

Beautiful Soup は、与えられたものをすべて解析し、ツリーのトラバース処理を行います。
BeautifulSoup ライブラリは、「タグ ツリー」を解析、トラバース、および保守するための関数ライブラリです (トラバーサルとは、特定の検索ルートをたどることを指します。シーケンス ツリー内の各ノードを 1 回だけ訪問します)。
私たちは、BeautifulSoup ライブラリを bs4 と呼びます。ライブラリをインポートするには: from bs4 import BeautifulSoup します。このうち import BeautifulSoup は主に bs4 の BeautifulSoup クラスを使用します。
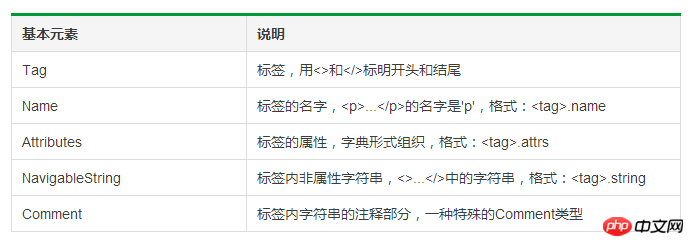
bs4ライブラリパーサー
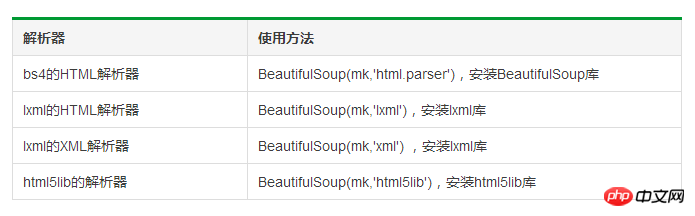
BeautifulSoupクラスの基本要素
1 import requests 2 from bs4 import BeautifulSoup 3 4 res = requests.get('') 5 soup = BeautifulSoup(res.text,'lxml') 6 print(soup.a) 7 # 任何存在于HTML语法中的标签都可以用soup.<tag>访问获得,当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个。 8 9 print(soup.a.name)10 # 每个<tag>都有自己的名字,可以通过<tag>.name获取,字符串类型11 12 print(soup.a.attrs)13 print(soup.a.attrs['class'])14 # 一个<tag>可能有一个或多个属性,是字典类型15 16 print(soup.a.string)17 # <tag>.string可以取到标签内非属性字符串18 19 soup1 = BeautifulSoup('<p><!--这里是注释--></p>','lxml')20 print(soup1.p.string)21 print(type(soup1.p.string))22 # comment是一种特殊类型,也可以通过<tag>.string取到実行結果:
& lt;a class="ログインなし" href= " ">ログイン
a
{'href': '', 'class': ['no-login']} ['no-login']
ログイン
コメントです
bs4ライブラリのHTMLの基本構造
タグツリー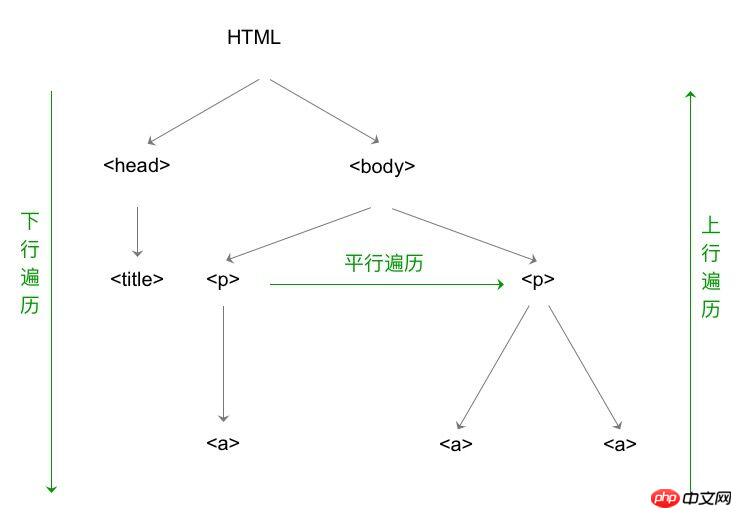
このうち、BeautifulSoup型はタグツリーのルートノードです。
1 # 遍历儿子节点2 for child in soup.body.children:3 print(child.name)4 5 # 遍历子孙节点6 for child in soup.body.descendants:7 print(child.name)
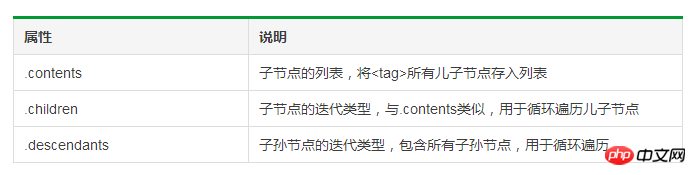 タグツリーの上方走査
タグツリーの上方走査
1 # 遍历所有先辈节点时,包括soup本身,所以要if...else...判断2 for parent in soup.a.parents:3 if parent is None:4 print(parent)5 else:6 print(parent.name)
 実行結果:
実行結果:
div iv
ボディ
html
[ドキュメント]
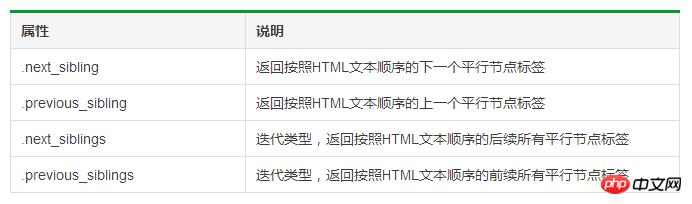
タグツリーの並列走査
1 # 遍历后续节点2 for sibling in soup.a.next_sibling:3 print(sibling)4 5 # 遍历前续节点6 for sibling in soup.a.previous_sibling:7 print(sibling)
動作環境:Mac、Python 3.6、PyCharm 2016.2参考:中国大学MOOCコース「Python Web Crawler and Information Extraction」
以上がPython -- BeautifulSoup ライブラリの紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



