

JAVA の例外の詳細な紹介

1. 例外の紹介
例外:
例外: 異常です。プログラムの実行中に発生する異常な状態。実は、これはプログラムに問題があるのです。この問題はオブジェクト指向の考え方に従って記述され、オブジェクトにカプセル化されます。問題の発生には、問題の原因、問題の名前、問題の説明などの複数の属性情報があるためです。複数の属性情報が表示される場合、最も便利な方法は情報をカプセル化することです。例外は、オブジェクト指向の考え方に従った Java のオブジェクト カプセル化です。これにより、操作や問題への対処が容易になります。
境界外のコーナーマーカー、ヌルポインターなど、さまざまな種類の問題があります。これらの問題を分類してみましょう。さらに、これらの質問には共通の内容があり、各質問には名前があり、問題の説明情報や問題の場所も含まれているため、継続的に抽出できます。異常なシステムが形成されました。
Javaの例外システムとは何ですか?
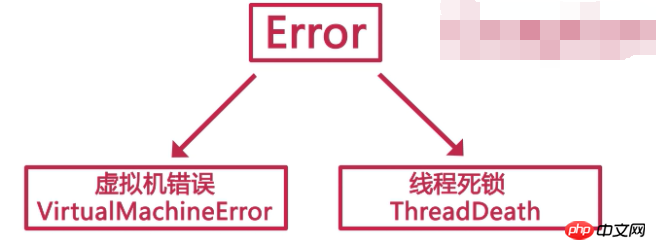
1. Java のすべての異常クラスは Throwable クラスを継承します。 Throwable には主に 2 つの主要なカテゴリがあり、1 つは Error クラス、もう 1 つは Exception クラスです。 2. Error クラスには、
仮想マシン エラー と 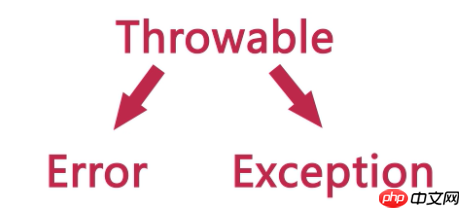 スレッド デッドロック
スレッド デッドロック
して、Program Terminator; 3.Exceptionクラス、通称「例外」と呼ばれていました。主に、コーディング、環境、およびユーザー操作の入力に関する問題を指します。例外には、主に、未チェック例外 (RuntimeException) とチェック済み例外 (その他の例外) の 2 つのカテゴリがあります。
4.ここにはリストされていない他にも多くの例外があります): null ポインター例外、配列添字の範囲外例外、型変換例外、算術例外。 RuntimeException 例外は、Java 仮想マシンによって自動的にスローされ、自動的にキャプチャされます
(例外キャプチャ ステートメントを記述しなくても、実行時にエラーがスローされます!!) ほとんどの場合、そのような例外は次の問題によって引き起こされます。コード自体を論理的に解決し、コードを改善する必要があります。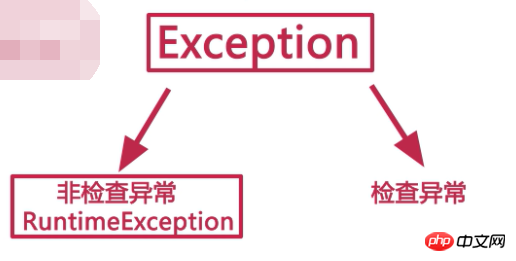
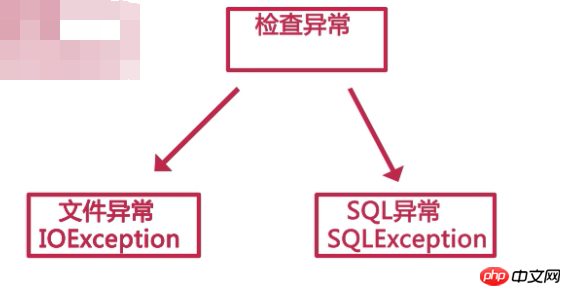
5. 例外を確認する この例外には、ファイルが存在しない、接続エラーがあるなど、さまざまな理由が考えられます。 「兄弟」の RuntimeException とは異なり、この例外を処理するにはキャプチャ ステートメントをコードに手動で追加する必要があります。これは、Java 例外ステートメントを学習するときに扱う主要な例外オブジェクトでもあります。
 2. try-catch-finally ステートメント
2. try-catch-finally ステートメント
(1) try ブロック: は例外をキャッチする責任があります try で例外が見つかると、プログラムの制御が例外ハンドラーに渡されます。キャッチブロック内。
 [try文ブロックは単独では存在できず、catchブロックやfinallyブロックと共存する必要があります]
[try文ブロックは単独では存在できず、catchブロックやfinallyブロックと共存する必要があります]
(2)catchブロック:どう対処する?たとえば、警告を発行します:
プロンプト、構成、ネットワーク接続の確認、エラーの記録など。 catch ブロックを実行した後、プログラムは catch ブロックから飛び出し、次のコードの実行を続けます。 【
catch ブロックを記述する際の注意事項: 複数の catch ブロックで処理される例外クラスは、[近く] (上から下) で処理されるため、最初にサブクラスを捕捉し、次に親クラスを捕捉する方法で処理する必要があります。】 (3) 最後に:
最終的に実行されるコード。リソースを閉じたり解放したりするために使用されます。 =============================================== == =======================
構文形式は次のとおりです:
try{//一些会抛出的异常}catch(Exception e){//第一个catch//处理该异常的代码块}catch(Exception e){//第二个catch,可以有多个catch//处理该异常的代码块}finally{//最终要执行的代码}当异常出现时,程序将终止执行,交由异常处理程序(抛出提醒或记录日志等),异常代码块外代码正常执行。 try会抛出很多种类型的异常,由多个catch块捕获多钟错误。
多重异常处理代码块顺序问题:先子类再父类(顺序不对编译器会提醒错误),finally语句块处理最终将要执行的代码。
=======================================================================
接下来,我们用实例来巩固try-catch语句吧~
先看例子:
1 package com.hysum.test; 2 3 public class TryCatchTest { 4 /** 5 * divider:除数 6 * result:结果 7 * try-catch捕获while循环 8 * 每次循环,divider减一,result=result+100/divider 9 * 如果:捕获异常,打印输出“异常抛出了”,返回-110 * 否则:返回result11 * @return12 */13 public int test1(){14 int divider=10;15 int result=100;16 try{17 while(divider>-1){18 divider--;19 result=result+100/divider;20 }21 return result;22 }catch(Exception e){23 e.printStackTrace();24 System.out.println("异常抛出了!!");25 return -1;26 }27 }28 public static void main(String[] args) {29 // TODO Auto-generated method stub30 TryCatchTest t1=new TryCatchTest();31 System.out.println("test1方法执行完毕!result的值为:"+t1.test1());32 }33 34 }运行结果:

结果分析:结果中的红色字抛出的异常信息是由e.printStackTrace()来输出的,它说明了这里我们抛出的异常类型是算数异常,后面还跟着原因:by zero(由0造成的算数异常),下面两行at表明了造成此异常的代码具体位置。
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
在上面例子中再加上一个test2()方法来测试finally语句的执行状况:
1 /** 2 * divider:除数 3 * result:结果 4 * try-catch捕获while循环 5 * 每次循环,divider减一,result=result+100/divider 6 * 如果:捕获异常,打印输出“异常抛出了”,返回result=999 7 * 否则:返回result 8 * finally:打印输出“这是finally,哈哈哈!!”同时打印输出result 9 * @return10 */11 public int test2(){12 int divider=10;13 int result=100;14 try{15 while(divider>-1){16 divider--;17 result=result+100/divider;18 }19 return result;20 }catch(Exception e){21 e.printStackTrace();22 System.out.println("异常抛出了!!");23 return result=999;24 }finally{25 System.out.println("这是finally,哈哈哈!!");26 System.out.println("result的值为:"+result);27 }28 29 }30 31 32 33 public static void main(String[] args) {34 // TODO Auto-generated method stub35 TryCatchTest t1=new TryCatchTest();36 //System.out.println("test1方法执行完毕!result的值为:"+t1.test1());37 t1.test2();38 System.out.println("test2方法执行完毕!");39 }运行结果:
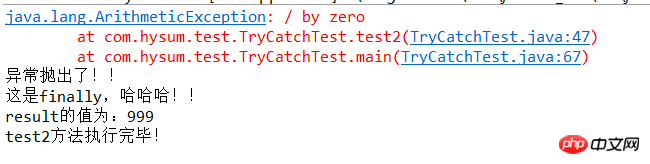
结果分析:我们可以从结果看出,finally语句块是在try块和catch块语句执行之后最后执行的。finally是在return后面的表达式运算后执行的(此时并没有返回运算后的值,而是先把要返回的值保存起来,管finally中的代码怎么样,返回的值都不会改变,仍然是之前保存的值),所以函数返回值是在finally执行前确定的;
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
这里有个有趣的问题,如果把上述中的test2方法中的finally语句块中加上return,编译器就会提示警告:finally block does not complete normally
public int test2(){
int divider=10;
int result=100;
try{
while(divider>-1){
divider--;
result=result+100/divider;
}
return result;10 }catch(Exception e){
e.printStackTrace();
System.out.println("异常抛出了!!");
return result=999;14 }finally{
System.out.println("这是finally,哈哈哈!!");
System.out.println("result的值为:"+result);
return result;//编译器警告18 }
}
分析问题: finally块中的return语句可能会覆盖try块、catch块中的return语句;如果finally块中包含了return语句,即使前面的catch块重新抛出了异常,则调用该方法的语句也不会获得catch块重新抛出的异常,而是会得到finally块的返回值,并且不会捕获异常。
解决问题:面对上述情况,其实更合理的做法是,既不在try block内部中使用return语句,也不在finally内部使用 return语句,而应该在 finally 语句之后使用return来表示函数的结束和返回。如:

>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
总结:
1、不管有木有出现异常或者try和catch中有返回值return,finally块中代码都会执行;
2、finally中最好不要包含return,否则程序会提前退出,返回会覆盖try或catch中保存的返回值。
3. e.printStackTrace()可以输出异常信息。
4. return值为-1为抛出异常的习惯写法。
5. 如果方法中try,catch,finally中没有返回语句,则会调用这三个语句块之外的return结果。
6. finally 在try中的return之后 在返回主调函数之前执行。
三、throw和throws关键字
java中的异常抛出通常使用throw和throws关键字来实现。
throw ----将产生的异常抛出,是抛出异常的一个动作。
一般会用于程序出现某种逻辑时程序员主动抛出某种特定类型的异常。如:
语法:throw (异常对象),如:
1 public static void main(String[] args) {
2 String s = "abc";
3 if(s.equals("abc")) {
4 throw new NumberFormatException();
5 } else {
6 System.out.println(s);
7 }
8 //function(); 9 }运行结果:
Exception in thread "main" java.lang.NumberFormatException at test.ExceptionTest.main(ExceptionTest.java:67)
throws----声明将要抛出何种类型的异常(声明)。
语法格式:
1 public void 方法名(参数列表)2 throws 异常列表{3 //调用会抛出异常的方法或者:4 throw new Exception();5 }当某个方法可能会抛出某种异常时用于throws 声明可能抛出的异常,然后交给上层调用它的方法程序处理。如:
1 public static void function() throws NumberFormatException{
2 String s = "abc";
3 System.out.println(Double.parseDouble(s));
4 }
5 6 public static void main(String[] args) {
7 try {
8 function();
9 } catch (NumberFormatException e) {
10 System.err.println("非数据类型不能转换。");
11 //e.printStackTrace(); 12 }
13 }throw与throws的比较
1、throws出现在方法函数头;而throw出现在函数体。
2、throws表示出现异常的一种可能性,并不一定会发生这些异常;throw则是抛出了异常,执行throw则一定抛出了某种异常对象。
3、两者都是消极处理异常的方式(这里的消极并不是说这种方式不好),只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
来看个例子:
throws e1,e2,e3只是告诉程序这个方法可能会抛出这些异常,方法的调用者可能要处理这些异常,而这些异常e1,e2,e3可能是该函数体产生的。
throw则是明确了这个地方要抛出这个异常。如:
1 void doA(int a) throws (Exception1,Exception2,Exception3){ 2 try{ 3 ...... 4 5 }catch(Exception1 e){ 6 throw e; 7 }catch(Exception2 e){ 8 System.out.println("出错了!"); 9 }10 if(a!=b)11 throw new Exception3("自定义异常");12 }分析:
1. コード ブロックで 3 つの例外 (例外 1、例外 2、例外 3) が発生する可能性があります。
2. Exception1 例外が発生した場合、それはキャッチされた後にスローされ、メソッドの呼び出し元によって処理されます。
3. Exception2 例外が発生した場合、メソッドはそれを単独で処理します (つまり、System.out.println("An error happens!");)。したがって、このメソッドは Exception2 例外をスローしなくなりました。
doA() throws Exception1,Exception3 に Exception2 を記述する必要はありません。 try-catch ステートメントでキャプチャされ、処理されているためです。
4.Exception3 例外は、メソッドの特定のロジックにおけるエラーです。 ロジック エラーの場合に例外 Exception3 がスローされた場合、メソッドの呼び出し元もこの例外を処理する必要があります。 。ここではカスタム例外が使用されます。これについては以下で説明します。
>>>>>>>>>>>>>>>>>>>>>>>> ;>>>>>>>>>>>>>>>>>>
throws キーワードを使用する場合、次の点に注意する必要があります: 1. スローの例外リストは、1 つまたは複数の例外をスローします。
2. メソッド内で例外をスローするメソッドを呼び出します。本体を使用するか、最初に例外をスローします: throw new Exception() を使用します。 throw は、「例外をスローする」アクションを示すためにメソッド本体に記述されます。
3. メソッドが例外をスローするメソッドを呼び出す場合、この例外をキャッチしようとするための try catch ステートメントを追加するか、処理のために上位レベルの呼び出し元に例外をスローするためのステートメントを追加する必要があります
> >>>>>>>>>>>>>>>>>>>>>>> >>>>>>>>>>>>>>>>>>>>>>>>>カスタム例外
カスタム例外を使用する必要があるのはなぜですか? メリットは何ですか?
1. プロジェクトは基本的にモジュールまたは関数で開発されます。カスタム例外クラスを使用すると、外部例外の表示方法が統一されます。 2. 特定の検証や問題が発生した場合、現在のリクエストを直接終了する必要がある場合があります。このとき、プロジェクトで SpringMVC を使用している場合、これは比較的新しいものです。このバージョンにはコントローラー拡張機能があるため、@ControllerAdvice アノテーションを使用してコントローラー拡張クラスを作成して、カスタム例外をインターセプトし、対応する情報をフロントエンドに応答することができます
。3. カスタム例外は、「neutral」.equals(sex) など、プロジェクト内の特定の
特別なビジネス ロジック で例外をスローすることができます。性別がニュートラルに等しい場合に例外をスローする必要がありますが、Java には例外がありません。そのような例外。システム内の一部のエラーは Java 構文に準拠していますが、プロジェクトのビジネス ロジックには準拠していません。 4. カスタム例外を使用して、関連する例外を継承し、処理された例外情報をスローします 基になる例外を非表示にすることができるため、より安全であり、例外情報がより直感的になります。 カスタム例外は、スローしたい情報をスローできます。スローされた情報を使用して、例外名に基づいて例外が発生した場所を特定し、例外プロンプト情報に基づいてプログラムを変更できます。 。たとえば、NullPointException の場合、スタック情報を出力せずに、「xxx は null」という情報をスローして例外の場所を特定できます。
カスタム例外を使用する理由と利点について説明した後、カスタム例外の問題点
を見てみましょう:言うまでもなく、JVM (Java Virtual) Machine) は 1 つのカスタム例外を自動的にスローします。また、JVM がカスタム例外を自動的に処理することも期待できません。例外の検出、例外のスロー、および例外の処理の作業は、コード内の例外処理メカニズムを使用してプログラマ自身が行う必要があります。これに応じて開発コストと作業負荷が増加するため、プロジェクトがそれを必要としない場合は、必ずしもカスタム例外を使用する必要はありません。自分で検討できる必要があります。
最後に、カスタム例外を使用する方法を見てみましょう:
Java では例外をカスタマイズできます。独自の例外クラスを作成する場合は、留意すべき点がいくつかあります。すべての例外は Throwable のサブクラスである必要があります。 如果希望写一个检查性异常类,则需要继承 Exception 类。 如果你想写一个运行时异常类,那么需要继承 RuntimeException 类。 可以像下面这样定义自己的异常类: class MyException extends Exception{ } 我们来看一个实例: 使用自定义异常抛出异常信息: 运行结果: 就是这么简单,可以根据实际业务需求去抛出相应的自定义异常。 异常需要封装,但是仅仅封装还是不够的,还需要传递异常。 异常链是一种面向对象编程技术,指将捕获的异常包装进一个新的异常中并重新抛出的异常处理方式。原异常被保存为新异常的一个属性(比如cause)。这样做的意义是一个方法应该抛出定义在相同的抽象层次上的异常,但不会丢弃更低层次的信息。 我可以这样理解异常链: 把捕获的异常包装成新的异常,在新异常里添加原始的异常,并将新异常抛出,它们就像是链式反应一样,一个导致(cause)另一个。这样在最后的顶层抛出的异常信息就包括了最底层的异常信息。 比如我们的JEE项目一般都又三层:持久层、逻辑层、展现层,持久层负责与数据库交互,逻辑层负责业务逻辑的实现,展现层负责UI数据的处理。 有这样一个模块:用户第一次访问的时候,需要持久层从user.xml中读取数据,如果该文件不存在则提示用户创建之,那问题就来了:如果我们直接把持久层的异常FileNotFoundException抛弃掉,逻辑层根本无从得知发生任何事情,也就不能为展现层提供一个友好的处理结果,最终倒霉的就是展现层:没有办法提供异常信息,只能告诉用户“出错了,我也不知道出了什么错了”—毫无友好性而言。 正确的做法是先封装,然后传递,过程如下: 1.把FileNotFoundException封装为MyException。 2.抛出到逻辑层,逻辑层根据异常代码(或者自定义的异常类型)确定后续处理逻辑,然后抛出到展现层。 3.展现层自行确定展现什么,如果管理员则可以展现低层级的异常,如果是普通用户则展示封装后的异常。 >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> 実行結果: 結果分析: コンソールが最初に元の例外を出力し、これが e.getCause(); によって出力され、次に e.printStackTrace() が出力されることがわかります。これはここで確認できます。 原因: 元の例外は e.getCause() の出力と一致します。これが異常な連鎖を形成してしまうのです。 initCause() の機能は、元の例外をラップすることです。最下層でどのような例外が発生したかを知りたい場合は、getCause() を呼び出すことで元の例外を取得できます。 >>>>>>>>>>>>>>>>>>>>>>>> ;>>>>>>>>>>>>>>>>>>>>>> 良いコーディング習慣: 1.ランタイム例外を処理するには、ロジックを使用して try-catch 処理を合理的に回避し、支援します 2. 複数の catch ブロックの後に、見逃される可能性のある例外を処理するために catch (例外) を追加できます 3、不確実なコードの場合は、次のこともできます。潜在的な例外を処理するために try-catch を追加します 4. 可能な限り例外を処理するようにしてください。印刷するには、必ず printStackTrace() を呼び出してください 5. 例外を処理する方法は、さまざまな状況に応じて異なります。 6. 占有されているリソースを解放するために、finally ステートメント ブロックを追加してみます 1 package com.hysum.test; 2 3 public class MyException extends Exception { 4 /** 5 * 错误编码 6 */ 7 private String errorCode; 8 9 10 public MyException(){}11 12 /**13 * 构造一个基本异常.14 *15 * @param message16 * 信息描述17 */18 public MyException(String message)19 {20 super(message);21 }22 23 24 25 public String getErrorCode() {26 return errorCode;27 }28 29 public void setErrorCode(String errorCode) {30 this.errorCode = errorCode;31 }32 33 34 } 1 package com.hysum.test; 2 3 public class Main { 4 5 public static void main(String[] args) { 6 // TODO Auto-generated method stub 7 String[] sexs = {"男性","女性","中性"}; 8 for(int i = 0; i < sexs.length; i++){ 9 if("中性".equals(sexs[i])){10 try {11 throw new MyException("不存在中性的人!");12 } catch (MyException e) {13 // TODO Auto-generated catch block14 e.printStackTrace();15 }16 }else{17 System.out.println(sexs[i]);18 }19 }
20 }21 22 }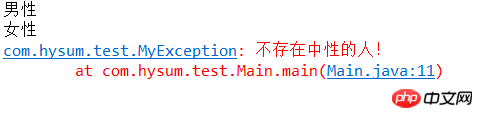
四、java中的异常链
》场景
》示例
1 package com.hysum.test; 2 3 public class Main { 4 public void test1() throws RuntimeException{ 5 String[] sexs = {"男性","女性","中性"}; 6 for(int i = 0; i < sexs.length; i++){ 7 if("中性".equals(sexs[i])){ 8 try { 9 throw new MyException("不存在中性的人!");10 } catch (MyException e) {11 // TODO Auto-generated catch block12 e.printStackTrace();13 RuntimeException rte=new RuntimeException(e);//包装成RuntimeException异常14 //rte.initCause(e);15 throw rte;//抛出包装后的新的异常16 }17 }else{18 System.out.println(sexs[i]);19 }20 }
21 }22 public static void main(String[] args) {23 // TODO Auto-generated method stub24 Main m =new Main();25 26 try{27 m.test1();28 }catch (Exception e){29 e.printStackTrace();30 e.getCause();//获得原始异常31 }32 33 }34 35 }
例外を行うことをお勧めします。システムを開発するときは、例外を「飲み込んだり」したり、例外を「裸で」スローしたりする必要はありません。これは、例外をカプセル化してからスローするか、例外チェーンを通過させることによって実現できます。より堅牢で使いやすくなりました。
5. 結論 Java 例外処理の知識は複雑で、理解するのが少し難しいです
以上がJAVA の例外の詳細な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7549
7549
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90


 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Bootは、Java開発に革命をもたらす堅牢でスケーラブルな、生産対応のJavaアプリケーションの作成を簡素化します。 スプリングエコシステムに固有の「構成に関する慣習」アプローチは、手動のセットアップを最小化します。
