

クローラーの問題解決に関連する問題
继续上一篇文章的内容,上一篇文章中已经将url管理器和下载器写好了。接下来就是url解析器,总的来说这个模块是几个模块中比较难的。因为通过下载器下载完页面之后,我们虽然得到了页面,但是这并不是我们想要的结果。而且由于页面的代码很多,我们很难去里面找到自己想要的数据。所幸,我们下载的是html页面,它是一种由多个多层次的节点组成的树型结构的文本文件。所以,相较于txt文件,我们更加容易定位到我们要找的数据块。现在我们要做的就是去原页面去分析一下,我们想要的数据到底在哪。
打开百度百科pyton词条的页面,然后按F12调出开发者工具。通过使用工具,我们就能定位到页面的内容:
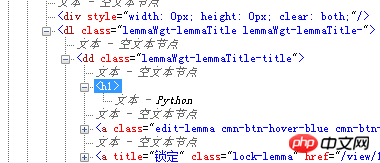

这样我们就找到了我们想要的信息处在哪个标签里了。
1 import bs4 2 import re 3 from urllib.parse import urljoin 4 class HtmlParser(object): 5 """docstring for HtmlParser""" 6 def _get_new_urls(self, url, soup): 7 new_urls = set() 8 links = soup.find_all('a', href = re.compile(r'/item/.')) 9 for link in links:10 new_url = re.sub(r'(/item/)(.*)', r'\1%s' % link.getText(), link['href'])11 new_full_url = urljoin(url, new_url)12 new_urls.add(new_full_url)13 return new_urls14 15 def _get_new_data(self, url, soup):16 res_data = {}17 #url18 res_data['url'] = url19 #<dd class="lemmaWgt-lemmaTitle-title">20 title_node = soup.find('dd', class_ = "lemmaWgt-lemmaTitle-title").find('h1')21 res_data['title'] = title_node.getText()22 #<div class="lemma-summary" label-module="lemmaSummary">23 summary_node = soup.find('div', class_ = "lemma-summary")24 res_data['summary'] = summary_node.getText()25 return res_data26 27 def parse(self, url, html_cont):28 if url is None or html_cont is None:29 return 30 soup = bs4.BeautifulSoup(html_cont, 'lxml')31 new_urls = self._get_new_urls(url, soup)32 new_data = self._get_new_data(url, soup)33 return new_urls, new_data解析器只有一个外部方法就是parse方法,
a.首先它会接受url, html_cont两个参数,然后进行判断页面内容是否为空
b.调用bs4模块的方法来解析网页内容,'lxml'为文档解析器,默认的为html.parser,bs官方推荐我们用lxml,那就听它的吧,谁让人家是官方呢。
c.接下来就是调用两个内部函数来获取新的url列表和数据
d.最后将url列表和数据返回
这里有一些注意点
1.bs的方法调用还有一个参数,from_encoding 这个和我在下载器那里的重复了,所以我就取消了,两个的功能是一样的。
2.获取url列表的内部方法,需要用到正则表达式,这里我也是摸着石头过河,不是很会,中间也调试过许多次。
3.数据是放在字典中的,这样可以通过key来增改删除数据。
最好,就直接数据输出了,这个比较简单,直接上代码。
1 class HtmlOutputer(object): 2 """docstring for HtmlOutputer""" 3 def __init__(self): 4 self.datas = [] 5 def collect_data(self, new_data): 6 if new_data is None: 7 return 8 self.datas.append(new_data) 9 def output_html(self):10 fout = open('output1.html', 'w', encoding = 'utf-8')11 fout.write('<html>')12 fout.write('<head><meta charset="utf-8"></head>')13 fout.write('<body>')14 fout.write('<table>')15 for data in self.datas:16 fout.write('<tr>')17 fout.write('<td>%s</td>' % data['url'])18 fout.write('<td>%s</td>' % data['title'])19 fout.write('<td>%s</td>' % data['summary'])20 fout.write('</tr>')21 fout.write('</table>')22 fout.write('</body>')23 fout.write('</html>')24 fout.close()这里也有两个注意点
1.fout = open('output1.html', 'w', encoding = 'utf-8'),这里的encoding参数一定要加,不然会报错,在windows平台,它默认是使用gbk编码来写文件的。
2.fout.write('
'),这里的meta标签也要加上,因为要告诉浏览器使用什么编码来渲染页面,这里我一开始没加弄了很久,我打开页面的内容,发现里面是中文的,结果浏览器展示的就是乱码。总的来说,因为整个页面采集过程结果好几个模块,所以编码问题要非常小心,不然少不留神就会出错。
最后总结,这段程序还有许多方面可以深入探讨:
1.页面的数据量过小,我尝试了10000个页面的爬取。一旦数据量剧增之后,就会带来一下问题,第一是待爬取url和已爬取url就不能放在set集合中了,要么放到radi缓存服务器里,要么放到mysql数据库中
2.第二,数据也是同样的,字典也满足不了了,需要专门的数据库来存放
3.第三量上去之后,对爬取效率就有要求了,那么多线程就要加进来
4.第四,一旦布置好任务,单台服务器的压力会过大,而且一旦宕机,风险很大,所以分布式的高可用架构也要跟上来
5.一方面是页面的内容过于简单,都是静态页面,不涉及登录,也不涉及ajax动态获取
6.这只是数据采集,后续还有建模,分析…………
综上所述,路还远的很呢,加油!
以上がクローラーの問題解決に関連する問題の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7449
7449
 15
1374
52
77
11
14
6
15
1374
52
77
11
14
6

 PSが荷重を見せ続ける理由は何ですか?
Apr 06, 2025 pm 06:39 PM
PSが荷重を見せ続ける理由は何ですか?
Apr 06, 2025 pm 06:39 PM
PSの「読み込み」の問題は、リソースアクセスまたは処理の問題によって引き起こされます。ハードディスクの読み取り速度は遅いか悪いです。CrystaldiskInfoを使用して、ハードディスクの健康を確認し、問題のあるハードディスクを置き換えます。不十分なメモリ:高解像度の画像と複雑な層処理に対するPSのニーズを満たすためのメモリをアップグレードします。グラフィックカードドライバーは時代遅れまたは破損しています:ドライバーを更新して、PSとグラフィックスカードの間の通信を最適化します。ファイルパスが長すぎるか、ファイル名に特殊文字があります。短いパスを使用して特殊文字を避けます。 PS独自の問題:PSインストーラーを再インストールまたは修理します。
 PSの負荷速度をスピードアップする方法は?
Apr 06, 2025 pm 06:27 PM
PSの負荷速度をスピードアップする方法は?
Apr 06, 2025 pm 06:27 PM
Slow Photoshopの起動の問題を解決するには、次のような多面的なアプローチが必要です。ハードウェアのアップグレード(メモリ、ソリッドステートドライブ、CPU)。時代遅れまたは互換性のないプラグインのアンインストール。システムのゴミと過剰な背景プログラムを定期的にクリーンアップします。無関係なプログラムを慎重に閉鎖する。起動中に多数のファイルを開くことを避けます。
 PSが開始されたときにロードの問題を解決する方法は?
Apr 06, 2025 pm 06:36 PM
PSが開始されたときにロードの問題を解決する方法は?
Apr 06, 2025 pm 06:36 PM
ブートがさまざまな理由によって引き起こされる可能性がある場合、「読み込み」に巻き込まれたPS:腐敗したプラグインまたは競合するプラグインを無効にします。破損した構成ファイルの削除または名前変更。不十分なプログラムを閉じたり、メモリをアップグレードしたりして、メモリが不十分であることを避けます。ソリッドステートドライブにアップグレードして、ハードドライブの読み取りをスピードアップします。 PSを再インストールして、破損したシステムファイルまたはインストールパッケージの問題を修復します。エラーログ分析の起動プロセス中にエラー情報を表示します。
 HTML次ページ関数
Apr 06, 2025 am 11:45 AM
HTML次ページ関数
Apr 06, 2025 am 11:45 AM
<p>次のページ関数は、HTMLを介して作成できます。手順には、コンテナ要素の作成、コンテンツの分割、ナビゲーションリンクの追加、他のページの隠し、スクリプトの追加が含まれます。この機能により、ユーザーはセグメント化されたコンテンツを閲覧でき、一度に1つのページのみを表示し、大量のデータやコンテンツを表示するのに適しています。 </p>
 遅いPSの読み込みはコンピューター構成に関連していますか?
Apr 06, 2025 pm 06:24 PM
遅いPSの読み込みはコンピューター構成に関連していますか?
Apr 06, 2025 pm 06:24 PM
PSの負荷が遅い理由は、ハードウェア(CPU、メモリ、ハードディスク、グラフィックスカード)とソフトウェア(システム、バックグラウンドプログラム)の影響を組み合わせたものです。ソリューションには、ハードウェアのアップグレード(特にソリッドステートドライブの交換)、ソフトウェアの最適化(システムガベージのクリーンアップ、ドライバーの更新、PS設定のチェック)、およびPSファイルの処理が含まれます。定期的なコンピューターのメンテナンスは、PSのランニング速度を改善するのにも役立ちます。
 PSがファイルを開いたときにロードの問題を解決する方法は?
Apr 06, 2025 pm 06:33 PM
PSがファイルを開いたときにロードの問題を解決する方法は?
Apr 06, 2025 pm 06:33 PM
「ロード」は、PSでファイルを開くときに発生します。理由には、ファイルが大きすぎるか破損しているか、メモリが不十分で、ハードディスクの速度が遅い、グラフィックカードドライバーの問題、PSバージョンまたはプラグインの競合が含まれます。ソリューションは、ファイルのサイズと整合性を確認し、メモリの増加、ハードディスクのアップグレード、グラフィックカードドライバーの更新、不審なプラグインをアンインストールまたは無効にし、PSを再インストールします。この問題は、PSパフォーマンス設定を徐々にチェックして使用し、優れたファイル管理習慣を開発することにより、効果的に解決できます。
 PSが常にロードされていることを常に示しているときに、ロードの問題を解決する方法は?
Apr 06, 2025 pm 06:30 PM
PSが常にロードされていることを常に示しているときに、ロードの問題を解決する方法は?
Apr 06, 2025 pm 06:30 PM
PSカードは「ロード」ですか?ソリューションには、コンピューターの構成(メモリ、ハードディスク、プロセッサ)の確認、ハードディスクの断片化のクリーニング、グラフィックカードドライバーの更新、PS設定の調整、PSの再インストール、優れたプログラミング習慣の開発が含まれます。
 H5ページの制作と従来のWebページの違いは何ですか
Apr 06, 2025 am 07:03 AM
H5ページの制作と従来のWebページの違いは何ですか
Apr 06, 2025 am 07:03 AM
従来のWebページでのH5ページの重要な違いは、モバイルの優先順位と柔軟性であり、モバイルデバイスにより適しており、開発効率が高まり、クロスプラットフォームの互換性が向上しています。具体的には、H5ページでは、セマンティックタグ、マルチメディアサポート、オフラインストレージ、地理的位置などの新機能を紹介し、モバイルエクスペリエンスを向上させます。
