

最近、MySQL のページング最適化のテスト ケースを偶然見ましたが、テスト シナリオをあまり具体的に説明せずに、古典的な解決策が示されていました
現実の多くの状況では、一般的なプラクティスやルールを要約することができませんでした。多くのシナリオを検討する必要があります
同時に、最適化を達成できる方法に直面した場合、同じアプローチでは最適化の効果が得られない理由を調査する必要があります。まだ原因を調査する必要があります。
私は個人的にこのシナリオの使用について疑問を表明し、その後自分でテストして、いくつかの問題を発見し、いくつかの予想されるアイデアも確認しました。
この記事では、最も単純な状況から始めて、MySQL ページングの最適化に関する簡単な分析を行います。
別: この記事のテスト環境は最も低い構成のクラウドサーバーです。比較的にサーバーのハードウェア環境は限られていますが、異なるステートメント (記述方法) は「同等」である必要があります
MySQL の古典的なページングの「最適化」。メソッド
MySQL のページング最適化では、「後方」データがクエリされるほど遅くなります (テーブルのインデックスの種類によっては、同じことが B ツリー構造インデックスにも当てはまります)。 SQL Server)
select * from t order by ID 制限 m,n。
つまり、M が増加するにつれて、同じ量のデータのクエリはますます遅くなります
この問題に直面して、次の記述に似た (またはその変形) 古典的なアプローチが生まれました
まず、ページング範囲内の ID を個別に取得し、それをベース テーブルに関連付け、最後に必要なデータをクエリします
select * from t
inner join (select id from t order by id limit m,n)t1 on t1.id = t.id
このアプローチは常に有効ですか? それとも、どのような状況下で後者が最適化の目的を達成できるのでしょうか?書き換えると効果がなくなったり、遅くなったりすることはありますか?
同時に、ほとんどのクエリにはフィルタリング条件があります
フィルタリング条件がある場合、
sql ステートメントは select * from t where *** order by id limit m, n になります
同じ方法に従う場合。 ,
select * from t
inner join (select id from t where *** order by id limit m,n )t1 on t1.id = t.id
のようなものに書き換えます
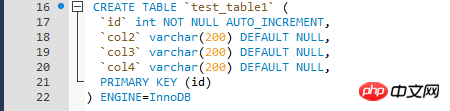
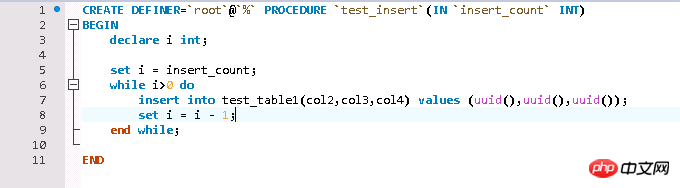
テスト環境の構築
テスト データは、ストアド プロシージャ ループとテスト テーブルの InnoDB エンジン テーブルを通じて書き込まれます。

ページングクエリ最適化の理由
まず、ページング時にクエリがさらに「戻る」というこの古典的な問題を見てみましょう。つまり、応答は遅くなります。 テスト 1: 行 1 ~ 20 のデータをクエリする、0.01 秒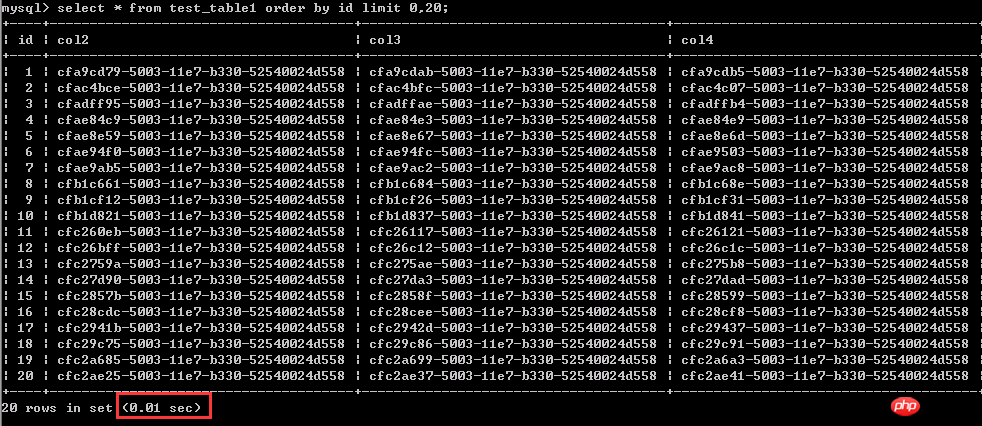

後者の効率が低い理由については、後で分析します。
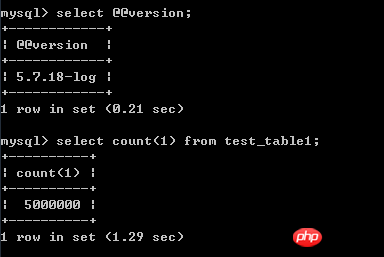
テスト環境はcentos 7、mysql 5.7、テストテーブルのデータは500Wです
古典的なページングの「最適化」を再現し、フィルタ条件がない場合、ソート列がクラスター化インデックス時間である場合、改善はありません
ここでは、クラスター化インデックス列をソート条件として使用した場合の次の 2 つの書き込みメソッドのパフォーマンスを比較しますselect * from t order by id limit m,n。
select * from t
inner join (select id from t order by id limit m,n)t1 on t1.id = t.id
select * from test_table1 order by id asc limit 4900000,20; テスト結果はスクリーンショットに示されています、実行時間は8.31秒です
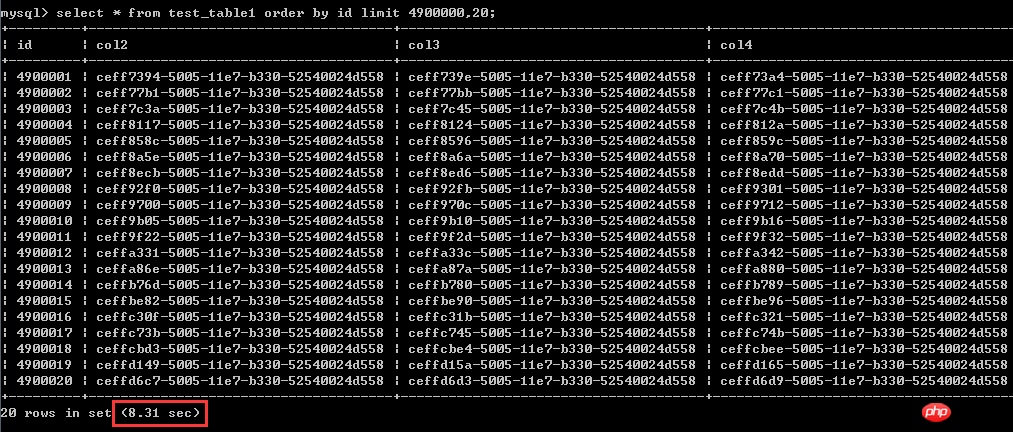
2番目の書き換え方法:
select t1.* from test_table1 t1
inner join (select id from test_table1 order by id limit 4900000,20)t2 on t1.id = t2.id;実行時間は 8.43 秒です
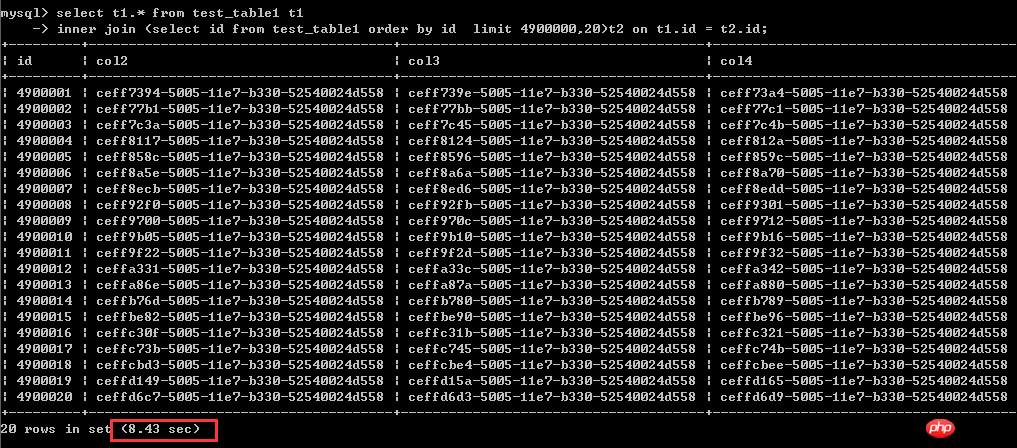
ここで、書き換え後の結果は非常に明確です。古典的な書き換え方法では、パフォーマンスはまったく改善されず、さらに少し遅くなります
実際のテストでは、この 2 つの元の投稿者は複数のテストを実行しましたが、パフォーマンスに明らかな直線的な違いがないことがわかりました。 。
個人的には、同様の結論を見たとき、これは信頼できないのか、なぜ効率が向上するのか、なぜ改善できないのかをテストする必要があります。
それでは、なぜ書き換えられた書き込みメソッドが伝説的なほどパフォーマンスを向上させなかったのでしょうか?
この現在の書き換えがパフォーマンスを向上させるという目的を達成できない原因は何ですか?
後者がパフォーマンスを向上させる原理は何ですか?
まず、テストテーブルのテーブル構造を見てください。ソート列のインデックスが主キーであることは問題ありません。
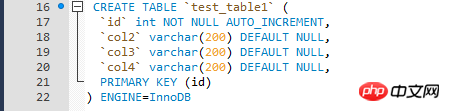
ソート列がクラスター化インデックスの場合、比較的「最適化」された書き換えられたSQLでは「最適化」の目的を達成できないのはなぜですか?
ソート列がクラスター化インデックス列の場合、両方ともシーケンシャルスキャンです修飾されたデータをクエリするためのテーブル
後者は最初にサブクエリを実行し、次にサブクエリの結果を使用してメインテーブルを駆動します
が、サブクエリは「修飾されたデータをクエリするためのテーブルの順次スキャン」を変更しません。のアプローチは、現在の状況では、書き換えられたアプローチさえも不必要に思えます
次の 2 つの実行プラン、最初のスクリーンショットの実行プランの 1 行、および書き換えられた SQL 実行プランの 3 行目 (id = 2行)、基本的には同じです。


フィルター条件がなく、ソートがクラスター化インデックスである場合、いわゆるページングクエリの最適化は単に不必要です
現時点では、上記のデータをクエリするには2つの方法があります非常に遅いです。では、上記のデータをクエリしたい場合はどうすればよいでしょうか。
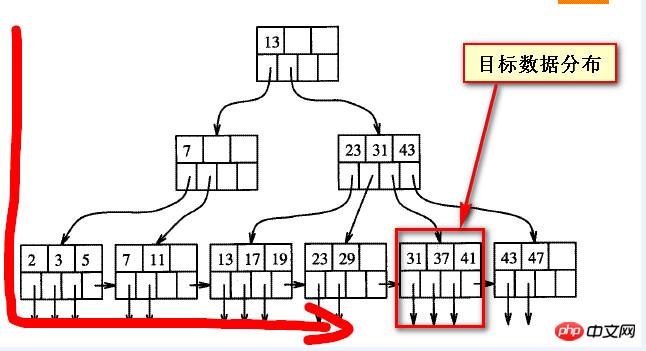
以下の図に示すように、まず B ツリーのバランスの取れた構造を理解する必要があります。
クエリされたデータが「後ろ」にある場合、実際には逸脱します。 B ツリー インデックスからの一方向、以下の 2 つのスクリーンショットに示されているターゲット データ
実際、バランス ツリー上のデータには、いわゆる「前方」と「後方」はありません。 、または走査方向から見ると
一方向から見た場合は「裏」のデータ、一方向から見た場合は「表」のデータであり、表と裏は絶対的なものではありません。
次の 2 つのスクリーンショットは、ターゲット データの位置が固定されている場合、いわゆる「後方」は左から右への相対的なものです。右から左に見てみると、いわゆる後のデータは実際には「前方」です。
データが先頭にある限り、データのこの部分を効率的に見つけることができます。 Mysql にも、sqlserver の転送スキャンと逆スキャンに似たメソッドが必要です。
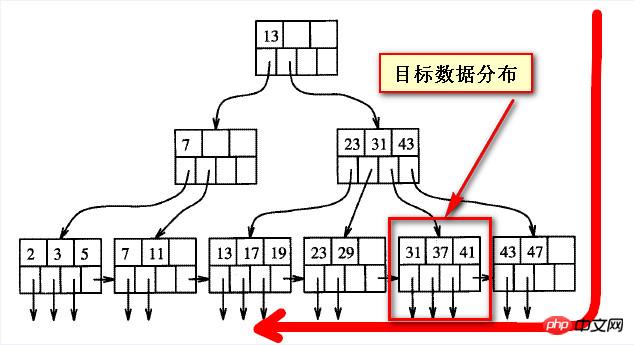 後のデータに対して逆スキャンを使用すると、データのこの部分をすぐに見つけて、見つかったデータを再度並べ替え (昇順) できるはずです。結果は同じになるはずです。
後のデータに対して逆スキャンを使用すると、データのこの部分をすぐに見つけて、見つかったデータを再度並べ替え (昇順) できるはずです。結果は同じになるはずです。
かかる時間はわずか 0.07 秒です
。前の 2 つの書き込み方法ではどちらも 8 秒以上かかり、効率には数百倍の違いがあります。 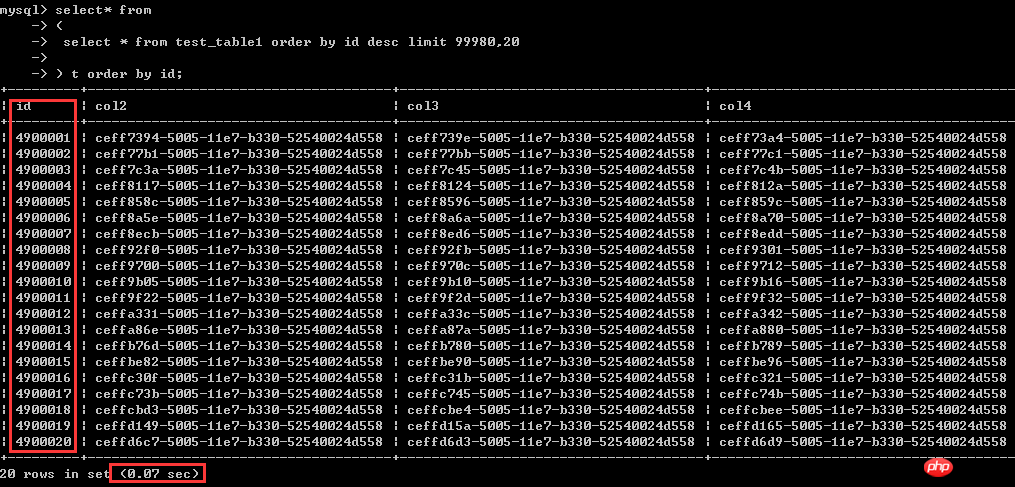
なぜそうなるかについては、上記の説明から理解できると思います。 SQLは次のとおりです。
より大きな ID を持つデータ、または時間ディメンションの新しいデータなど、いわゆる後発データを頻繁にクエリする場合は、逆方向スキャン インデックス手法を使用して効率的なページング クエリを実現できます
(ここでデータを計算してください。どこにあるか、同じデータ、順方向と逆順で開始の「ページ番号」が異なります)
select* from(select * from test_table1 order by id desc limit 99980,20) t order by id;
フィルター条件がなく、ソート列がノンクラスタードインデックスの場合, 改善されます
ここでテストテーブルtest_table1に以下の変更を加えます
1. id_2列を追加します、
2. このフィールドに一意のインデックスを作成します、
3. このフィールドに対応する主キーを入力します。 Id
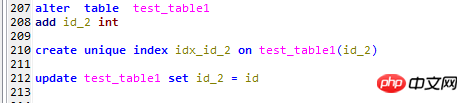
上記のテストは主キーインデックス(クラスター化インデックス)に従ってソートされています。次に、非クラスター化インデックス、つまり新しく追加された列id_2に従ってソートし、2つのページング方法をテストしてみましょう。冒頭で述べた。
まずは一つ目の書き方を見てみましょう
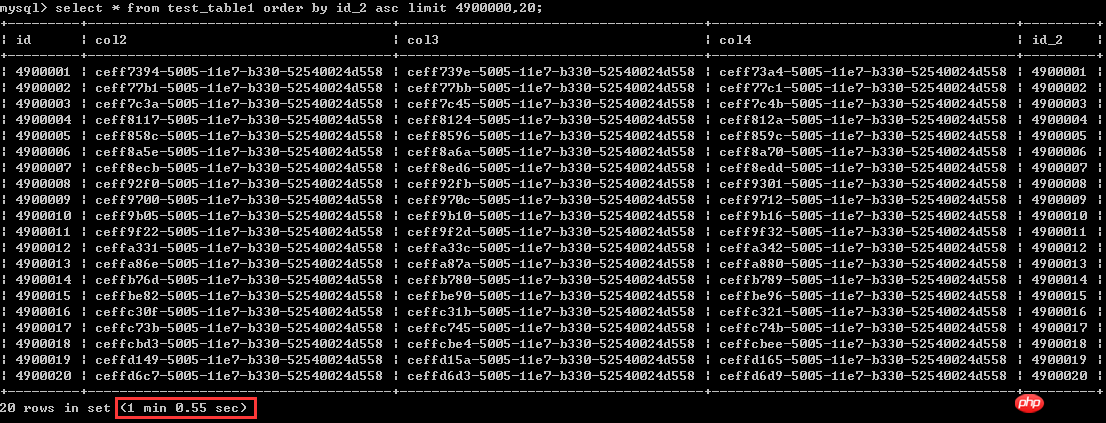
select * from test_table1 order by id_2 asc limit 4900000,20;実行時間は1分強ですが、60秒として考えてみましょう
2つ目の書き方
select t1.* from test_table1 t1
inner join (select id from test_table1 order by id_2 limit 4900000,20)t2 on t1.id = t2.id;実行時間 1.67秒
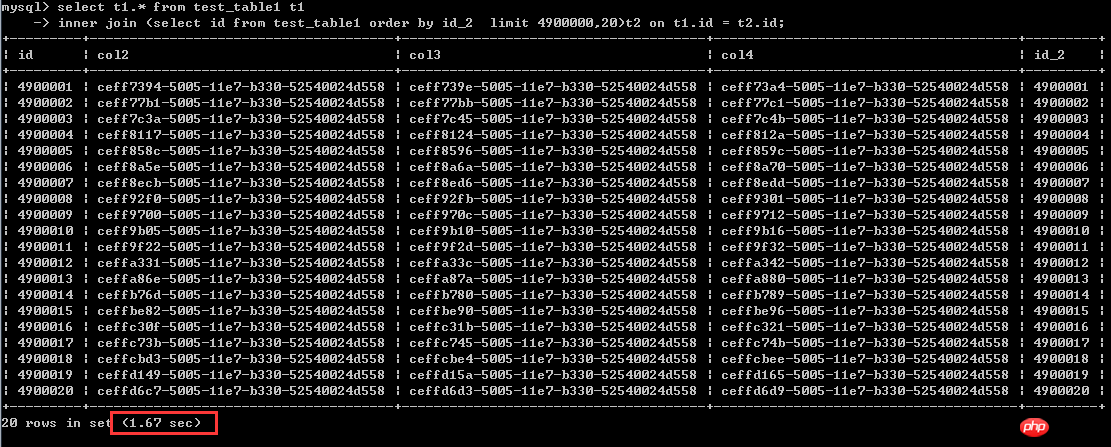
この状況から見て、つまり、ソート列が非クラスター化インデックス列である場合、後者の書き方の方が確かに効率が大幅に向上します。これはほぼ 40 倍の改善です。
それで、その理由は何ですか?
まず、最初の書き込みメソッドの実行計画を見てみましょう。単純に理解すると、この SQL の実行中にテーブル全体がスキャンされ、id_2 に従って再度並べ替えられ、最終的に上位 20 個のデータが表示されます。取られた。
まず、フルテーブルスキャンは非常に時間がかかり、ソートも非常にコストがかかるため、パフォーマンスが非常に低いです。

後者の実行プランを見ると、まず id_2 のインデックス順序に従ってサブクエリをスキャンし、次に修飾された主キー Id を使用してテーブル内のデータをクエリします
このように、大きな多くのクエリが回避され、その後、データが並べ替えられます (filesort を使用)
SQLserver の実行計画を理解していれば、前者と比較して、後者は頻繁なテーブル リターン (SQLserver のキー検索またはブックマーク検索と呼ばれるプロセス
) を回避できるはずです。外部テーブルを駆動して 20 個の修飾されたデータをクエリするサブクエリのプロセスは、実際には、現在の状況、つまりソート列が非クラスター化インデックス列である場合にのみ行われます。書き換えられた SQL はページング クエリの効率を向上させることができます
上でわかるように、同じデータが返されます。次のクエリは 0.07 秒で、ここの 1.67 秒より 2 桁長いです
select* from(select * from test_table1 order by id desc limit 99980,20) t order by id;
もう 1 つ言及したい質問は、ページング クエリが頻繁に特定の順序で実行される場合、この列にクラスター化インデックスを作成してはどうだろうかということです。
例えば、ステートメントが ID を自動的にインクリメントする場合、または時刻 + 他のフィールドが一意性を保証する場合、mysql は主キーにクラスター化インデックスを自動的に作成します。
そして、クラスター化インデックスでは、「前」と「後」は単なる相対的な論理概念であり、ほとんどの場合、「後」以降のデータを取得したい場合は、上記の書き込み方法、
最適化を使用できます。フィルター条件がある場合のページング クエリの実行
この部分についてはしばらく考えました。状況が複雑すぎて、非常に代表的なケースを要約するのは難しいので、あまりテストはしません。
select * from t where *** order by idlimit m,n
1. 例えば、ブラシ選択条件自体は、一度フィルタリングするとごく一部のデータしか残らないので、作りません。フィルタリング条件自体は非常に効率的なフィルタリングを実現できるため、SQL を書き換えるかどうかは非常に意味があります
2. たとえば、ブラシ選択条件自体はほとんど効果がありません (フィルタリング後のデータ量は依然として膨大です)。フィルタリング条件が存在しない状況で、ソート方法、順方向または逆順などによって異なります。
3. 例えば、フィルタリング条件自体はほとんど効果がありません(フィルタリング後のデータ量は依然として膨大です)。考慮すべき問題はデータの分散です
データの分散は SQL の実行効率にも影響します (sqlserver、mysql での経験はそれほど変わらないはずです)
4. クエリ自体が比較的複雑な場合、特定の方法は効率的な目的を達成できます
状況が複雑であればあるほど、一般的なことを要約するのは困難です セックスの法則や方法に関しては、すべてを特定の状況に基づいて見なければならず、最終的な結論を引き出すことは困難です。
ここでは、クエリにフィルタリング条件を 1 つずつ追加する状況を分析しませんが、確かなことは、実際のシナリオがなければ確実な解決策は絶対に存在しないということです。
また、現在のページのデータをクエリする場合、前のページのクエリの最大値をフィルター条件として使用でき、現在のページのデータをすぐに見つけることができます。問題ありませんが、これは別のアプローチであるため、この記事の説明には含まれていません。
概要
ページング クエリは後ろに行くほど遅くなります。実際、B ツリー インデックスの場合、前と後ろは論理的に相対的な概念であり、パフォーマンスの違いは B ツリーに基づいています。
フィルター条件を追加すると、この問題の原理はSQL Serverでも同じであるため、繰り返しません。それはここです。
現状では、ソートカラムやクエリ条件、データの分散が必ずしも確実ではないため、特定の方法で「最適化」を実現することが難しく、そうでないと余計な副作用が生じてしまいます。
したがって、ページングの最適化を行う場合は、特定のシナリオに基づいて分析を行う必要があります。実際のシナリオから乖離した結論は、必ずしも 1 つだけであるとは限りません。
この問題の詳細を理解することによってのみ、私たちはこの問題に簡単に対処できるようになります。
したがって、データの「最適化」に関する私の個人的な結論は、特定の問題の具体的な分析に基づいている必要があり、他の人が「適用」できるように一連のルール (ルール 1、2、3、4、5) を要約することは非常にタブーです。私も非常に優れているので、あえていくつかの独断を要約することはできません。
以上がMySQL ページング最適化テスト ケースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



