

mongoDB はページングをどのように実装しますか?

この記事では、主に mongoDB の pagination を実装する 2 つの方法を詳しく紹介します。興味のある方は、limit()、skip()、sort()、これら 3 つの関数を組み合わせてページング クエリを実行します。
以下は私のテストデータですdb.test.find().sort({"age":1});
最初のメソッド
最初のページのデータをクエリします: db .test.find().sort({"age":1}).limit(2);
2 ページ目のデータをクエリします: db.test.find().sort({"age" :1}).skip(2).limit(2);
 他のページ数などをクエリします。 。 。
他のページ数などをクエリします。 。 。
 最初のページのデータをクエリします: db.test.find().sort({"age":1}).limit(2);
最初のページのデータをクエリします: db.test.find().sort({"age":1}).limit(2);
上記の番号に従います同じ方法です。
2 番目のページのデータをクエリします:
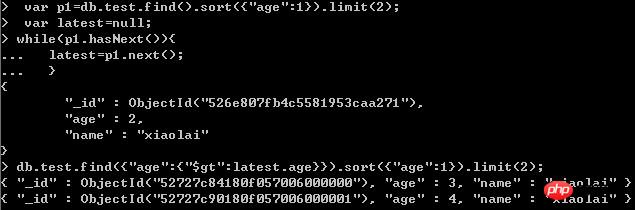 大量のデータの場合、特別な処理を行う必要があります。
大量のデータの場合、特別な処理を行う必要があります。
次の 2 つの方法があります
これは、Baidu のページング処理に似ています。最初の 700 レコードなので、パフォーマンスの問題を考慮する必要はありません。結局のところ、ほとんどの人は最初の 10 ページを見るだけで必要なものを見つけることができます
レコードの合計数は推定できるはずです。見つかったこれらのレコードの割合に基づいて
2番目の一方通行
 これと同じように、各ページに 10 個のレコードがあると仮定します
これと同じように、各ページに 10 個のレコードがあると仮定します
id page
1 1
2 1。 。 。 10 1
11 2
12 2
。 。 。 。
20 2
このようにして、最初のページを確認すると、直接10個のデータを取得することができます
データが1億個あり、1つのレコードIDが4バイト、その他の情報が1バイトを占有し、 1 つのレコードは 5 バイトを占有します
1 0000 0000 *5/(1024*1024)=476MB
このアプローチでは、一般に、データベースのクエリ時間のほとんどがデータベースへの接続に費やされます。キャッシュによりクエリが大幅に高速化されます
以上がmongoDB はページングをどのように実装しますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7622
7622
 15
1389
52
89
11
31
138
15
1389
52
89
11
31
138

 ナイキシューズの靴箱の本物と偽物の見分け方(簡単に見分けるコツをマスター)
Sep 02, 2024 pm 04:11 PM
ナイキシューズの靴箱の本物と偽物の見分け方(簡単に見分けるコツをマスター)
Sep 02, 2024 pm 04:11 PM
世界的に有名なスポーツブランドとして、ナイキのシューズは大きな注目を集めています。しかし、市場にはナイキの偽物の靴箱などの偽造品も多数出回っています。消費者の権利と利益を保護するには、本物の靴箱と偽物の靴箱を区別することが重要です。この記事では、本物の靴箱と偽物の靴箱を見分けるための簡単で効果的な方法をいくつか紹介します。 1: 外箱のタイトル ナイキの靴箱の外箱を観察すると、多くの微妙な違いを見つけることができます。ナイキの純正靴箱は通常、手触りが滑らかで、明らかな刺激臭のない高品質の紙素材を使用しています。本物の靴箱のフォントとロゴは通常、鮮明で詳細で、ぼやけや色の不一致はありません。 2: ロゴのホットスタンプのタイトル。ナイキの靴箱のロゴは通常、純正の靴箱のホットスタンプ部分に表示されます。
 DebianでMongoDB自動拡張を構成する方法
Apr 02, 2025 am 07:36 AM
DebianでMongoDB自動拡張を構成する方法
Apr 02, 2025 am 07:36 AM
この記事では、自動拡張を実現するためにDebianシステムでMongodbを構成する方法を紹介します。主な手順には、Mongodbレプリカセットとディスクスペース監視のセットアップが含まれます。 1。MongoDBのインストール最初に、MongoDBがDebianシステムにインストールされていることを確認してください。次のコマンドを使用してインストールします。sudoaptupdatesudoaptinstinstall-yymongodb-org2。mongodbレプリカセットMongodbレプリカセットの構成により、自動容量拡張を達成するための基礎となる高可用性とデータ冗長性が保証されます。 Mongodbサービスを開始:Sudosystemctlstartmongodsudosys
 ビデオのジッターに対処する方法 (ビデオのジッターを除去するための実践的なヒント)
Sep 02, 2024 pm 03:53 PM
ビデオのジッターに対処する方法 (ビデオのジッターを除去するための実践的なヒント)
Sep 02, 2024 pm 03:53 PM
手ぶれはビデオの撮影時や視聴時によく発生する問題であり、視聴体験に影響を与え、ビデオの品質を低下させます。この記事では、ビデオのジッターの問題に対処し、ビデオをより安定してスムーズにするための実践的なヒントをいくつか紹介します。 1. スタビライザー テクノロジーを使用してビデオの揺れを解消する スタビライザー デバイスの使用は、ビデオの揺れの問題を解決する最も簡単かつ効果的な方法の 1 つです。スタビライザーは、カメラのバランスをとり安定させることで、手の揺れやその他の要因によって引き起こされるジッターを軽減します。 2. ソフトウェアビデオ安定化技術の紹介 ソフトウェアビデオ安定化技術は、後処理でビデオを調整することでジッターを除去します。このテクノロジーは、キー フレームの追跡、画像安定化アルゴリズムの適用などにより、より優れたビデオ安定化を実現します。 3. ビデオのジッター検出と自動修復
 DebianでMongodbの高可用性を確保する方法
Apr 02, 2025 am 07:21 AM
DebianでMongodbの高可用性を確保する方法
Apr 02, 2025 am 07:21 AM
この記事では、Debianシステムで非常に利用可能なMongoDBデータベースを構築する方法について説明します。データのセキュリティとサービスが引き続き動作し続けるようにするための複数の方法を探ります。キー戦略:レプリカセット:レプリカセット:レプリカセットを使用して、データの冗長性と自動フェールオーバーを実現します。マスターノードが失敗すると、レプリカセットが自動的に新しいマスターノードを選択して、サービスの継続的な可用性を確保します。データのバックアップと回復:MongoDumpコマンドを定期的に使用してデータベースをバックアップし、データ損失のリスクに対処するために効果的な回復戦略を策定します。監視とアラーム:監視ツール(プロメテウス、グラファナなど)を展開して、MongoDBの実行ステータスをリアルタイムで監視し、
 銀行預金の費用対効果を高める方法 (節約戦略を明らかに)
Aug 21, 2024 pm 04:21 PM
銀行預金の費用対効果を高める方法 (節約戦略を明らかに)
Aug 21, 2024 pm 04:21 PM
現代社会では、私たちは皆銀行口座と切っても切れない関係にあり、お金を貯めることは私たちと銀行との間の最も基本的なやり取りです。しかし、多くの人は、貯蓄をより費用対効果の高いものにする方法について、一定の疑問や混乱を抱えています。この記事では、貯蓄の価値を高めるための実践的なお金の節約に関するアドバイスをいくつか提供します。パラグラフ 1 資金計画: 将来の資産増加の青写真 資金計画を立てることは、貯蓄を効果的に管理し増やすための基礎です。短期と長期の両方で財務上の目標を特定します。これらの目標に基づいて、目標ごとに必要な入金時期、金額、入金方法を設定し、具体的な貯蓄計画を立てます。変化する経済状況や個人のニーズに適応するために、計画を定期的に見直し、調整してください。第 2 段落 高金利普通預金口座の選択: 預金収益率の向上 高金利を選択する
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
 Pi Coinのメジャーアップデート:Pi Bankが来ています!
Mar 03, 2025 pm 06:18 PM
Pi Coinのメジャーアップデート:Pi Bankが来ています!
Mar 03, 2025 pm 06:18 PM
Pinetworkは、革新的なモバイルバンキングプラットフォームであるPibankを立ち上げようとしています! Pinetworkは本日、Pibankと呼ばれるElmahrosa(Face)Pimisrbankのメジャーアップデートをリリースしました。これは、従来の銀行サービスと、フィアット通貨の原子交換と暗号通貨の原子交換を実現します(resuptocursisを使用するなど、聖職者のような聖職者など、 DC)。ピバンクの魅力は何ですか?見つけましょう!ピバンクの主な機能:銀行口座と暗号通貨資産のワンストップ管理。リアルタイムトランザクションをサポートし、生物種を採用します
 Debian Mongodbでデータを暗号化する方法
Apr 12, 2025 pm 08:03 PM
Debian Mongodbでデータを暗号化する方法
Apr 12, 2025 pm 08:03 PM
DebianシステムでMongoDBデータベースを暗号化するには、次の手順に従う必要があります。ステップ1:MongoDBのインストール最初に、DebianシステムがMongoDBをインストールしていることを確認してください。そうでない場合は、インストールについては公式のMongoDBドキュメントを参照してください:https://docs.mongodb.com/manual/tutorial/install-mongodb-onedbian/-step 2:暗号化キーファイルを作成し、暗号化キーを含むファイルを作成し、正しい許可を設定します。
