

プリオーダートラバーサルとインオーダートラバーサル後のシーケンスを通じてバイナリツリーを復元します。
ルート-左の子-右の子の順序に基づいています。そして、最初に確認できることは、プレオーダー走査シーケンスの最初の番号であるということです。はルート ノードであり、その順序で走査は、左の子-ルート-右の子の順序に基づきます。事前順序走査でルート ノードを確認したので、順序走査でルート ノードの位置を見つけるだけで、左側のサブツリーに属するノードと左側のサブツリーに属するノードを簡単に区別できます。右のサブツリー。以下に示すように:
番号 1 をルート ノードとして決定し、その後、順序内走査の走査順序に従って決定します。順序内走査シーケンスでは、番号 1 の左側がすべて残ります。サブツリー ノード、およびすべての右サブツリーは右サブツリーです。左サブツリー ノードの数から、事前順序走査シーケンスのルート ノードからの 3 つの連続する番号が左サブツリーに属し、残りが右サブツリーであると結論付けることができます。このようにして、最終的に子ノードが見つからなくなるまで、上記の手順を左サブツリーと右サブツリーの順序で繰り返します。
1 package com.tree.traverse; 2 3 import java.util.ArrayList; 4 import java.util.List; 5 6 /** 7 * @author Caijh 8 * 9 * 2017年6月2日 下午7:21:10 10 */ 11 12 public class BuildTreePreOrderInOrder { 13 14 /** 15 * 1
16 * / \ 17 * 3 5
18 * / \ 19 * 7 11 20 * /
21 * 9
22 */ 23 public static int treeNode = 0;//记录先序遍历节点的个数 24 private List<Node> nodeList = new ArrayList<>();//层次遍历节点的队列 25 public static void main(String[] args) { 26 BuildTreePreOrderInOrder build = new BuildTreePreOrderInOrder(); 27 int[] preOrder = { 1, 3, 7, 9, 5, 11}; 28 int[] inOrder = { 9, 7, 3, 1, 5, 11}; 29 30 treeNode = preOrder.length;//初始化二叉树的节点数 31 Node root = build.buildTreePreOrderInOrder(preOrder, 0, preOrder.length - 1, inOrder, 0, preOrder.length - 1); 32 System.out.print("先序遍历:"); 33 build.preOrder(root); 34 System.out.print("\n中序遍历:"); 35 build.inOrder(root); 36 System.out.print("\n原二叉树:\n"); 37 build.prototypeTree(root); 38 } 39 40 /** 41 * 分治法 42 * 通过先序遍历结果和中序遍历结果还原二叉树 43 * @param preOrder 先序遍历结果序列 44 * @param preOrderBegin 先序遍历起始位置下标 45 * @param preOrderEnd 先序遍历末尾位置下标 46 * @param inOrder 中序遍历结果序列 47 * @param inOrderBegin 中序遍历起始位置下标 48 * @param inOrderEnd 中序遍历末尾位置下标 49 * @return 50 */ 51 public Node buildTreePreOrderInOrder(int[] preOrder, int preOrderBegin, int preOrderEnd, int[] inOrder, int inOrderBegin, int inOrderEnd) { 52 if (preOrderBegin > preOrderEnd || inOrderBegin > inOrderEnd) { 53 return null; 54 } 55 int rootData = preOrder[preOrderBegin];//先序遍历的第一个字符为当前序列根节点 56 Node head = new Node(rootData); 57 int divider = findIndexInArray(inOrder, rootData, inOrderBegin, inOrderEnd);//找打中序遍历结果集中根节点的位置 58 int offSet = divider - inOrderBegin - 1;//计算左子树共有几个节点,节点数减一,为数组偏移量 59 Node left = buildTreePreOrderInOrder(preOrder, preOrderBegin + 1, preOrderBegin + 1 + offSet, inOrder, inOrderBegin,inOrderBegin + offSet); 60 Node right = buildTreePreOrderInOrder(preOrder, preOrderBegin + offSet + 2, preOrderEnd, inOrder, divider + 1, inOrderEnd); 61 head.left = left; 62 head.right = right; 63 return head; 64 } 65 /** 66 * 通过先序遍历找到的rootData根节点,在中序遍历结果中区分出:中左子树和右子树 67 * @param inOrder 中序遍历的结果数组 68 * @param rootData 根节点位置 69 * @param begin 中序遍历结果数组起始位置下标 70 * @param end 中序遍历结果数组末尾位置下标 71 * @return return中序遍历结果数组中根节点的位置 72 */ 73 public int findIndexInArray(int[] inOrder, int rootData, int begin, int end) { 74 for (int i = begin; i <= end; i++) { 75 if (inOrder[i] == rootData) 76 return i; 77 } 78 return -1; 79 } 80 /** 81 * 二叉树先序遍历结果 82 * @param n 83 */ 84 public void preOrder(Node n) { 85 if (n != null) { 86 System.out.print(n.val + ","); 87 preOrder(n.left); 88 preOrder(n.right); 89 } 90 } 91 /** 92 * 二叉树中序遍历结果 93 * @param n 94 */ 95 public void inOrder(Node n) { 96 if (n != null) { 97 inOrder(n.left); 98 System.out.print(n.val + ","); 99 inOrder(n.right);100 }101 }102 /**103 * 还原后的二叉树104 * 二叉数层次遍历105 * 基本思想:106 * 1.因为推导出来的二叉树是保存在Node类对象的子对象里面的,(类似于c语言的结构体)如果通过递归实现层次遍历的话,不容易实现107 * 2.这里采用List队列逐层保存Node对象节点的方式实现对二叉树的层次遍历输出108 * 3.如果父节点的位置为i,那么子节点的位置为,2i 和 2i+1;依据这个规律逐层遍历,通过保存的父节点,找到子节点。并保存,不断向下遍历保存。109 * @param tree110 */111 public void prototypeTree(Node tree){112 //用list存储层次遍历的节点113 if(tree !=null){114 if(tree!=null)115 nodeList.add(tree);116 nodeList.add(tree.left);117 nodeList.add(tree.right);118 int count=3;119 //从第三层开始120 for(int i=3;count<treeNode;i++){121 //第i层第一个子节点的父节点的位置下标122 int index = (int) Math.pow(2, i-1-1)-1;123 /**124 * 二叉树的每一层节点数遍历125 * 因为第i层的最大节点数为2的i-1次方个,126 */127 for(int j=1;j<=Math.pow(2, i-1);){128 //计算有效的节点的个数,和遍历序列的总数做比较,作为判断循环结束的标志129 if(nodeList.get(index).left!=null)130 count++;131 if(nodeList.get(index).right!=null)132 count++;133 nodeList.add(nodeList.get(index).left);134 nodeList.add(nodeList.get(index).right);135 index++;136 if(count>=treeNode)//当所有有效节点都遍历到了就结束遍历137 break;138 j+=2;//每次存储两个子节点,所以每次加2139 }140 }141 int flag=0,floor=1;142 for(Node node:nodeList){143 if(node!=null)144 System.out.print(node.val+" ");145 else146 System.out.print("# ");//#号表示空节点147 flag++;148 /**149 * 逐层遍历输出二叉树150 *
151 */152 if(flag>=Math.pow(2, floor-1)){153 flag=0;154 floor++;155 System.out.println();156 }157 }158 }159 }160 /**161 * 内部类162 * 1.每个Node类对象为一个节点,163 * 2.每个节点包含根节点,左子节点和右子节点164 */165 class Node {166 Node left;167 Node right;168 int val;169 public Node(int val) {170 this.val = val;171 }172 }173 }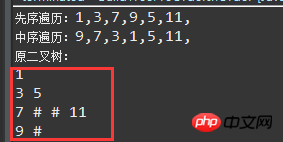
* 1. 派生した二分木であるためNode クラス オブジェクトに格納されている子です。 オブジェクトでは (C 言語の構造と同様)、再帰による階層トラバーサルを実装するのは簡単ではありません
* 2. ここでは、List キューを使用して Node オブジェクトのノード層を保存していますバイナリ ツリー
* 3 の階層トラバーサル出力を達成するには、レイヤーごとに実行します。親ノードの位置が i の場合、子ノードの位置は、このルールに従って 2i と 2i+1 になります。保存された親ノードから子ノードを見つけます。そして保存し、下方向に移動し続けて保存します。

以上がプリオーダートラバーサルとインオーダートラバーサル後のシーケンスを通じてバイナリツリーを復元します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7456
7456
 15
1376
52
77
11
17
10
15
1376
52
77
11
17
10

 Java フォルダーをループしてすべてのファイル名を取得する方法
Mar 29, 2024 pm 01:24 PM
Java フォルダーをループしてすべてのファイル名を取得する方法
Mar 29, 2024 pm 01:24 PM
Java は、強力なファイル処理機能を備えた人気のあるプログラミング言語です。 Java では、フォルダーを走査してすべてのファイル名を取得するのが一般的な操作であり、これは特定のディレクトリー内のファイルを迅速に見つけて処理するのに役立ちます。この記事では、Java でフォルダーを走査してすべてのファイル名を取得するメソッドを実装する方法と、具体的なコード例を紹介します。 1. 再帰的メソッドを使用してフォルダーを走査する 再帰的メソッドを使用してフォルダーを走査することができます。再帰的メソッドはそれ自体を呼び出す方法であり、フォルダーを効果的に走査できます。
 PHP glob() 関数の使用例: 指定したフォルダー内のすべてのファイルを走査する
Jun 27, 2023 am 09:16 AM
PHP glob() 関数の使用例: 指定したフォルダー内のすべてのファイルを走査する
Jun 27, 2023 am 09:16 AM
PHPglob() 関数の使用例: 指定したフォルダー内のすべてのファイルを走査する PHP 開発では、バッチ操作やファイルの読み取りを実装するために、指定したフォルダー内のすべてのファイルを走査する必要がよくあります。この要件を達成するには、PHP の glob() 関数が使用されます。 glob()関数は、ワイルドカードのマッチングパターンを指定することで、指定したフォルダー内の条件を満たすすべてのファイルのパス情報を取得できます。この記事では、glob() 関数を使用して、指定したフォルダー内のすべてのファイルを反復処理する方法を説明します。
 Java Iterator と Iterable の詳細な比較: 長所と短所の分析
Feb 19, 2024 pm 04:20 PM
Java Iterator と Iterable の詳細な比較: 長所と短所の分析
Feb 19, 2024 pm 04:20 PM
概念的な違い: イテレータ: イテレータは、コレクションから値を取得するイテレータを表すインターフェイスです。 MoveNext()、Current()、Reset() などのメソッドを提供し、コレクション内の要素を横断して現在の要素を操作できるようにします。 Iterable: Iterable は、反復可能なオブジェクトを表すインターフェイスでもあります。これは、コレクション内の要素の走査を容易にする Iterator オブジェクトを返す Iterator() メソッドを提供します。使用法: Iterator: Iterator を使用するには、まず Iterator オブジェクトを取得し、次に MoveNext() メソッドを呼び出して次のオブジェクトに移動する必要があります。
 Python 3.x で os モジュールを使用してディレクトリ内のファイルを走査する方法
Jul 29, 2023 pm 02:57 PM
Python 3.x で os モジュールを使用してディレクトリ内のファイルを走査する方法
Jul 29, 2023 pm 02:57 PM
Python3.x で os モジュールを使用してディレクトリ内のファイルを走査する方法 Python では、os モジュールを使用してファイルやディレクトリを操作できます。 os モジュールは、Python 標準ライブラリの重要なモジュールであり、オペレーティング システム関連の多くの機能を提供します。この記事では、os モジュールを使用してディレクトリ内のすべてのファイルを反復処理する方法を説明します。まず、os モジュールをインポートする必要があります。 importos 次に、os.walk() 関数を使用してディレクトリを移動します。
 C++ でリンク リストを再帰的に挿入して走査する
Sep 10, 2023 am 09:21 AM
C++ でリンク リストを再帰的に挿入して走査する
Sep 10, 2023 am 09:21 AM
リンクされたリストを形成するために使用される整数値を取得します。このタスクは、最初に単一リンク リストを挿入し、次に再帰的方法を使用して走査することです。 head が NULL の場合、最後にノードを再帰的に追加します。 → head にノードを追加します。それ以外の場合、head に追加します (head → next) head が NULL の場合、ノードを再帰的に走査します。 → それ以外の場合は終了します。 print (head → next) 入力例 −1-2-7-9 -10 出力 出力強>- リンク リスト: 1→2→7→9→10→NULL 入力-12-21-17-94-18 出力- リンク リスト: 12→21→17→94→18→NULL以下のプログラム メソッドは次のとおりです。 このメソッドでは、関数を使用してノードを追加し、単一リンクされたリストを走査して渡します。
 Java Iterator と Iterable: コレクション トラバーサルの鍵を解き明かす
Feb 20, 2024 am 10:27 AM
Java Iterator と Iterable: コレクション トラバーサルの鍵を解き明かす
Feb 20, 2024 am 10:27 AM
Iterator の概要Iterator は、コレクションを走査するための Java のインターフェイスです。これは、コレクション内の要素に順次アクセスできるようにする一連のメソッドを提供します。 Iterator を使用すると、List、Set、Map などのコレクション型を反復処理できます。デモコード: Listlist=newArrayList();list.add("one");list.add("two");list.add("three");Iteratoriterator=list.iterator();while(iter
 Python を使用してバイナリ ツリー トラバーサルを実装する方法
Jun 09, 2023 pm 09:12 PM
Python を使用してバイナリ ツリー トラバーサルを実装する方法
Jun 09, 2023 pm 09:12 PM
一般的に使用されるデータ構造として、バイナリ ツリーはデータの保存、検索、並べ替えによく使用されます。バイナリ ツリーの走査は、非常に一般的な操作の 1 つです。シンプルで使いやすいプログラミング言語である Python には、バイナリ ツリー トラバーサルを実装するためのメソッドが多数あります。この記事では、Python を使用してバイナリ ツリーの事前順序、順序内、および順序後の走査を実装する方法を紹介します。バイナリ ツリーの基本 バイナリ ツリーの探索方法を学ぶ前に、バイナリ ツリーの基本概念を理解する必要があります。バイナリ ツリーはノードで構成され、各ノードには値と 2 つの子ノード (左の子ノードと右の子ノード) があります。
 Java Iterator と Iterable: Java コレクション トラバーサルの謎を解く
Feb 19, 2024 pm 11:50 PM
Java Iterator と Iterable: Java コレクション トラバーサルの謎を解く
Feb 19, 2024 pm 11:50 PM
Iterator インターフェイス Iterator インターフェイスは、Java コレクション フレームワークで定義されたインターフェイスであり、コレクション要素を走査するための一連のメソッドを提供します。 Iterator インターフェイスは、次の主要なメソッドを定義します。 hasNext(): 次の要素が存在するかどうかを示すブール値を返します。 next(): 次の要素を返します。次の要素がない場合は、NoSuchElementException がスローされます。 Remove(): 現在ポイントされている要素を削除します。以下は、Iterator インターフェイスを使用してコレクションを走査するためのサンプル コードです。 Listlist=newArrayList();list
