

ブログパークニュースのキャプチャを学ぶPython

前言
说到python,对它有点耳闻的人,第一反应可能都是爬虫~
这两天看了点python的皮毛知识,忍不住想写一个简单的爬虫练练手,JUST DO IT
准备工作
要制作数据抓取的爬虫,对请求的源页面结构需要有特定分析,只有分析正确了,才能更好更快的爬到我们想要的内容。
浏览器访问570973/,右键“查看源代码”,初步只想取一些简单的数据(文章标题、作者、发布时间等),在HTML源码中找到相关数据的部分:
1)标题(url):
3) 公開時間: 公開日 2017-06-06 14:53
4) 現在のニュースID: <入力type="hidden" value="570981" id="lbContentID ">
もちろん、手がかりをたどりたい場合、「前の記事」と「次の記事」のリンクの構造は非常に重要ですが、問題は、ページ内の 2 つの タグ、そのリンクとテキスト コンテンツが js を通じてレンダリングされることです。情報(Python は js などを実行します)を探してみてください。ただし、Python 初心者にとっては少し先を行くかもしれないので、別の解決策を見つけるつもりです。
これら 2 つのリンクは js を介してレンダリングされますが、理論的には、js がコンテンツをレンダリングできる理由は、リクエストを開始して応答を取得することによって行われます。それでは、Web ページの読み込みプロセスを監視できるかどうかわかりますか?情報はありますか? chrome/firefox などのブラウザでは、すべてのリソースのリクエストとレスポンスのステータスを明確に確認できます。

彼らのリクエストアドレスは:
1) 前のニュース ID:
2) 次のニュース ID:
応答コンテンツは JSON です
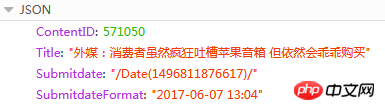
ここで ContentID が必要なものです はい、あなたは知ることができますニュース リリースのページ アドレスは固定形式であるため、この値に基づく現在のニュースの前または次のニュース URL: {{ContentID}}/ (赤色のコンテンツは置換可能な ID )
ツール
1) python 3.6 (同時にpipをインストールし、環境変数を追加します)
2) PyCharm 2017.1.3
3) サードパーティPython ライブラリ (インストール: cmd -> pip インストール名)
a) pyperclip: クリップボードの読み取りと書き込みに使用されます
b) リクエスト: urllib に基づいており、Apache2 ライセンスのオープン ソース プロトコルを使用する HTTP ライブラリ。 urllib よりも便利で、多くの作業を節約できます
c) beautifulsoup4: Beautifulsoup は、ナビゲーション、検索、解析ツリーの変更、その他の機能を処理するための、いくつかのシンプルな Python スタイルの関数を提供します。これは、ドキュメントを解析してキャプチャする必要があるデータをユーザーに提供するツールボックスです
ソースコード
私は個人的に、コードは非常に基本的で理解しやすいと思います(結局のところ、初心者は高度なコードは書きません) )、ご質問やご提案がございましたら、お気軽にお知らせください
#! python3
# coding = utf-8
# get_cnblogs_news.py
# 根据博客园内的任意一篇新闻,获取所有新闻(标题、发布时间、发布人)
#
# 这是标题格式 :<div id="news_title"><a href="//news.cnblogs.com/n/570973/">SpaceX重复使用的“龙”飞船成功与国际空间站对接</a></div>
# 这是发布人格式 :<span class="news_poster">投递人 <a href="//home.cnblogs.com/u/34358/">itwriter</a></span>
# 这是发布时间格式 :<span class="time">发布于 2017-06-06 14:53</span>
# 当前新闻ID :<input type="hidden" value="570981" id="lbContentID">
# html中获取不到上一篇和下一篇的直接链接,因为它是使用ajax请求后期渲染的
# 需要另外请求地址,获取结果,JSON
# 上一篇
# 下一篇
# 响应内容
# ContentID : 570971
# Title : "Mac支持外部GPU VR开发套件售599美元"
# Submitdate : "/Date(1425445514)"
# SubmitdateFormat : "2017-06-06 14:47"
import sys, pyperclip
import requests, bs4
import json
# 解析并打印(标题、作者、发布时间、当前ID)
# soup : 响应的HTML内容经过bs4转化的对象
def get_info(soup):
dict_info = {'curr_id': '', 'author': '', 'time': '', 'title': '', 'url': ''}
titles = soup.select('div#news_title > a')
if len(titles) > 0:
dict_info['title'] = titles[0].getText()
dict_info['url'] = titles[0].get('href')
authors = soup.select('span.news_poster > a')
if len(authors) > 0:
dict_info['author'] = authors[0].getText()
times = soup.select('span.time')
if len(times) > 0:
dict_info['time'] = times[0].getText()
content_ids = soup.select('input#lbContentID')
if len(content_ids) > 0:
dict_info['curr_id'] = content_ids[0].get('value')
# 写文件
with open('D:/cnblognews.csv', 'a') as f:
text = '%s,%s,%s,%s\n' % (dict_info['curr_id'], (dict_info['author'] + dict_info['time']), dict_info['url'], dict_info['title'])
print(text)
f.write(text)
return dict_info['curr_id']
# 获取前一篇文章信息
# curr_id : 新闻ID
# loop_count : 向上多少条,如果为0,则无限向上,直至结束
def get_prev_info(curr_id, loop_count = 0):
private_loop_count = 0
try:
while loop_count == 0 or private_loop_count < loop_count:
res_prev = requests.get('https://news.cnblogs.com/NewsAjax/GetPreNewsById?contentId=' + curr_id)
res_prev.raise_for_status()
res_prev_dict = json.loads(res_prev.text)
prev_id = res_prev_dict['ContentID']
res_prev = requests.get('https://news.cnblogs.com/n/%s/' % prev_id)
res_prev.raise_for_status()
soup_prev = bs4.BeautifulSoup(res_prev.text, 'html.parser')
curr_id = get_info(soup_prev)
private_loop_count += 1
except:
pass
# 获取下一篇文章信息
# curr_id : 新闻ID
# loop_count : 向下多少条,如果为0,则无限向下,直至结束
def get_next_info(curr_id, loop_count = 0):
private_loop_count = 0
try:
while loop_count == 0 or private_loop_count < loop_count:
res_next = requests.get('https://news.cnblogs.com/NewsAjax/GetNextNewsById?contentId=' + curr_id)
res_next.raise_for_status()
res_next_dict = json.loads(res_next.text)
next_id = res_next_dict['ContentID']
res_next = requests.get('https://news.cnblogs.com/n/%s/' % next_id)
res_next.raise_for_status()
soup_next = bs4.BeautifulSoup(res_next.text, 'html.parser')
curr_id = get_info(soup_next)
private_loop_count += 1
except:
pass
# 参数从优先从命令行获取,如果无,则从剪切板获取
# url是博客园新闻版块下,任何一篇新闻
if len(sys.argv) > 1:
url = sys.argv[1]
else:
url = pyperclip.paste()
# 没有获取到有地址,则抛出异常
if not url:
raise ValueError
# 开始从源地址中获取新闻内容
res = requests.get(url)
res.raise_for_status()
if not res.text:
raise ValueError
#解析Html
soup = bs4.BeautifulSoup(res.text, 'html.parser')
curr_id = get_info(soup)
print('backward...')
get_prev_info(curr_id)
print('forward...')
get_next_info(curr_id)
print('done')
実行
上記のソース コードを D:/get_cnblogs_news.py に保存し、Windows プラットフォームでコマンド ライン ツール cmd を開きます: コマンド py.exe D:/get_cnblogs_news を入力します。 py Enter 分析: py.exe について説明する必要はありません。2 番目のパラメータは Python スクリプト ファイルで、3 番目のパラメータはクロールする必要があるソース ページです (コピーする場合、コードには別の考慮事項があります)。この URL をシステムのクリップボードに保存します。 py.exe D:/get_cnblogs_news.py を直接実行できます。 コマンド ライン出力インターフェイス (印刷)

for novices python learning book box または情報:
1) Liao Xuefeng の Python チュートリアル、非常に基本的で理解しやすい:
2) 退屈な作業を自動化するための Python プログラミングですぐに始めましょう.pdf
この記事はあくまで独学でPythonを学ぶための日記です、誤解を招く点があれば批判して修正してください(気に入らない場合は批判しないでください)。
以上がブログパークニュースのキャプチャを学ぶPythonの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7522
7522
 15
1378
52
81
11
21
72
15
1378
52
81
11
21
72

 Python:ゲーム、GUIなど
Apr 13, 2025 am 12:14 AM
Python:ゲーム、GUIなど
Apr 13, 2025 am 12:14 AM
PythonはゲームとGUI開発に優れています。 1)ゲーム開発は、2Dゲームの作成に適した図面、オーディオ、その他の機能を提供し、Pygameを使用します。 2)GUI開発は、TKINTERまたはPYQTを選択できます。 TKINTERはシンプルで使いやすく、PYQTは豊富な機能を備えており、専門能力開発に適しています。
 PHPとPython:2つの一般的なプログラミング言語を比較します
Apr 14, 2025 am 12:13 AM
PHPとPython:2つの一般的なプログラミング言語を比較します
Apr 14, 2025 am 12:13 AM
PHPとPythonにはそれぞれ独自の利点があり、プロジェクトの要件に従って選択します。 1.PHPは、特にWebサイトの迅速な開発とメンテナンスに適しています。 2。Pythonは、データサイエンス、機械学習、人工知能に適しており、簡潔な構文を備えており、初心者に適しています。
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
限られた時間でPythonの学習効率を最大化するには、PythonのDateTime、時間、およびスケジュールモジュールを使用できます。 1. DateTimeモジュールは、学習時間を記録および計画するために使用されます。 2。時間モジュールは、勉強と休息の時間を設定するのに役立ちます。 3.スケジュールモジュールは、毎週の学習タスクを自動的に配置します。
 Nginx SSL証明書更新Debianチュートリアル
Apr 13, 2025 am 07:21 AM
Nginx SSL証明書更新Debianチュートリアル
Apr 13, 2025 am 07:21 AM
この記事では、DebianシステムでNGINXSSL証明書を更新する方法について説明します。ステップ1:最初にCERTBOTをインストールして、システムがCERTBOTおよびPython3-Certbot-Nginxパッケージがインストールされていることを確認してください。インストールされていない場合は、次のコマンドを実行してください。sudoapt-getupdatesudoapt-getinstolcallcertbotthon3-certbot-nginxステップ2:certbotコマンドを取得して構成してlet'sencrypt証明書を取得し、let'sencryptコマンドを取得し、nginx:sudocertbot - nginxを構成します。
 debian opensslでHTTPSサーバーを構成する方法
Apr 13, 2025 am 11:03 AM
debian opensslでHTTPSサーバーを構成する方法
Apr 13, 2025 am 11:03 AM
DebianシステムでHTTPSサーバーの構成には、必要なソフトウェアのインストール、SSL証明書の生成、SSL証明書を使用するWebサーバー(ApacheやNginxなど)の構成など、いくつかのステップが含まれます。 Apachewebサーバーを使用していると仮定して、基本的なガイドです。 1.最初に必要なソフトウェアをインストールし、システムが最新であることを確認し、ApacheとOpenSSL:sudoaptupdatesudoaptupgraysudoaptinstaをインストールしてください
 DebianのGitlabのプラグイン開発ガイド
Apr 13, 2025 am 08:24 AM
DebianのGitlabのプラグイン開発ガイド
Apr 13, 2025 am 08:24 AM
DebianでGitLabプラグインを開発するには、特定の手順と知識が必要です。このプロセスを始めるのに役立つ基本的なガイドを以下に示します。最初にgitlabをインストールすると、debianシステムにgitlabをインストールする必要があります。 GitLabの公式インストールマニュアルを参照できます。 API統合を実行する前に、APIアクセストークンを取得すると、GitLabのAPIアクセストークンを最初に取得する必要があります。 gitlabダッシュボードを開き、ユーザー設定で「アクセストーケン」オプションを見つけ、新しいアクセストークンを生成します。生成されます
 Apacheとは何ですか
Apr 13, 2025 pm 12:06 PM
Apacheとは何ですか
Apr 13, 2025 pm 12:06 PM
アパッチはインターネットの背後にあるヒーローです。それはWebサーバーであるだけでなく、膨大なトラフィックをサポートし、動的なコンテンツを提供する強力なプラットフォームでもあります。モジュラー設計を通じて非常に高い柔軟性を提供し、必要に応じてさまざまな機能を拡張できるようにします。ただし、モジュール性は、慎重な管理を必要とする構成とパフォーマンスの課題も提示します。 Apacheは、高度にカスタマイズ可能で複雑なニーズを満たす必要があるサーバーシナリオに適しています。
