

JVMのメモリ領域分割とガベージコレクションの仕組みを詳しく解説
Java コードを記述するとき、ほとんどの場合、New オブジェクトがリリースされるかどうか、いつリリースされるかを気にする必要はありません。 JVM には自動ガベージ コレクション メカニズムがあるためです。前回のブログでは、Objective-C の MRC (手動参照カウント) と ARC (自動参照カウント) のメモリ管理方法について説明しました。これについては、以下でレビューします。現在の JVM メモリ リサイクル メカニズムは参照カウントを使用せず、主に「コピー リサイクル」と「アダプティブ リサイクル」を使用します。
もちろん、上記の 2 つのアルゴリズムに加えて、他のアルゴリズムもあり、以下でも紹介します。このブログでは、まずJVM の地域分割について簡単に説明し、次にこれに基づいて JVM のガベージ コレクション メカニズムを紹介します。
1. JVM メモリ領域分割の簡単な説明
もちろん、この部分では JVM メモリ領域の分割について簡単に説明し、以下のガベージ コレクション メカニズムの拡張への道を開きます。もちろん、JVMのメモリ領域の分割についてはインターネット上に詳しい情報がたくさんありますので、ご自身でググってみてください。 JVMのメモリ領域の分割を基に、以下の図を簡単に描いてみました。領域は主に2つの大きなブロックに分かれており、1つはヒープで、C言語のmallocの割り当て方法はヒープ領域から取得されます。ガベージ コレクターは主にヒープ領域のメモリをリサイクルします。
もう一つは非ヒープ領域で、非ヒープ領域には主にローカルコードをコンパイルして保存するための「コードキャッシュ領域(Code Cache)」と、 JVM 独自の静的データを保存します。Perm Gen)、メソッド パラメーターのローカル変数への参照を保存する「Java 仮想マシン スタック (JVM スタック)」および「ローカル メソッド スタック (ローカル メソッド スタック)」メソッド呼び出しの順序。
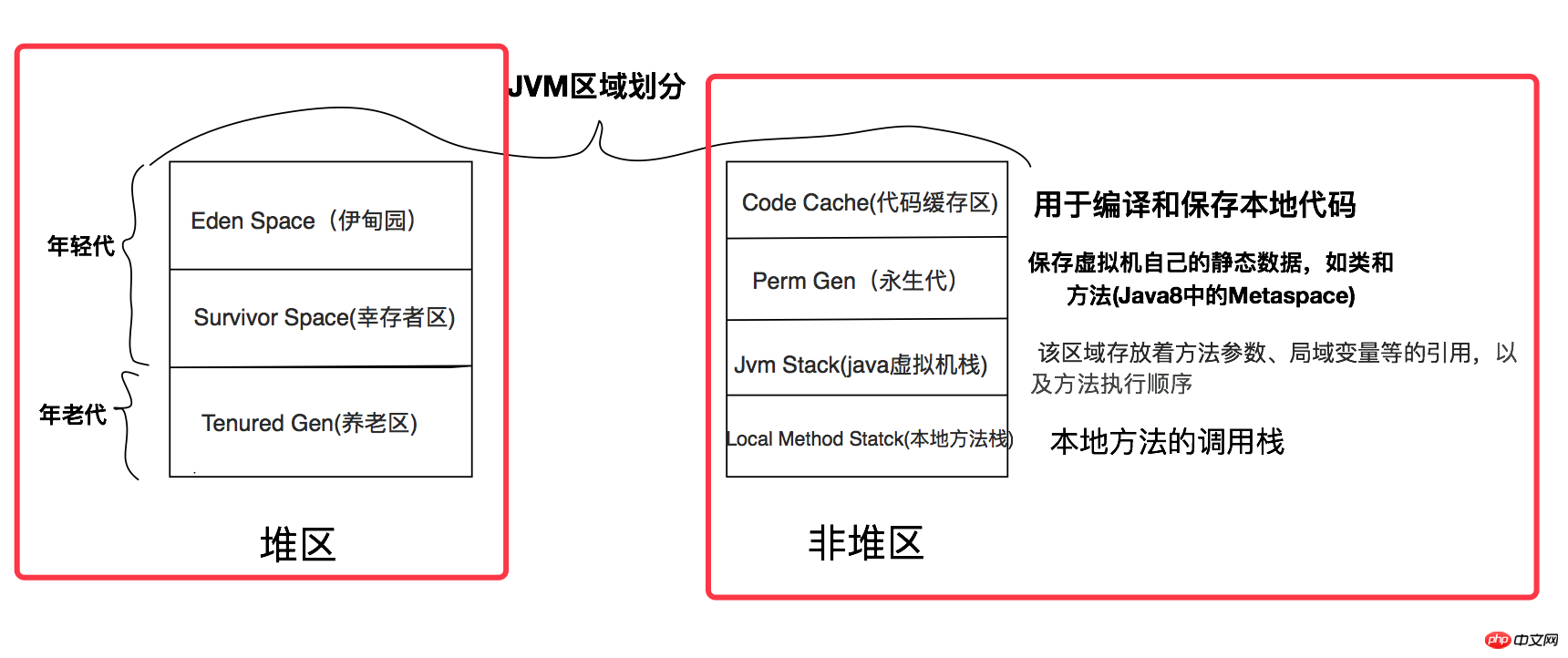 ガベージコレクターは主にヒープ領域内の未使用のメモリ領域を回収し、該当する領域を整理します。ヒープ領域はオブジェクトメモリの生存時間やオブジェクトのサイズに基づいて「
ガベージコレクターは主にヒープ領域内の未使用のメモリ領域を回収し、該当する領域を整理します。ヒープ領域はオブジェクトメモリの生存時間やオブジェクトのサイズに基づいて「
」と「古い世代」に分けられます。 「若い世代」のオブジェクトは不安定でゴミが発生しやすいのに対し、「古い世代」のオブジェクトは比較的安定していてゴミが発生しにくいです。分割する理由は、異なる領域のメモリ ブロックの特性に応じて、異なるメモリ回復アルゴリズムが採用され、ヒープ領域でのガベージ コレクションの効率を向上させるためです。以下に詳しく紹介します。
2. 一般的なメモリ再利用アルゴリズムの紹介
上記では、JVM におけるメモリ領域の分割について簡単に理解しました。次に、いくつかの一般的なメモリ再利用アルゴリズムを見てみましょう。もちろん、以下で紹介するメモリ再利用アルゴリズムは JVM で使用されるだけではなく、OC でのメモリ再利用方法についても検討します。主に「リファレンスカウントリサイクル」「コピーリサイクル」「マーク分別リサイクル」「世代リサイクル」が挙げられます。
1. 参照カウントのメモリ リサイクル
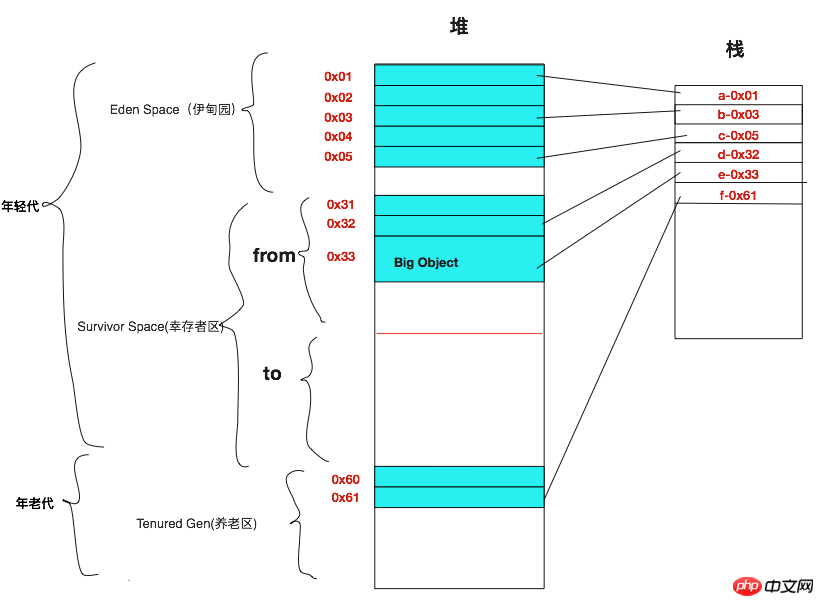
参照カウント (Reference Count) のメモリ リサイクル メカニズムは、現在
Objective-Cおよび Swift 言語で使用されているメモリ リサイクル メカニズムです。参照カウントのメモリのリサイクルについては、ブログで詳しく説明しました。参照がある限り、参照カウントは 1 ずつ増加します。参照カウントが 0 に達すると、メモリのブロックがリサイクルされます。もちろん、このメモリクリーニング方法は、「参照サイクル」を簡単に形成することができます。 Objective-Cの参照カウントにおける循環参照によって引き起こされる
メモリリークの問題では、変数は弱い型または強い型として宣言できます。つまり、参照を「強い参照」または「弱い参照」として定義できます。 「強参照サイクル」が発生した場合、参照の 1 つを 弱い型 に設定すると、この強参照サイクルが壊れ、「メモリ リーク」問題は発生しなくなります。 「参照カウント付きメモリのリサイクル」の詳細については、OC コンテンツに関する以前に公開された関連ブログを参照してください。 参照カウントがどのように機能するかをより明確に理解するために、以下の図を単純に描きました。左側のスタック内の 3 つの参照 a、b、c は、ヒープ内の異なる領域ブロックを指します。ヒープ内のメモリ領域ブロックにおいて、この領域への強参照がある場合、そのretainCountが1増加します。 弱参照がある場合、retainCount は 1 増加しません。 まず、a によって参照される最初のメモリ領域を見てみましょう。このメモリ ブロックは a によってのみ強く参照されるため、a がこのメモリ領域を参照しなくなると、retainCount=0 になり、メモリは次のようになります。のリサイクル。この場合、メモリ リークは発生しません。 b が指すメモリ領域 2 を見てみましょう。 b とメモリ ブロック 3 は両方ともメモリ ブロック 2 への強い参照を持っているため、2 の retainCount=2 になります。メモリ ブロック 2 もメモリ ブロック 3 への強い参照を持っているため、3 の restartCount=1 になります。したがって、b が指すメモリ領域には「強参照サイクル」が存在します。これは、b がこのメモリ領域を指さなくなると、rc=2 が rc=1 になるためです。 restartCountが0ではないので、この2つのメモリ領域は解放されず、2つは解放されないので、当然3つのメモリ領域は解放されませんが、このメモリ領域は再度使用されないため、「」が発生します。 メモリリーク」の状況。これら 2 つのメモリ領域が特に大きい場合、重大な結果が生じることが想像できます。 C 参照と同様に、参照チェーンの 1 つが弱い参照であるため、「強参照サイクル」は発生しません。 c がメモリの 4 番目のブロックを参照しなくなると、rc は 1 から 0 に変化し、ブロック領域は直ちに解放されます。メモリ ブロック 4 が解放された後、メモリ ブロック 5 の rc が 1 から 0 に変化し、メモリ ブロック 5 も解放されます。この場合、メモリ リークは発生しません。 Objective-Cでは、このメソッドはメモリを再利用するために使用されます。もちろん、OCでは、「強参照」と「弱参照」に加えて、自動解放プールもあります。つまり、Autorealease タイプの参照は、retainCount = 0 の場合にはすぐには解放されませんが、自動解放プールから出たときに解放されます。ここでは詳細は説明しません。 2. コピーメモリのリサイクル 」によって引き起こされるメモリリークを解決するために、参照カウントが「循環参照」問題を引き起こしやすいことが分かりました。循環参照」の質問ですが、OCでは「強参照」と「弱参照」という概念が導入されました。次に、コピー メモリのリサイクル メカニズムについて説明します。このメカニズムでは、「循環参照」の問題を心配する必要はありません。コピー系リサイクルの核心は簡単に言えば「コピーすること」ですが、前提となるのは条件付きコピーです。ガベージ コレクション中に、「ライブ オブジェクト」は別の空のヒープ領域にコピーされ、以前の領域は一緒にクリアされます。 「ライブ オブジェクト」とは、オブジェクトの参照チェーンに沿って「スタック」上で到達できるオブジェクトを指します。もちろん、ライブ オブジェクトを新しい「ヒープ領域」にコピーした後、スタック領域への参照も変更する必要があります。 非ヒープ領域からの参照ではありません。つまり、2と3の参照は両方ともヒープ領域からの参照であるため、再利用の対象となります。 この例から、大量のメモリ ガベージがある場合でも、コピーされるオブジェクトが比較的少なく、古いヒープ スペースを直接クリーンアップできるため、「コピー」ガベージ コレクションの効率は比較的高いことがわかります。クリアリング。ただし、ガベージが比較的少ない場合、この方法では多数の生きているオブジェクトがコピーされるため、効率は依然として比較的低いです。この方法では、ヒープ ストレージ領域も半分に分割されます。つまり、半分は常に空き状態となり、ヒープ領域の使用率は高くありません。 3. マーク圧縮回復アルゴリズム 上記の「コピー」ガベージコレクションプロセスから、ガベージが大量にある場合、その効率が高くなることがわかります。ゴミが少なく、その作業方法は効率が比較的低いです。そこで、次に、別のマーク圧縮回復アルゴリズムを紹介します。このアルゴリズムは、ゴミが少ない場合には効率よく動作しますが、ゴミが多い場合には作業効率が高くありません。これは、「コピー型」と同じです。 」「補足です。以下では、マーク圧縮リサイクル アルゴリズムを紹介します。 マーキング - 圧縮の最初のステップはマーキングです。これには、ヒープ領域内の「ライブオブジェクト」をマークする必要があります。 「生き物」とは何かについては、上記のコンテンツですでに説明したので、ここでは詳しく説明しません。 「ライブ オブジェクト」の特性から、以下のライブ オブジェクトがメモリ領域 1 と 3 であることがわかるので、それらをマークします。 マーキングが完了したら、圧縮を開始し、ライブオブジェクトを「ヒープ領域」のセクションに圧縮し、残りの部分をクリアします。以下は 2 つの生物オブジェクト 1 と 3 の圧縮です。圧縮後、下のスペースを掃除します。つまり、Clean 部分では、新しいオブジェクトを割り当てることができます。 以下のスクリーンショットは、マーク圧縮とクリーニング後の状態です。マーク付き圧縮ガベージ コレクションは、ガベージが比較的少ない場合にはヒープ領域のスペースを最大限に活用できますが、ガベージが多すぎて断片化が深刻な場合には、より多くの「ライブ オブジェクト」が移動されます。効率は比較的低いです。このメソッドを「コピー」と組み合わせて使用すると、ヒープ領域の現在のガベージ状態に基づいてリサイクル方法を選択できます。それはまさに「コピー」の利点を補完します。 「コピー」と「マーク圧縮」のリサイクル方法を統合したアルゴリズムが、「世代別」ガベージ コレクション メカニズムです。これについては、以下で詳しく紹介します。 4. 世代別ガベージコレクション 「世代」とは、ガベージが発生しやすい状態やオブジェクトのサイズに応じて、オブジェクトを複数の世代に分けることを指します。 「「若い世代」、「古い世代」、そして「永久世代」。 「永続世代」については山中にはないので、これについては改めて説明しません。世代別ガベージ コレクションの特性に基づいて、次の簡略図が描画されます。 ヒープ内では、エリアは主に「若い世代」と「古い世代」に分かれています。 「若い世代」にあるオブジェクトのメモリは、作成に時間がかからず、比較的早く更新され、「メモリ ガベージ」が発生しやすいため、「若い世代」のガベージ コレクションには「コピー」リサイクル方法が使用されます。もっと効率的。 「若い世代」は 2 つのエリアに分けることができ、1 つはEden Space と Survivor Sprace です。 Eden Space には主に初めて作成されたオブジェクトが保存され、Survivor Sprace には Eden Space から生き残った「生きているオブジェクト」が保存されます。 Survivor Sprace (生存者領域) は、form と to の 2 つのブロックに分割されており、ガベージ クリーニングのためにオブジェクトを相互にコピーするために使用されます。 「古い世代」には、Survivor Sprace から生き残ったいくつかの「大きなオブジェクト」と「オブジェクト」が保存されます。この場合、「古い世代」のオブジェクトはより安定しており、生成されるゴミも少なくなります。 、「マーク圧縮」リサイクル方法を使用する方が効率的です。 「世代別ガベージ コレクション」は主に分割と征服を行い、さまざまなオブジェクトをその特性に従って分類し、分類の特性に基づいて適切なガベージ コレクション ソリューションを選択します。 3. 世代別ガベージコレクションの具体的な動作原理 もちろん、JVM特有のガベージコレクションでは、スレッドに応じて、単一のスレッドを使用してリサイクルする「シリアルガベージコレクション」と、複数のスレッドを使用してリサイクルする「パラレルガベージコレクション」に分けることができます。プログラムの停止状況に応じて、「専用リサイクル」と「同時リサイクル」に分けられます。もちろん、これまで何度も話してきましたが、「並列」と「同時実行」は決して同じ概念ではなく、混同してはいけません。このブログでは上記の方法については詳しく説明しませんので、興味のある方はググってみてください。 「世代別ガベージ コレクション」の実行方法を直感的に感じるために、「世代別ガベージ コレクション」の具体的な動作原理の完全な手順を見てみましょう。 1. ガベージ コレクションの前 下の図は、「世代のガベージ コレクション」を待機している様子を簡略化した図です。割り当てられたオブジェクト メモリの一部が、ヒープ。スタック上では参照されません。これらはリサイクルされるオブジェクトです。以下のヒープは全体として「若い世代」と「古い世代」に分かれており、若い世代はEden Space、From、Toの3つの領域に細分化できることがわかります。各エリアの役割については、上記の「世代別ガベージコレクション」を紹介する際に紹介済みなので、ここでは詳しく紹介しません。 2. 世代別ガベージコレクション 以下の図は、上記のヒープコントロールのガベージコレクションプロセスを示しています。上の図からわかるように、To 領域は空白の領域であり、コピーされたオブジェクトを受け入れることができます。 「若い世代」はメモリゴミが発生しやすいため、「コピー」によるメモリリサイクル方式が採用されています。 2 つのヒープ ブロック Eden Space と From 内の「ライブ オブジェクト」を To 領域にコピーします。コピー中に、コピーされたメモリのスタック参照アドレスも変更する必要があります。 From または Eden 領域の「ラージ オブジェクト」ストレージ スペースは、「古い世代」に直接コピーされます。 From および To 領域にある「大きなオブジェクト」の複数のコピーの効率は比較的低いため、それらを「古い世代」に直接追加して、リサイクル効率を向上させます。 「旧世代」ガベージコレクションには、「マーク圧縮」ガベージコレクションが使用されます。まず、生物に「マーク」を付けます。 3. ガベージコレクション後の結果 以下は、「世代別」ガベージコレクション後の具体的な結果です。以下の図から、Eden Space と From のライブ オブジェクトが To 領域にコピーされ、「旧世代」ヒープ領域の記憶領域も大きく変化していることがわかります。さらに、「旧世代」には、From 領域からコピーされた大きなオブジェクトがさらに存在します。詳細は以下の通りです。 IV. Eclipse GC ログの構成と分析 ここまでで、ガベージ コレクション プロセスを表示し、Eclipse ログ情報でガベージ コレクションを分析する方法を直感的に感じてみましょう。デフォルトでは、ガベージ コレクション プロセスとログの出力は表示されません。ガベージ コレクション ログを出力するには、実行コンフィギュレーションに関連する設定項目を追加する必要があります。このセクションでは、Eclipse のガベージ コレクション ログの設定を確認し、これらのログ レコードを分析します。もちろん、このブログでは Java8 を使用しています。他のバージョンの Java を使用している場合は、出力されるログ情報が若干異なるため、この部分から始めましょう。 1. Eclipseの実行設定を構成します Eclipseの実行設定に対応する設定項目を追加すると、ガベージコレクション時に対応するログ情報が出力されます。プロジェクトを選択し、Run Configurations… オプションを見つけてランタイム構成を実行します。 以下は、上記のオプションによって開かれたダイアログ ボックスです。次に、(x)=Arguments タブ バーを見つけて、対応する仮想マシン パラメーターを VM 引数 に追加します。これらのパラメーターは、実行時にプロジェクトのパラメーターとして使用されます。 。以下に、-XX:+PrintGCTimeStamps と -XX:+PrintGCDetails の 2 つのパラメーターを追加しました。これら 2 つのパラメータ名から、対応するパラメータに対応する関数を確認するのは難しくありません。1 つはガベージ コレクションのタイムスタンプを出力するもので、もう 1 つはガベージ コレクションの詳細を出力するものです。もちろん、「ガベージ コレクション」を選択する場合の特定のアルゴリズムのパラメータ、「シリアル」または「パラレル」のどちらを選択するかのパラメータ、「排他」または「同時」ガベージの選択など、他にも多くのパラメータがあります。リサイクルされたパラメータ。ここではあまり詳しく説明しませんので、ご自身でググってみてください。 2.リサイクルログの印刷と分析 System.gc()を使用して強制ガベージコレクションを実行すると、対応するパラメータが出力されます。情報。まず、テスト用のコードを作成する必要があります。以下は、作成したテスト クラスです。もちろん、テスト クラスのコードは比較的単純です。主なことは、文字列を新しいものにし、参照を null に設定し、最後に System.gc() を呼び出してリサイクルすることです。具体的なコードは以下のとおりです。 [PSYoungGen: 1997K->416K(38400K)] 1997K->424K(125952K)、0.0010277秒] [ParOldGen: 8K->328K(87552K)] [メタスペース: 2669K->2669K(1056768K)] 











package com.zeluli.gclog;public class GCLogTest {public static void main(String[] args) {
String s = new String("Value");
s = null;
System.gc();
}
}

以上がJVMのメモリ領域分割とガベージコレクションの仕組みを詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1655
1655
 14
1413
52
1306
25
1252
29
1226
24
14
1413
52
1306
25
1252
29
1226
24

 プリンターのメモリが不足しているため、ページを印刷できません Excel または PowerPoint エラー
Feb 19, 2024 pm 05:45 PM
プリンターのメモリが不足しているため、ページを印刷できません Excel または PowerPoint エラー
Feb 19, 2024 pm 05:45 PM
Excel ワークシートまたは PowerPoint プレゼンテーションを印刷するときにプリンターのメモリ不足の問題が発生した場合は、この記事が役立つ可能性があります。プリンタにページを印刷するのに十分なメモリがないことを示す同様のエラー メッセージが表示される場合があります。ただし、この問題を解決するために従うことができるいくつかの提案があります。印刷時にプリンターのメモリが使用できないのはなぜですか?プリンターのメモリが不十分であると、「メモリが使用できません」エラーが発生する場合があります。プリンタードライバーの設定が低すぎることが原因である場合もありますが、他の理由である可能性もあります。ファイル サイズが大きい プリンタ ドライバが古いか壊れている インストールされているアドインによる中断 プリンタ設定の誤り この問題は、Microsoft Windows プリンタ ドライバのメモリ設定が低いために発生することもあります。修復印刷
 大規模なメモリの最適化。コンピュータが 16g/32g のメモリ速度にアップグレードしても変化がない場合はどうすればよいですか?
Jun 18, 2024 pm 06:51 PM
大規模なメモリの最適化。コンピュータが 16g/32g のメモリ速度にアップグレードしても変化がない場合はどうすればよいですか?
Jun 18, 2024 pm 06:51 PM
機械式ハード ドライブまたは SATA ソリッド ステート ドライブの場合、NVME ハード ドライブの場合は、ソフトウェアの実行速度の向上を感じられない場合があります。 1. レジストリをデスクトップにインポートし、新しいテキスト ドキュメントを作成し、次の内容をコピーして貼り付け、1.reg として保存し、右クリックしてマージしてコンピュータを再起動します。 WindowsRegistryEditorVersion5.00[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SessionManager\MemoryManagement]"DisablePagingExecutive"=d
![Windows 入力でハングまたはメモリ使用量の増加が発生する [修正]](https://img.php.cn/upload/article/000/887/227/170835409686241.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) Windows 入力でハングまたはメモリ使用量の増加が発生する [修正]
Feb 19, 2024 pm 10:48 PM
Windows 入力でハングまたはメモリ使用量の増加が発生する [修正]
Feb 19, 2024 pm 10:48 PM
Windows 入力エクスペリエンスは、さまざまなヒューマン インターフェイス デバイスからのユーザー入力を処理する重要なシステム サービスです。システム起動時に自動的に起動し、バックグラウンドで実行されます。ただし、場合によっては、このサービスが自動的にハングしたり、メモリを過剰に占有したりして、システムのパフォーマンスが低下することがあります。したがって、システムの効率と安定性を確保するには、このプロセスをタイムリーに監視および管理することが重要です。この記事では、Windows の入力エクスペリエンスがハングしたり、メモリ使用量が高くなる問題を修正する方法を紹介します。 Windows 入力エクスペリエンス サービスにはユーザー インターフェイスがありませんが、基本的なシステム タスクと入力デバイスに関連する機能の処理に密接に関連しています。その役割は、Windows システムがユーザーによって入力されたすべての入力を理解できるようにすることです。
 Xiaomi Mi 14Proのメモリ使用量を確認するにはどうすればよいですか?
Mar 18, 2024 pm 02:19 PM
Xiaomi Mi 14Proのメモリ使用量を確認するにはどうすればよいですか?
Mar 18, 2024 pm 02:19 PM
最近、Xiaomiはスタイリッシュなデザインだけでなく、内部および外部にブラックテクノロジーを備えた強力なハイエンドスマートフォンXiaomi 14Proをリリースしました。この電話機は最高のパフォーマンスと優れたマルチタスク機能を備えており、ユーザーは高速でスムーズな携帯電話体験を楽しむことができます。ただし、パフォーマンスはメモリにも影響されますので、多くのユーザーがXiaomi 14Proのメモリ使用量を確認する方法を知りたいので、見てみましょう。 Xiaomi Mi 14Proのメモリ使用量を確認するにはどうすればよいですか? Xiaomi 14Proのメモリ使用量を確認する方法を紹介. Xiaomi 14Proスマホの[設定]にある[アプリケーション管理]ボタンを開きます。インストールされているすべてのアプリのリストを表示するには、リストを参照して表示するアプリを見つけ、それをクリックしてアプリの詳細ページに入ります。アプリケーションの詳細ページで
 コンピューターのメモリ 8g と 16g には大きな違いがありますか? (8g または 16g のコンピューターメモリを選択してください)
Mar 13, 2024 pm 06:10 PM
コンピューターのメモリ 8g と 16g には大きな違いがありますか? (8g または 16g のコンピューターメモリを選択してください)
Mar 13, 2024 pm 06:10 PM
初心者ユーザーがコンピュータを購入するとき、8g と 16g のコンピュータメモリの違いに興味を持つでしょう。 8gと16gどちらを選べばいいでしょうか?そんなお悩みに対し、今日は編集者が詳しく解説します。コンピューターのメモリの 8g と 16g の間に大きな違いはありますか? 1. 一般的な家庭や通常の仕事の場合、8G の実行メモリで要件を満たすことができるため、使用中に 8g と 16g の間に大きな違いはありません。 2. ゲーム愛好家が使用する場合、現在大規模なゲームは基本的に 6g からであり、8g が最低基準です。現状では画面が2kの場合、解像度が高くてもフレームレート性能は上がらないため、8gでも16gでも大きな差はありません。 3. オーディオおよびビデオ編集ユーザーにとって、8g と 16g の間には明らかな違いがあります。
 関係者によると、サムスン電子とSKハイニックスは2026年以降に積層型モバイルメモリを商品化する予定
Sep 03, 2024 pm 02:15 PM
関係者によると、サムスン電子とSKハイニックスは2026年以降に積層型モバイルメモリを商品化する予定
Sep 03, 2024 pm 02:15 PM
9月3日の当ウェブサイトのニュースによると、韓国メディアetnewsは昨日(現地時間)、サムスン電子とSKハイニックスの「HBM類似」積層構造モバイルメモリ製品が2026年以降に商品化されると報じた。関係者によると、韓国のメモリ大手2社はスタック型モバイルメモリを将来の重要な収益源と考えており、エンドサイドAIに電力を供給するために「HBMのようなメモリ」をスマートフォン、タブレット、ラップトップに拡張する計画だという。このサイトの以前のレポートによると、Samsung Electronics の製品は LPwide I/O メモリと呼ばれ、SK Hynix はこのテクノロジーを VFO と呼んでいます。両社はほぼ同じ技術的ルート、つまりファンアウト パッケージングと垂直チャネルを組み合わせたものを使用しました。 Samsung Electronics の LPwide I/O メモリのビット幅は 512
 サムスン、HBM4メモリでの普及が期待される16層ハイブリッドボンディング積層プロセス技術検証完了を発表
Apr 07, 2024 pm 09:19 PM
サムスン、HBM4メモリでの普及が期待される16層ハイブリッドボンディング積層プロセス技術検証完了を発表
Apr 07, 2024 pm 09:19 PM
報告書によると、サムスン電子幹部のキム大宇氏は、2024年の韓国マイクロエレクトロニクス・パッケージング協会年次総会で、サムスン電子は16層ハイブリッドボンディングHBMメモリ技術の検証を完了すると述べた。この技術は技術検証を通過したと報告されています。同報告書では、今回の技術検証が今後数年間のメモリ市場発展の基礎を築くとも述べている。 DaeWooKim氏は、「サムスン電子がハイブリッドボンディング技術に基づいて16層積層HBM3メモリの製造に成功した。メモリサンプルは正常に動作する。将来的には、16層積層ハイブリッドボンディング技術がHBM4メモリの量産に使用されるだろう」と述べた。 ▲画像出典 TheElec、以下同 ハイブリッドボンディングは、既存のボンディングプロセスと比較して、DRAMメモリ層間にバンプを追加する必要がなく、上下層の銅と銅を直接接続する。
 マイクロン:HBMメモリはウェーハ量の3倍を消費し、生産能力は基本的に来年に予約される
Mar 22, 2024 pm 08:16 PM
マイクロン:HBMメモリはウェーハ量の3倍を消費し、生産能力は基本的に来年に予約される
Mar 22, 2024 pm 08:16 PM
当サイトは3月21日、マイクロンが四半期財務報告書の発表後に電話会議を開催したと報じた。 Micron CEOのSanjay Mehrotra氏はカンファレンスで、従来のメモリと比較してHBMは大幅に多くのウエハを消費すると述べた。マイクロンは、同じノードで同じ容量を生産する場合、現在最も先進的なHBM3Eメモリは標準的なDDR5の3倍のウエハを消費し、性能の向上とパッケージングの複雑さの増大により、将来的にはHBM4のこの比率がさらに増加すると予想されていると述べました。 。このサイトの以前のレポートを参照すると、この高い比率は HBM の歩留まりの低さによる部分もあります。 HBM メモリは、多層の DRAM メモリ TSV 接続でスタックされており、1 つの層に問題があると、全体の層に問題が発生することを意味します。
