MySQLテスト環境
テストテーブルは以下の通りです
1 2 3 4 5 6 7 | create table test_table2
(
id int auto_increment primary key,
pay_id int,
pay_time datetime,
other_col varchar(100)
)
|
ログイン後にコピー
テストデータを挿入するストアドプロシージャを構築するのが特徴です。 ここでストアドプロシージャは、pay_idが反復可能であることです。処理され、300Wのデータがループに挿入されます プロセスでは、100個のデータごとに重複したpay_idが挿入され、時間フィールドは一定の範囲内でランダムになります
1 2 3 4 | CREATE DEFINER=`root`@`%` PROCEDURE `test_insert`(IN `loopcount` INT)
LANGUAGE SQLNOT DETERMINISTICCONTAINS SQL
SQL SECURITY DEFINER
COMMENT ''BEGINdeclare cnt int;set cnt = 0;while cnt< loopcount doinsert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid());if (cnt mod 100 = 0) theninsert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid());end if;set cnt = cnt + 1; end while;END
|
ログイン後にコピー
call test_insert(3000000);を実行します。データ行

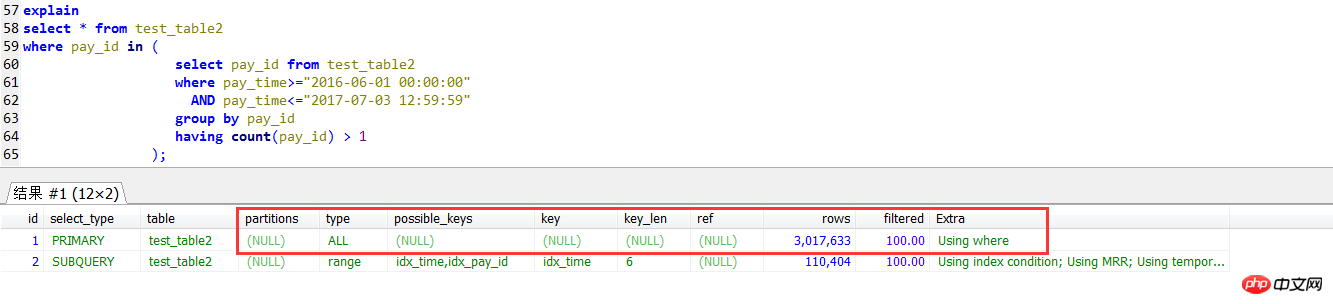
サブクエリの 2 つの記述方法
クエリの一般的な意味は、特定の期間内に 1 より大きいビジネス ID を持つデータをクエリすることであるため、記述方法は 2 つあります。
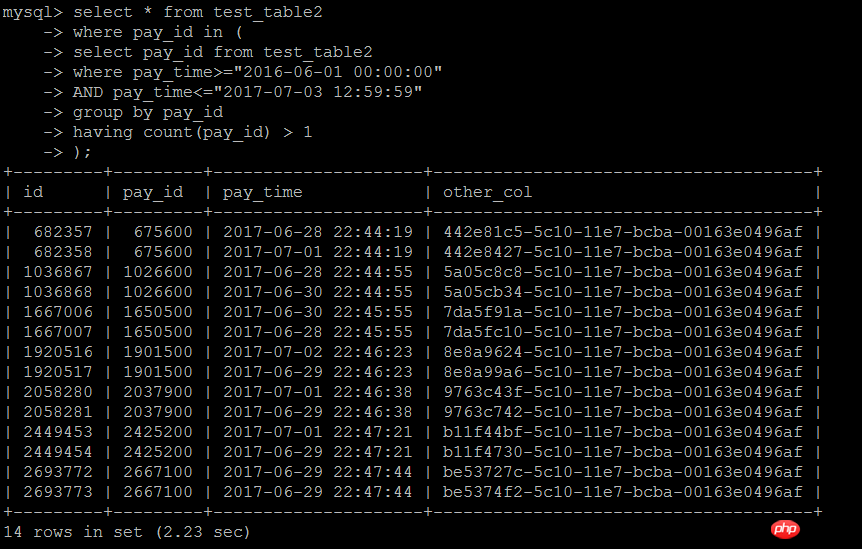
最初の書き方は以下の通りです: IN サブクエリは、一定期間内のビジネス統計行が 1 より大きいビジネス ID であり、IN サブクエリの結果に従って外側の層がクエリされます。ビジネスIDのpay_id列にインデックスを付けるだけで、ロジックは比較的シンプルです
この書き方は、データ量が多くインデックスが必要ない場合は確かに比較的非効率です
1 2 3 4 5 | select * from test_table2 force index(idx_pay_id)where pay_id in ( select pay_id from test_table2
where pay_time>="2016-06-01 00:00:00"
AND pay_time<="2017-07-03 12:59:59"
group by pay_id
having count(pay_id) > 1);
|
ログイン後にコピー
実行結果:2.23秒
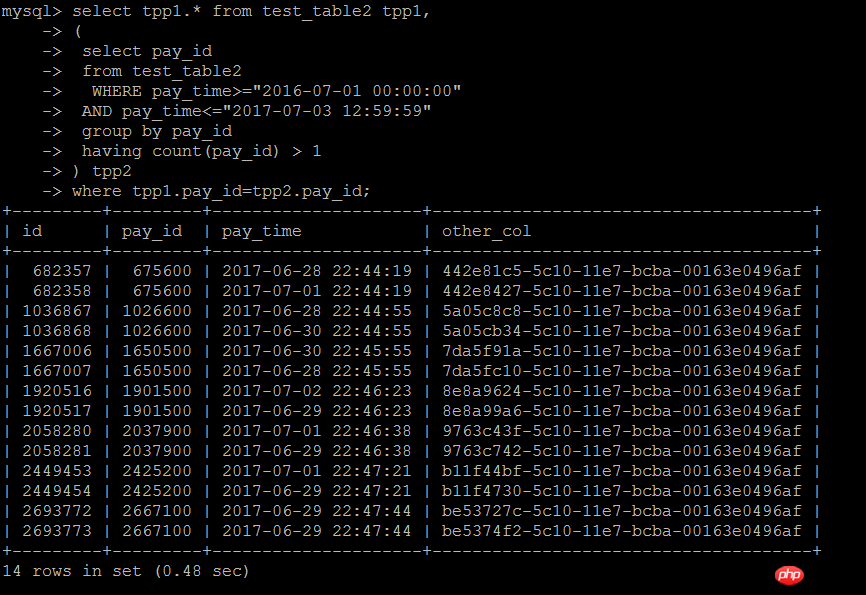
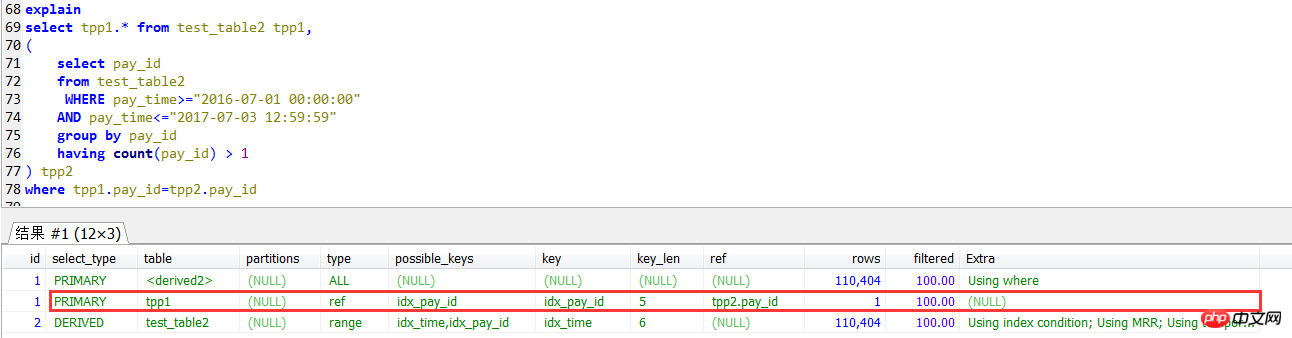
2番目の記述方法は、サブクエリとの結合です。この記述方法は、上記のINサブクエリの記述方法と同等です。次のテストでは、確かに効率が大幅に向上していることがわかりました
1 2 3 4 5 6 7 8 | select tpp1.* from test_table2 tpp1,
( select pay_id
from test_table2
WHERE pay_time>="2016-07-01 00:00:00"
AND pay_time<="2017-07-03 12:59:59"
group by pay_id
having count(pay_id) > 1) tpp2
where tpp1.pay_id=tpp2.pay_id
|
ログイン後にコピー
。実行結果:0.48秒
サブクエリ実行プランで外側のクエリを探す pay_idのインデックスを使わないフルテーブルスキャン方式です
ジョインセルフチェックの実行プランは、外側の層 (tpp1 エイリアス クエリ) は、pay_id のインデックスを使用します。
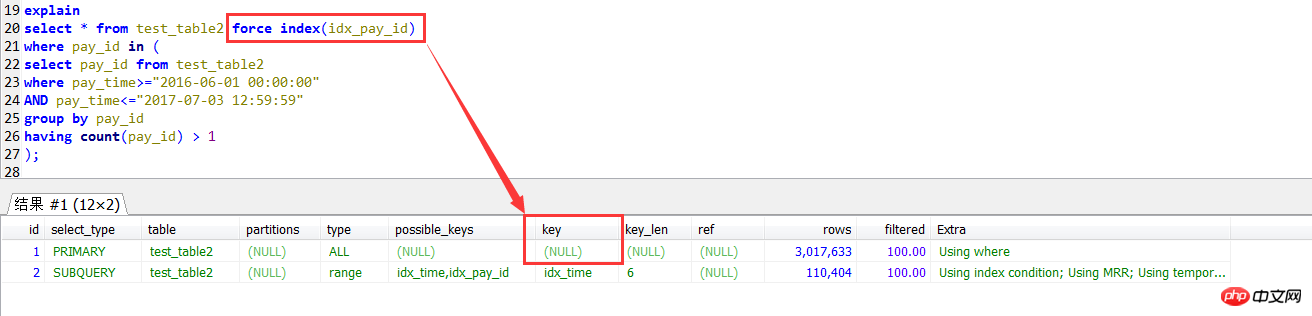
その後、最初のクエリメソッドに強制インデックスを使用したいと思いましたが、エラーは報告されませんでしたが、まったく役に立たないことがわかりました
サブクエリがダイレクトの場合。値が指定されている場合は、インデックス付きで正常に使用できます。
MySQL の IN サブクエリのサポートは確かにあまり良くないことがわかります。
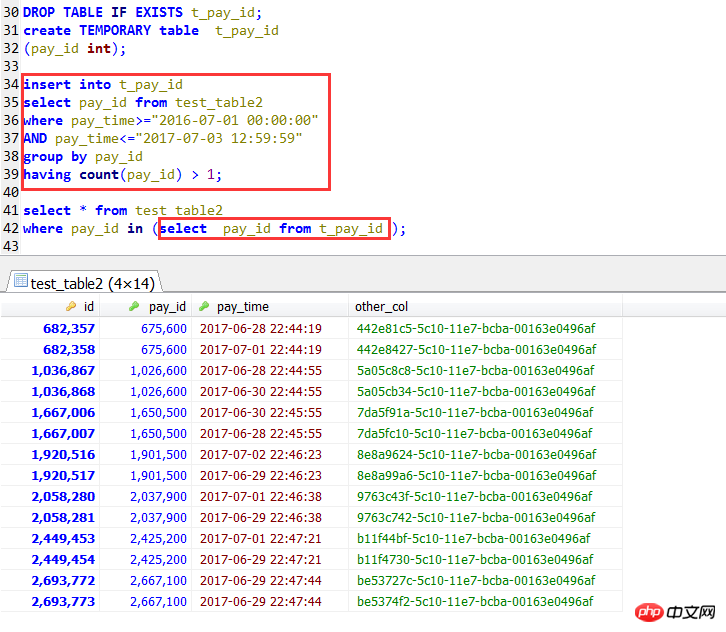
さらに: 一時テーブルを使用するケースを追加します。これは多くの結合方法より効率的ですが、IN サブクエリを直接使用するよりも効率的です。この場合、インデックスも使用できます。この場合 単純な場合には、一時テーブルを使用する必要はありません。
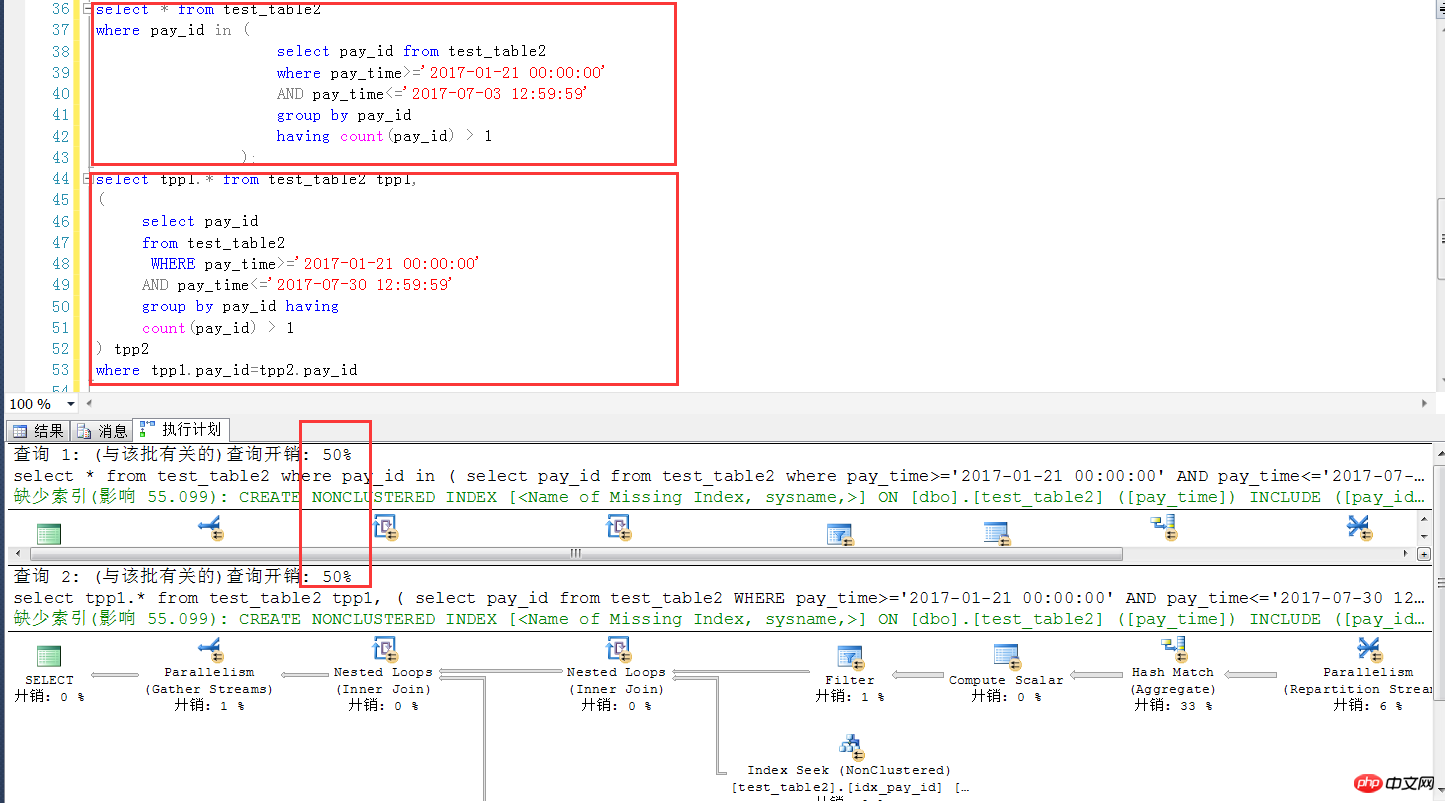
以下は、数万の同一のテストテーブル構造と数量を使用した、sqlserver 2014 での同様のケースのテストです。この場合、2 つの記述方法があることがわかります。 SQL Server で使用できます (実行計画 + 効率) この点では、SQL Server の方が MySQL よりもはるかに優れています
以下は sqlserver のテスト環境スクリプトです。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | create table test_table2
(
id int identity(1,1) primary key,
pay_id int,
pay_time datetime,
other_col varchar(100)
)begin trandeclare @i int = 0while @i<300000begininsert into test_table2 values (@i,getdate()-rand()*300,newid());
if(@i%1000=0)begininsert into test_table2 values (@i,getdate()-rand()*300,newid());endset @i = @i + 1endCOMMITGOcreate index idx_pay_id on test_table2(pay_id);
create index idx_time on test_table2(pay_time);GOselect * from test_table2
where pay_id in (select pay_id from test_table2 where pay_time>='2017-01-21 00:00:00' AND pay_time<='2017-07-03 12:59:59' group by pay_id having count(pay_id) > 1);
select tpp1.* from test_table2 tpp1,
( select pay_id
from test_table2
WHERE pay_time>='2017-01-21 00:00:00' AND pay_time<='2017-07-30 12:59:59'
group by pay_id having
count(pay_id) > 1) tpp2
where tpp1.pay_id=tpp2.pay_id
|
ログイン後にコピー
概要: MySQL データでは、バージョン 5.7.18 の時点でも、IN サブクエリは注意して使用する必要があります
以上がMySQL で 2 つのサブクエリを作成する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



