

XML とは何ですか? XMLの説明例

ディレクトリ構造:
DOM: (Document Object Model) は、W3C 組織が推奨する XML を処理する方法です。このメソッドを使用して XML ドキュメントを解析すると、ドキュメント内のすべての要素間の階層関係に従ってメモリ内にツリー構造が構築されます。したがって、メモリに大きな負荷がかかり、解析と読み取りが遅くなります。利点は、ノードの内容を走査して変更できることです。
SAX: (Simple API for XML) は XML 解析の代替手段です。 DOM と比較すると、解析速度が速く、メモリ負荷が低いという欠点は、ノードの内容を変更できないことです。
2.2 dom4j を使用して XML を解析する
dom4j を使用して XML を解析する前に、作成者のような関連ツール パッケージをインポートする必要があります:
dom4j-1.6.1.jarパッケージ
2.2.1 dom4j の API
//创建SAXReader,是dom4j包提供的解析器SAXReader reader=new SAXReader();//读取指定的文件Document doc=reader.read(new File(filename)); Document Document getRootElement() 用于获取根元素 Element Element element(String name) 获取元素下指定名称的子元素 List<Element> elements() 获取元素下所有的子元素 String getName() 获取元素名 String getText() 获取元素文本内容 String elementText(String name) 获取子元素文本内容 Attribute attribute(String) 获取元素的属性 String attributeValue(String name) 获取元素的属性值 Attribute String getName() 获取属性的名字 String getValue() 获取属性的值
2.2 .2 XML ファイルの内容全体を出力します
<?xml version="1.0" encoding="utf-8" ?><books id="a"> <book id="b"><name id="c_1" name="c_2">三国演绎</name><author id="d_1" name="d_2" >罗贯中</author><price id="e">58.8</price> </book> <book id="f_1" name="f_2"><name id="g">水浒传</name><author id="h">施耐庵</author><price id="i">49.8</price> </book> <book id="j_1" name="j_2"><name id="k">西游记</name><author id="l">吴承恩</author><price id="m">100.1</price><order>1</order> </book></books>
jaxen-1.1-beta-6.jar
2.3.1 XPath API
import java.io.File;import java.util.List;import org.dom4j.Attribute;import org.dom4j.Document;import org.dom4j.Element;import org.dom4j.io.SAXReader;public class ParseXML {public static void main(String[] args) {//创建SAXReader对象SAXReader saxr=new SAXReader();
Document docu=null;try{//读取指定的文件,相对于项目路径docu=saxr.read(new File("pricties.xml"));//获得元素的文件的根节点Element e=docu.getRootElement();
searchAllElement(e);
}catch(Exception e){
e.printStackTrace();
}
} public static void searchAllElement(Element e){//获得当前元素下的所有子元素,并存储到集合中List<Element> elements=e.elements();
System.out.print("<"+e.getName());//打印开始标记List<Attribute> atrs=e.attributes();//打印该标记下的所有属性for(Attribute att:atrs){
System.out.print(" "+att.getName()+"=\""+att.getValue()+"\"");
}
System.out.println(">"); //如果集合的大小为0,表示该集合下没有子元素了if(elements.size()==0){
System.out.println(e.getText());//打印文本信息System.out.println("</"+e.getName()+">");//打印结束标记return;//退出当前层方法 } //递归每一个子元素for(Element ele:elements){
searchAllElement(ele);
}
System.out.println("</"+e.getName()+">");//打印结束标记 }
}
2.3.2 XPath的路径表达式
2.3.2.1 XPath的路径表达式规则
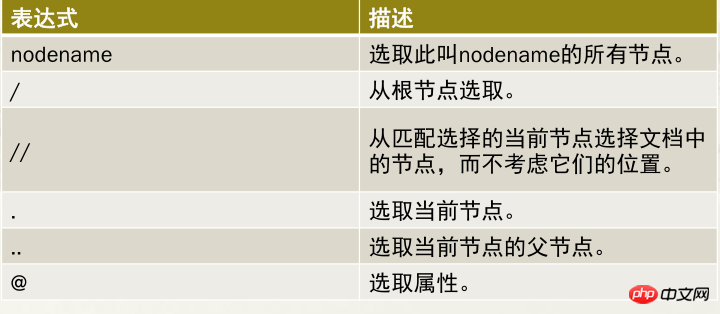
2.3.2.2 XPath的路径表达式应用案例
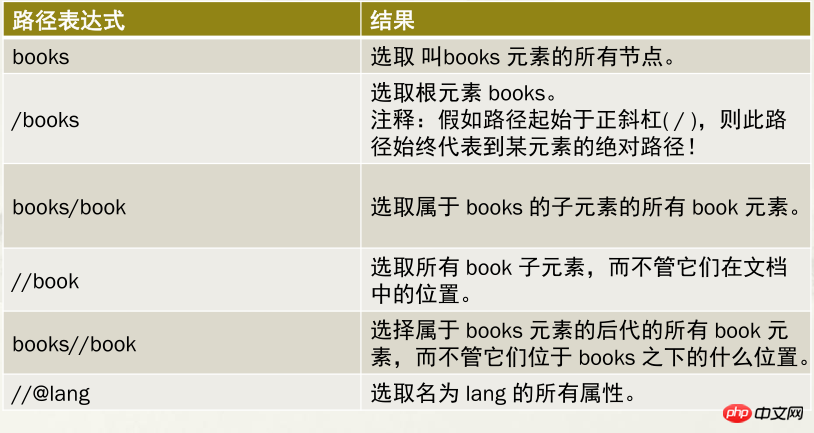
2.3.3 通配符
2.3.3.1 通配符规则

2.3.3.2 通配符应用案例

2.3.4 谓语
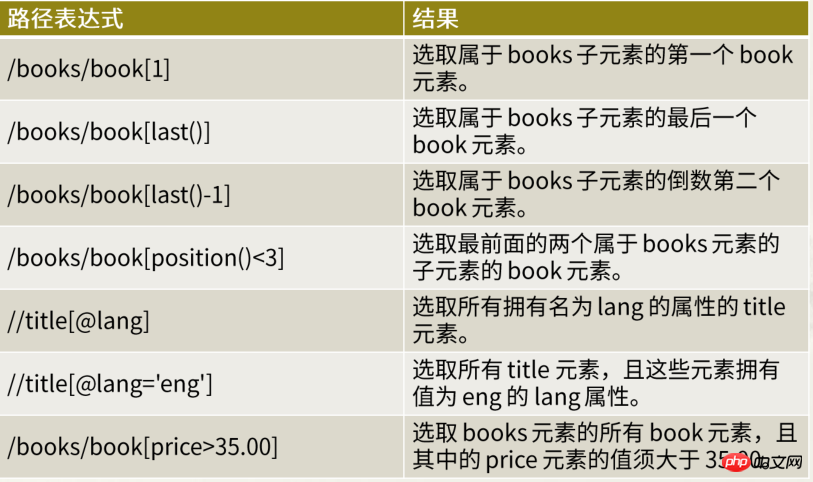
2.3.4.1 谓语规则
谓语是用来查找某个特定的节点或是包含某个指定的值的节点
谓语被嵌在方括号中
2.3.4.2 谓语应用案例
3 java写XML文件
3.1 将一个带有书籍信息的List集合解析为XML文件


package com.xdl.xml;public class Book {private String name;private String author;private String price;public Book() {super();
}public Book(String name, String author, String price) {super();
setName(name);
setAuthor(author);
setPrice(price);
}/** * @return the name */public String getName() {return name;
}/** * @param name the name to set */public void setName(String name) {this.name = name;
}/** * @return the author */public String getAuthor() {return author;
}/** * @param author the author to set */public void setAuthor(String author) {this.author = author;
}/** * @return the price */public String getPrice() {return price;
}/** * @param price the price to set */public void setPrice(String price) {this.price = price;
}
}

package com.xdl.xml;import java.io.File;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.util.ArrayList;import java.util.List;import org.dom4j.Document;import org.dom4j.DocumentHelper;import org.dom4j.Element;import org.dom4j.io.XMLWriter;public class WriteXML {public static void main(String[] args) {//创建一个Book集合用于存储书籍信息List<Book> list_books=new ArrayList<Book>();//插入书籍信息for(int i=0;i<6;i++){
Book book=new Book("jame"+i,"author"+i,""+i);
list_books.add(book);
} //创建一个文档对象Document doc=DocumentHelper.createDocument();//创建一个根节点Element books=DocumentHelper.createElement("books"); //获得书籍集合的大小int size=list_books.size();for(int i=0;i<size;i++){//创建一个book节点Element book=books.addElement("book");//创建一个name节点Element name=book.addElement("name");//创建一个author节点Element author=book.addElement("author");//创建一个price节点Element price=book.addElement("price");
name.setText(list_books.get(i).getName());
author.setText(list_books.get(i).getAuthor());
price.setText(list_books.get(i).getPrice());
}//设置文档根节点 doc.setRootElement(books); try {//如果文件不存在,会自动创建FileOutputStream fos = new FileOutputStream(new File("books.xml"));
XMLWriter xmlw = new XMLWriter(fos);
xmlw.write(doc);
xmlw.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}4 Schema和DTD的区别
Schema是对XML文档结构的定义和描述,其主要的作用是用来约束XML文件,并验证XML文件有效性。DTD的作用是定义XML的合法构建模块,它使用一系列的合法元素来定义文档结构。它们之间的区别有下面几点:
1、Schema本身也是XML文档,DTD定义跟XML没有什么关系,Schema在理解和实际应用有很多的好处。
2、DTD文档的结构是“平铺型”的,如果定义复杂的XML文档,很难把握各元素之间的嵌套关系;Schema文档结构性强,各元素之间的嵌套关系非常直观。
3、DTD只能指定元素含有文本,不能定义元素文本的具体类型,如字符型、整型、日期型、自定义类型等。Schema在这方面比DTD强大。
4、Schema支持元素节点顺序的描述,DTD没有提供无序情况的描述,要定义无序必需穷举排列的所有情况。Schema可以利用xs:all来表示无序的情况。
5、对命名空间的支持。DTD无法利用XML的命名空间,Schema很好满足命名空间。并且,Schema还提供了include和import两种引用命名空间的方法。
5 参考文章
Schema和DTD的区别
以上がXML とは何ですか? XMLの説明例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7530
7530
 15
1378
52
82
11
21
76
15
1378
52
82
11
21
76

 C++のmode関数の詳しい解説
Nov 18, 2023 pm 03:08 PM
C++のmode関数の詳しい解説
Nov 18, 2023 pm 03:08 PM
C++ のモード関数の詳細な説明 統計において、モードとは、一連のデータ内で最も頻繁に現れる値を指します。 C++ 言語では、モード関数を記述することによって、任意のデータセット内のモードを見つけることができます。モード関数はさまざまな方法で実装できます。一般的に使用される 2 つの方法を以下で詳しく紹介します。 1 つ目の方法は、ハッシュ テーブルを使用して各数値の出現回数をカウントすることです。まず、各数値をキー、出現回数を値とするハッシュ テーブルを定義する必要があります。次に、特定のデータセットに対して次を実行します。
 Win11での管理者権限の取得について詳しく解説
Mar 08, 2024 pm 03:06 PM
Win11での管理者権限の取得について詳しく解説
Mar 08, 2024 pm 03:06 PM
Windows オペレーティング システムは世界で最も人気のあるオペレーティング システムの 1 つであり、その新バージョン Win11 が大きな注目を集めています。 Win11 システムでは、管理者権限の取得は重要な操作であり、管理者権限を取得すると、ユーザーはシステム上でより多くの操作や設定を実行できるようになります。この記事では、Win11システムで管理者権限を取得する方法と、権限を効果的に管理する方法を詳しく紹介します。 Win11 システムでは、管理者権限はローカル管理者とドメイン管理者の 2 種類に分かれています。ローカル管理者はローカル コンピュータに対する完全な管理権限を持っています
 Oracle SQLの除算演算の詳細説明
Mar 10, 2024 am 09:51 AM
Oracle SQLの除算演算の詳細説明
Mar 10, 2024 am 09:51 AM
OracleSQL の除算演算の詳細な説明 OracleSQL では、除算演算は一般的かつ重要な数学演算であり、2 つの数値を除算した結果を計算するために使用されます。除算はデータベース問合せでよく使用されるため、OracleSQL での除算演算とその使用法を理解することは、データベース開発者にとって重要なスキルの 1 つです。この記事では、OracleSQL の除算演算に関する関連知識を詳細に説明し、読者の参考となる具体的なコード例を示します。 1. OracleSQL での除算演算
 C++の剰余関数の詳しい解説
Nov 18, 2023 pm 02:41 PM
C++の剰余関数の詳しい解説
Nov 18, 2023 pm 02:41 PM
C++ の剰余関数の詳しい説明 C++ では、剰余演算子 (%) を使用して、2 つの数値を除算した余りを計算します。これは、オペランドが任意の整数型 (char、short、int、long など) または浮動小数点数型 (float、double など) になる二項演算子です。剰余演算子は、被除数と同じ符号の結果を返します。たとえば、整数の剰余演算の場合、次のコードを使用して実装できます。
 Vue.nextTick関数の使い方と非同期更新での応用について詳しく解説
Jul 26, 2023 am 08:57 AM
Vue.nextTick関数の使い方と非同期更新での応用について詳しく解説
Jul 26, 2023 am 08:57 AM
Vue.nextTick 関数の使い方と非同期更新での応用について詳しく説明 Vue の開発では、DOM を変更した直後にデータを更新したり、関連する操作が必要になったりするなど、データを非同期で更新する必要がある状況によく遭遇します。データが更新された直後に実行されます。このような問題を解決するために登場したのが、Vue が提供する .nextTick 関数です。この記事では、Vue.nextTick 関数の使用法を詳しく紹介し、コード例と組み合わせて、非同期更新でのアプリケーションを説明します。 1.Vue.nex
 php-fpmのチューニング方法を詳しく解説
Jul 08, 2023 pm 04:31 PM
php-fpmのチューニング方法を詳しく解説
Jul 08, 2023 pm 04:31 PM
PHP-FPM は、PHP のパフォーマンスと安定性を向上させるために一般的に使用される PHP プロセス マネージャーです。ただし、高負荷環境では、PHP-FPM のデフォルト設定ではニーズを満たせない場合があるため、チューニングが必要です。この記事では、PHP-FPM のチューニング方法を詳しく紹介し、いくつかのコード例を示します。 1. プロセスの数を増やす デフォルトでは、PHP-FPM はリクエストを処理するために少数のプロセスのみを開始します。高負荷環境では、プロセス数を増やすことで PHP-FPM の同時実行性を高めることができます。
 PHPモジュロ演算子の役割と使い方を詳しく解説
Mar 19, 2024 pm 04:33 PM
PHPモジュロ演算子の役割と使い方を詳しく解説
Mar 19, 2024 pm 04:33 PM
PHP のモジュロ演算子 (%) は、2 つの数値を除算した余りを取得するために使用されます。この記事では、モジュロ演算子の役割と使用法について詳しく説明し、読者の理解を深めるために具体的なコード例を示します。 1. モジュロ演算子の役割 数学では、整数を別の整数で割ると、商と余りが得られます。たとえば、10 を 3 で割ると、商は 3 になり、余りは 1 になります。モジュロ演算子は、この剰余を取得するために使用されます。 2. モジュロ演算子の使用法 PHP では、% 記号を使用してモジュロを表します。
 Linuxシステムコールsystem()関数の詳細説明
Feb 22, 2024 pm 08:21 PM
Linuxシステムコールsystem()関数の詳細説明
Feb 22, 2024 pm 08:21 PM
Linux システム コール system() 関数の詳細説明 システム コールは、Linux オペレーティング システムの非常に重要な部分であり、システム カーネルと対話する方法を提供します。その中でも、system()関数はよく使われるシステムコール関数の一つです。この記事では、system() 関数の使用法を詳しく紹介し、対応するコード例を示します。システム コールの基本概念 システム コールは、ユーザー プログラムがオペレーティング システム カーネルと対話する方法です。ユーザープログラムはシステムコール関数を呼び出してオペレーティングシステムを要求します。
