインが成功したことが計算されます。
6. 状況を変える
次のタスクは、クローラーを使用して生徒のスコアを取得することです。
ソースのウェブサイトをもう一度見てみましょう。
HTTPFOX を開いた後、クリックして結果を表示し、次のデータがキャプチャされたことを確認します。

最初の GET データをクリックしてコンテンツを表示すると、Content が取得された結果のコンテンツであることがわかります。
取得したページリンクは、右クリックしてページのソースコードから要素を表示すると、リンクをクリック後にジャンプするページが表示されます(Firefoxの場合は右クリックして「このフレームを表示」するだけです) ):

次のように結果を表示するためのリンクを取得できます:
http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre
7。すべての準備が整いました
これですべての準備が整ったので、クローラーにリンクを適用して、結果ページが表示されるかどうかを確認してください。
httpfox からわかるように、スコア情報を返すには Cookie を送信する必要があるため、Python を使用してスコア情報を要求する Cookie の送信をシミュレートします:
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
#初始化一个CookieJar来处理Cookie的信息#
cookie = cookielib.CookieJar()
#创建一个新的opener来使用我们的CookieJar#
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#需要POST的数据#
postdata=urllib.urlencode({
'stuid':'201100300428',
'pwd':'921030'
})
#自定义一个请求#
req = urllib2.Request(
url = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login',
data = postdata
)
#访问该链接#
result = opener.open(req)
#打印返回的内容#
print result.read()
#打印cookie的值
for item in cookie:
print 'Cookie:Name = '+item.name
print 'Cookie:Value = '+item.value
#访问该链接#
result = opener.open('http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre')
#打印返回的内容#
print result.read()F5 を押して実行して確認します。キャプチャされたデータ:

このままでも問題ないので、正規表現を使ってデータを少し加工して、クレジットと対応するスコアを抽出します。
8. すぐに使える
このような大量の HTML ソース コードは明らかに処理に役立ちません。次に、正規表現を使用して必要なデータを抽出する必要があります。
正規表現のチュートリアルについては、次のブログ投稿をご覧ください:
http://www.jb51.net/article/57150.htm
結果のソース コードを見てみましょう:

そんな時は、正規表現を使えば簡単です。
コードを少し整理してから、正規表現を使用してデータを抽出します。
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
import re
class SDU_Spider:
# 申明相关的属性
def __init__(self):
self.loginUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login' # 登录的url
self.resultUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre' # 显示成绩的url
self.cookieJar = cookielib.CookieJar() # 初始化一个CookieJar来处理Cookie的信息
self.postdata=urllib.urlencode({'stuid':'201100300428','pwd':'921030'}) # POST的数据
self.weights = [] #存储权重,也就是学分
self.points = [] #存储分数,也就是成绩
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookieJar))
def sdu_init(self):
# 初始化链接并且获取cookie
myRequest = urllib2.Request(url = self.loginUrl,data = self.postdata) # 自定义一个请求
result = self.opener.open(myRequest) # 访问登录页面,获取到必须的cookie的值
result = self.opener.open(self.resultUrl) # 访问成绩页面,获得成绩的数据
# 打印返回的内容
# print result.read()
self.deal_data(result.read().decode('gbk'))
self.print_data(self.weights);
self.print_data(self.points);
# 将内容从页面代码中抠出来
def deal_data(self,myPage):
myItems = re.findall('<TR>.*?<p.*?<p.*?<p.*?<p.*?<p.*?>(.*?)</p>.*?<p.*?<p.*?>(.*?)</p>.*?</TR>',myPage,re.S) #获取到学分
for item in myItems:
self.weights.append(item[0].encode('gbk'))
self.points.append(item[1].encode('gbk'))
# 将内容从页面代码中抠出来
def print_data(self,items):
for item in items:
print item
#调用
mySpider = SDU_Spider()
mySpider.sdu_init()レベルは限られており、正規表現は少し見苦しいです。実行時の効果は次の図に示すとおりです。

OK、次はデータの処理です。 。
9. 凱旋
完全なコードは次のとおりです。この時点で、完全なクローラー プロジェクトが完了します。
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
import re
import string
class SDU_Spider:
# 申明相关的属性
def __init__(self):
self.loginUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login' # 登录的url
self.resultUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre' # 显示成绩的url
self.cookieJar = cookielib.CookieJar() # 初始化一个CookieJar来处理Cookie的信息
self.postdata=urllib.urlencode({'stuid':'201100300428','pwd':'921030'}) # POST的数据
self.weights = [] #存储权重,也就是学分
self.points = [] #存储分数,也就是成绩
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookieJar))
def sdu_init(self):
# 初始化链接并且获取cookie
myRequest = urllib2.Request(url = self.loginUrl,data = self.postdata) # 自定义一个请求
result = self.opener.open(myRequest) # 访问登录页面,获取到必须的cookie的值
result = self.opener.open(self.resultUrl) # 访问成绩页面,获得成绩的数据
# 打印返回的内容
# print result.read()
self.deal_data(result.read().decode('gbk'))
self.calculate_date();
# 将内容从页面代码中抠出来
def deal_data(self,myPage):
myItems = re.findall('<TR>.*?<p.*?<p.*?<p.*?<p.*?<p.*?>(.*?)</p>.*?<p.*?<p.*?>(.*?)</p>.*?</TR>',myPage,re.S) #获取到学分
for item in myItems:
self.weights.append(item[0].encode('gbk'))
self.points.append(item[1].encode('gbk'))
#计算绩点,如果成绩还没出来,或者成绩是优秀良好,就不运算该成绩
def calculate_date(self):
point = 0.0
weight = 0.0
for i in range(len(self.points)):
if(self.points[i].isdigit()):
point += string.atof(self.points[i])*string.atof(self.weights[i])
weight += string.atof(self.weights[i])
print point/weight
#调用
mySpider = SDU_Spider()
mySpider.sdu_init()上記は、このクローラーの誕生の全過程を詳細に記録したものですが、何か魔法のようなものはあるのでしょうか? ?あはは、冗談です、困っている友達はそれを参照して自由に拡張できます
以上がPython クローラーをゼロから作成した全記録の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1677
1677
 14
1431
52
1334
25
1280
29
1257
24
14
1431
52
1334
25
1280
29
1257
24

 PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPは主に手順プログラミングですが、オブジェクト指向プログラミング(OOP)もサポートしています。 Pythonは、OOP、機能、手続き上のプログラミングなど、さまざまなパラダイムをサポートしています。 PHPはWeb開発に適しており、Pythonはデータ分析や機械学習などのさまざまなアプリケーションに適しています。
 PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPはWeb開発と迅速なプロトタイピングに適しており、Pythonはデータサイエンスと機械学習に適しています。 1.PHPは、単純な構文と迅速な開発に適した動的なWeb開発に使用されます。 2。Pythonには簡潔な構文があり、複数のフィールドに適しており、強力なライブラリエコシステムがあります。
 PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPは1994年に発信され、Rasmuslerdorfによって開発されました。もともとはウェブサイトの訪問者を追跡するために使用され、サーバー側のスクリプト言語に徐々に進化し、Web開発で広く使用されていました。 Pythonは、1980年代後半にGuidovan Rossumによって開発され、1991年に最初にリリースされました。コードの読みやすさとシンプルさを強調し、科学的コンピューティング、データ分析、その他の分野に適しています。
 Golang vs. Python:パフォーマンスとスケーラビリティ
Apr 19, 2025 am 12:18 AM
Golang vs. Python:パフォーマンスとスケーラビリティ
Apr 19, 2025 am 12:18 AM
Golangは、パフォーマンスとスケーラビリティの点でPythonよりも優れています。 1)Golangのコンピレーションタイプの特性と効率的な並行性モデルにより、高い並行性シナリオでうまく機能します。 2)Pythonは解釈された言語として、ゆっくりと実行されますが、Cythonなどのツールを介してパフォーマンスを最適化できます。
 Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Pythonは学習と使用が簡単ですが、Cはより強力ですが複雑です。 1。Python構文は簡潔で初心者に適しています。動的なタイピングと自動メモリ管理により、使いやすくなりますが、ランタイムエラーを引き起こす可能性があります。 2.Cは、高性能アプリケーションに適した低レベルの制御と高度な機能を提供しますが、学習しきい値が高く、手動メモリとタイプの安全管理が必要です。
 Python vs. C:パフォーマンスと効率の探索
Apr 18, 2025 am 12:20 AM
Python vs. C:パフォーマンスと効率の探索
Apr 18, 2025 am 12:20 AM
Pythonは開発効率でCよりも優れていますが、Cは実行パフォーマンスが高くなっています。 1。Pythonの簡潔な構文とリッチライブラリは、開発効率を向上させます。 2.Cのコンピレーションタイプの特性とハードウェア制御により、実行パフォーマンスが向上します。選択を行うときは、プロジェクトのニーズに基づいて開発速度と実行効率を比較検討する必要があります。
 Python vs. JavaScript:開発環境とツール
Apr 26, 2025 am 12:09 AM
Python vs. JavaScript:開発環境とツール
Apr 26, 2025 am 12:09 AM
開発環境におけるPythonとJavaScriptの両方の選択が重要です。 1)Pythonの開発環境には、Pycharm、Jupyternotebook、Anacondaが含まれます。これらは、データサイエンスと迅速なプロトタイピングに適しています。 2)JavaScriptの開発環境には、フロントエンドおよびバックエンド開発に適したnode.js、vscode、およびwebpackが含まれます。プロジェクトのニーズに応じて適切なツールを選択すると、開発効率とプロジェクトの成功率が向上する可能性があります。
 Python vs. C:重要な違いを理解します
Apr 21, 2025 am 12:18 AM
Python vs. C:重要な違いを理解します
Apr 21, 2025 am 12:18 AM
PythonとCにはそれぞれ独自の利点があり、選択はプロジェクトの要件に基づいている必要があります。 1)Pythonは、簡潔な構文と動的タイピングのため、迅速な開発とデータ処理に適しています。 2)Cは、静的なタイピングと手動メモリ管理により、高性能およびシステムプログラミングに適しています。
