

優れた Web クローラーを実行するにはどうすればよいでしょうか?

Web クローラーの本質は、実際にはインターネットからデータを「盗む」ことです。 Web クローラーを通じて、必要なリソースを収集できますが、同様に、不適切な使用によって重大な問題が発生する可能性もあります。
したがって、Web クローラーを使用する場合は、「正しい方法で盗む」必要があります。
Web クローラーは主に次の 3 つのカテゴリに分類されます:
1. このタイプの Web クローラーの場合、主にリクエスト ライブラリを使用して実装できます。 Web ページのクロールに使用されます
2. このタイプの Web クローラーでは、主に Web サイトまたは一連の Web サイトをクロールするために使用されます。 、検索エンジン、現時点ではクロール速度が重要です。カスタマイズされた開発が必要です。これは主にネットワーク全体をクロールするために使用され、通常は Baidu、Google 検索などのネットワーク全体の検索エンジンを構築します。
これら 3 つのタイプのうち、最初のタイプが最も一般的で、そのほとんどは Web ページをクロールする小規模なクローラーです。
ウェブクローラーにも反対意見がたくさんあります。 Web クローラーは常にサーバーにリクエストを送信するため、サーバーのパフォーマンスに影響を与え、サーバーへの嫌がらせを引き起こし、Web サイト管理者の作業負荷が増加するからです。
サーバーへの嫌がらせに加えて、Web クローラーは法的リスクを引き起こす可能性もあります。サーバー上のデータには財産権があるため、営利目的に使用すると法的リスクが生じます。 さらに、Web クローラーもユーザーのプライバシー漏洩を引き起こす可能性があります。
まとめると、Web クローラーのリスクは主に次の 3 点に起因します:
- サーバーへのパフォーマンスハラスメント
- コンテンツレベルでの法的リスク
- 個人のプライバシーの漏洩
実際には、一部の大規模 Web サイトでは Web クローラーに関連する制限が課されており、Web クローラーはインターネット全体で標準化可能な機能ともみなされています。
一般的なサーバーの場合、次の 2 つの方法で Web クローラーを制限できます。 1. Web サイトの所有者が特定の技術的能力を持っている場合は、ソース レビューを通じて Web クローラーを制限できます。
ソースレビューは通常、User-Agent の判断によって制限されます。この記事では 2 番目のタイプに焦点を当てます。
2. ロボット プロトコルを使用して、Web クローラーに遵守する必要があるルール、どのルールがクロール可能でどのルールが許可されないかを伝え、すべてのクローラーがこのプロトコルに従うように要求します。
2 番目の方法は、ロボット協定は推奨ですが、拘束力はありませんが、法的なリスクが生じる可能性があります。これら 2 つの方法を通じて、Web クローラーに対する効果的な道徳的および技術的制限がインターネット上に形成されます。
それでは、
Web クローラーを作成するときは、Web サイトの管理者による Web サイトのリソースの管理を尊重する必要があります。インターネットでは、一部の Web サイトには Robots プロトコルがなく、すべてのデータをクロールできますが、主流の Web サイトの大部分は、関連する制限付きで Robots プロトコルをサポートしています。以下では、基本的な構文について詳しく説明します。ロボットプロトコルの。
ロボットプロトコル (ロボット除外標準、Web クローラー除外標準): 機能: Web サイトは、どのページがクロールできるか、どのページがクロールできないかを Web クローラーに伝えます。
フォーム: Web サイトのルート ディレクトリにある robots.txt ファイル。
ロボットプロトコルの基本構文: * はすべてを表し、/ はルートディレクトリを表します。
たとえば、PMCAFF のロボット プロトコル:
ユーザー エージェント: *Disallow: /article/edit
Disallow: /discuss/write
Disallow: /discuss/edit
1 行目の
User-agent:* は、すべての Web クローラーが次のプロトコルに準拠する必要があることを意味します。 2 行目の
Disallow: /article/edit は、すべての Web クローラーが記事/編集にアクセスできないことを意味します。以下の内容は他と同様です。
JD.com のロボット プロトコルを観察すると、User-agent: EtaoSpider、Disallow: / があることがわかります。ここで、EtaoSpider は悪意のあるクローラーであり、JD.com のリソースをクロールすることは許可されていません。 EnUser-agent:*
Disallow: /?*Disallow: /pop/*.html
disallow: /pinpai/ *.html?*
User-agent: EtaoSpider
不許可: /
ユーザーエージェント: HuihuiSpider
不許可: /
ユーザーエージェント: GwdangSpider
不許可: /
ユーザーエージェント: WochachaSpider
許可しない: /
ロボット プロトコルを使用すると、Web サイトのコンテンツを規制し、どの Web クローラーがクロール可能でどのクローラーが許可されないかをすべての Web クローラーに通知できます。
ロボット プロトコルはルート ディレクトリに存在することに注意することが重要です。そのため、クロールするときはさらに注意する必要があります。
以上が優れた Web クローラーを実行するにはどうすればよいでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7486
7486
 15
1377
52
77
11
19
38
15
1377
52
77
11
19
38

![WLAN拡張モジュールが停止しました[修正]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) WLAN拡張モジュールが停止しました[修正]
Feb 19, 2024 pm 02:18 PM
WLAN拡張モジュールが停止しました[修正]
Feb 19, 2024 pm 02:18 PM
Windows コンピュータの WLAN 拡張モジュールに問題がある場合、インターネットから切断される可能性があります。この状況はイライラすることがよくありますが、幸いなことに、この記事では、この問題を解決し、ワイヤレス接続を再び正常に動作させるのに役立ついくつかの簡単な提案を提供します。 WLAN 拡張モジュールが停止しました。 WLAN 拡張モジュールが Windows コンピュータで動作を停止した場合は、次の提案に従って修正してください。 ネットワークとインターネットのトラブルシューティング ツールを実行して、ワイヤレス ネットワーク接続を無効にし、再度有効にします。 WLAN 自動構成サービスを再起動します。 電源オプションを変更します。 変更します。詳細な電源設定 ネットワーク アダプター ドライバーを再インストールする いくつかのネットワーク コマンドを実行する それでは、詳しく見てみましょう
 win11のDNSサーバーエラーの解決方法
Jan 10, 2024 pm 09:02 PM
win11のDNSサーバーエラーの解決方法
Jan 10, 2024 pm 09:02 PM
インターネットにアクセスするには、インターネットに接続するときに正しい DNS を使用する必要があります。同様に、間違った DNS 設定を使用すると、DNS サーバー エラーが発生しますが、このときは、ネットワーク設定で DNS を自動的に取得するように選択することで問題を解決できます。ソリューション。 win11 ネットワーク dns サーバー エラーを解決する方法. 方法 1: DNS をリセットする 1. まず、タスクバーの [スタート] をクリックして入力し、[設定] アイコン ボタンを見つけてクリックします。 2. 次に、左側の列の「ネットワークとインターネット」オプションコマンドをクリックします。 3. 次に、右側で「イーサネット」オプションを見つけ、クリックして入力します。 4. その後、DNSサーバーの割り当ての「編集」をクリックし、最後にDNSを「自動(D)」に設定します。
 Chrome、Google ドライブ、フォトでの「ネットワーク エラーの失敗」ダウンロードを修正してください。
Oct 27, 2023 pm 11:13 PM
Chrome、Google ドライブ、フォトでの「ネットワーク エラーの失敗」ダウンロードを修正してください。
Oct 27, 2023 pm 11:13 PM
「ネットワーク エラーのダウンロードに失敗しました」問題とは何ですか?解決策を詳しく説明する前に、まず「ネットワーク エラーのダウンロードに失敗しました」問題が何を意味するのかを理解しましょう。このエラーは通常、ダウンロード中にネットワーク接続が中断された場合に発生します。この問題は、インターネット接続の弱さ、ネットワークの混雑、サーバーの問題など、さまざまな理由で発生する可能性があります。このエラーが発生すると、ダウンロードが停止し、エラー メッセージが表示されます。ネットワークエラーで失敗したダウンロードを修正するにはどうすればよいですか? 「ネットワーク エラー ダウンロードに失敗しました」というメッセージが表示されると、必要なファイルへのアクセスまたはダウンロード中に障害が発生する可能性があります。 Chrome などのブラウザを使用している場合でも、Google ドライブや Google フォトなどのプラットフォームを使用している場合でも、このエラーはポップアップ表示され、不便を引き起こします。この問題を解決し、解決するために役立つポイントを以下に示します。
 修正: WD My Cloud が Windows 11 のネットワーク上に表示されない
Oct 02, 2023 pm 11:21 PM
修正: WD My Cloud が Windows 11 のネットワーク上に表示されない
Oct 02, 2023 pm 11:21 PM
WDMyCloud が Windows 11 のネットワーク上に表示されない場合、特にそこにバックアップやその他の重要なファイルを保存している場合は、大きな問題になる可能性があります。これは、ネットワーク ストレージに頻繁にアクセスする必要があるユーザーにとって大きな問題となる可能性があるため、今日のガイドでは、この問題を永久に修正する方法を説明します。 WDMyCloud が Windows 11 ネットワークに表示されないのはなぜですか? MyCloud デバイス、ネットワーク アダプター、またはインターネット接続が正しく構成されていません。パソコンにSMB機能がインストールされていません。 Winsock の一時的な不具合がこの問題を引き起こす場合があります。クラウドがネットワーク上に表示されない場合はどうすればよいですか?問題の修正を開始する前に、いくつかの予備チェックを実行できます。
 Windows 10 の右下に地球が表示されてインターネットにアクセスできない場合はどうすればよいですか? Win10 で地球がインターネットにアクセスできない問題のさまざまな解決策
Feb 29, 2024 am 09:52 AM
Windows 10 の右下に地球が表示されてインターネットにアクセスできない場合はどうすればよいですか? Win10 で地球がインターネットにアクセスできない問題のさまざまな解決策
Feb 29, 2024 am 09:52 AM
この記事では、Win10のシステムネットワーク上に地球儀マークが表示されるがインターネットにアクセスできない問題の解決策を紹介します。この記事では、地球がインターネットにアクセスできないことを示す Win10 ネットワークの問題を読者が解決するのに役立つ詳細な手順を説明します。方法 1: 直接再起動する まず、ネットワーク ケーブルが正しく接続されていないこと、ブロードバンドが滞っていないかを確認します。ルーターまたは光モデムが停止している可能性があります。この場合は、ルーターまたは光モデムを再起動する必要があります。コンピュータ上で重要な作業が行われていない場合は、コンピュータを直接再起動できます。ほとんどの軽微な問題は、コンピュータを再起動することですぐに解決できます。ブロードバンドが滞っておらず、ネットワークが正常であると判断される場合は、別の問題です。方法 2: 1. [Win]キーを押すか、左下の[スタートメニュー]をクリックし、表示されるメニュー項目の電源ボタンの上にある歯車アイコンをクリックし、[設定]をクリックします。
 ネットワーク接続を確認してください: lol はサーバーに接続できません
Feb 19, 2024 pm 12:10 PM
ネットワーク接続を確認してください: lol はサーバーに接続できません
Feb 19, 2024 pm 12:10 PM
LOL サーバーに接続できません。ネットワークを確認してください。 近年、オンラインゲームは多くの人にとって日常的な娯楽となっています。中でも、リーグ オブ レジェンド (LOL) は非常に人気のあるマルチプレイヤー オンライン ゲームであり、数億人のプレイヤーの参加と関心を集めています。ただし、LOL をプレイしているときに、「サーバーに接続できません。ネットワークを確認してください」というエラー メッセージが表示されることがあります。これは間違いなくプレイヤーに何らかの問題をもたらします。次に、このエラーの原因と解決策について説明します。まず、LOLがサーバーに接続できない問題として考えられるのは、
 ネットワークが Wi-Fi に接続できない場合は何が起こっているのでしょうか?
Apr 03, 2024 pm 12:11 PM
ネットワークが Wi-Fi に接続できない場合は何が起こっているのでしょうか?
Apr 03, 2024 pm 12:11 PM
1. Wi-Fi パスワードを確認します。入力した Wi-Fi パスワードが正しいことを確認し、大文字と小文字の区別に注意してください。 2. Wi-Fi が適切に動作しているかどうかを確認する: Wi-Fi ルーターが正常に動作しているかどうかを確認し、同じルーターに他のデバイスを接続して、デバイスに問題があるかどうかを判断できます。 3. デバイスとルーターを再起動します。デバイスまたはルーターに誤動作やネットワークの問題が発生する場合があり、デバイスとルーターを再起動すると問題が解決する場合があります。 4. デバイスの設定を確認します。デバイスのワイヤレス機能がオンになっていて、Wi-Fi 機能が無効になっていないことを確認します。
 ICLR'24 写真なしの新しいアイデア! LaneSegNet: 車線セグメンテーション認識に基づく地図学習
Jan 19, 2024 am 11:12 AM
ICLR'24 写真なしの新しいアイデア! LaneSegNet: 車線セグメンテーション認識に基づく地図学習
Jan 19, 2024 am 11:12 AM
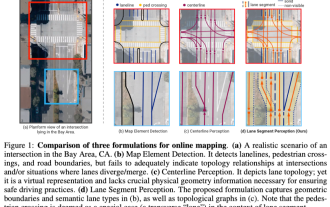
上記および自動運転システムの下流アプリケーションの重要な情報としての地図に関する著者の個人的な理解は、通常、車線またはセンターラインで表されます。ただし、既存の地図学習の文献は主に、車線の幾何学ベースのトポロジ関係の検出や中心線の感知に焦点を当てています。どちらの方法も、車線と中心線の間の固有の関係、つまり、車線が中心線を結合する関係を無視します。 1 つのモデルで 2 種類の車線を単純に予測することは学習目的において相互に排他的ですが、本論文では、幾何学的情報と位相情報をシームレスに組み合わせる新しい表現として車線セグメントを提案し、LaneSegNet を提案します。これは、車線セグメントを生成して道路構造の完全な表現を取得する最初のエンドツーエンド マッピング ネットワークです。 LaneSegNet には 2 つのレベルがあります
