
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url

Python で qq music をクロールする処理の例

1. はじめに
QQ ミュージックにはまだたくさんの音楽がありますが、時々、良い音楽をダウンロードしたいのですが、Web ページでダウンロードするたびにログインする必要があります。 。そこで、qqmusic クローラーの登場です。少なくとも、for ループ クローラーにとって最も重要なことは、クロールされる要素の URL を見つけることだと思います。以下を見てみましょう (間違っていても笑わないでください)
<br>
2. Python が QQ 音楽シングルをクロールします
MOOC.com で見たビデオで非常にわかりやすく説明されています。また、一般的なクローラーの作成手順に従います。
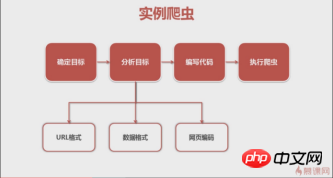
まず、今回はQQ Musicの歌手Andy Lauのシングルをクロールしました。 (Baidu Encyclopedia) -> 分析対象 (戦略: URL 形式 (範囲)、データ形式、Web ページのエンコーディング) -> コードを作成 -> クローラーを実行
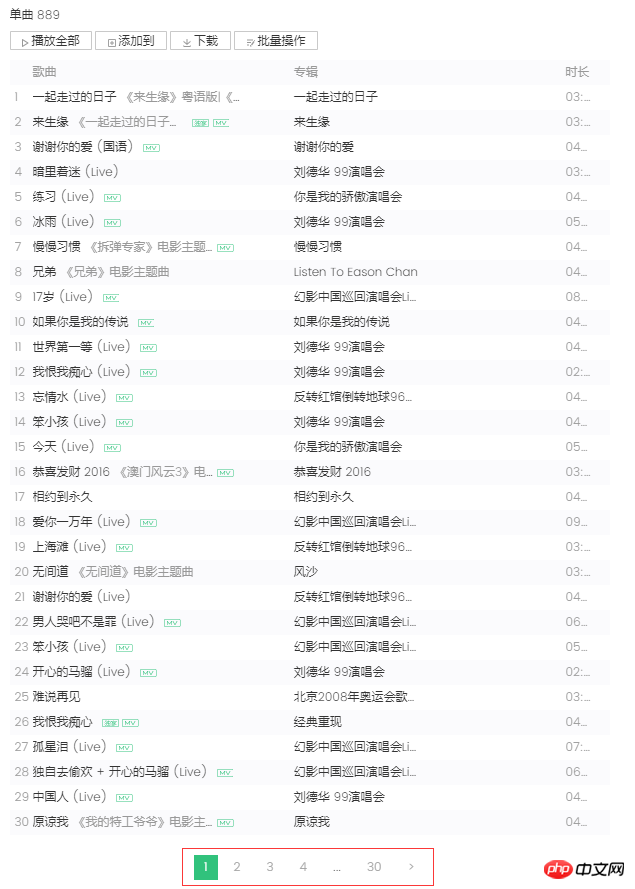
2. 分析対象link : 左のスクリーンショットを見ると、シングル曲の情報がページングされていて、各ページに 30 項目、合計 30 ページ表示されていることがわかります。ページ番号または右端の「>」をクリックすると、ブラウザがサーバーに非同期 Ajax リクエストを送信し、これを表す begin パラメータと num パラメータが表示されます。それぞれ開始曲の添え字 (スクリーンショットは 2 ページ目、開始添え字は 30) で、1 ページは 30 項目を返し、サーバーは曲情報を json 形式で返して応答します (MusicJsonCallbacksinger_track({"code":0,"data": {"list":[{"Flisten_count1":. .....]}))、曲情報だけを取得したい場合は、リンク リクエストを直接結合し、返された json 形式のデータを解析できます。ここでは、データ形式を直接解析する方法を使用せず、各ページの単一情報を取得して解析した後、「>」をクリックして次のページに移動し、すべての情報が取得されるまで解析を続けます。単一の情報が解析されて記録されます。最後に、各シングルのリンクをリクエストして、詳細なシングル情報を取得します。
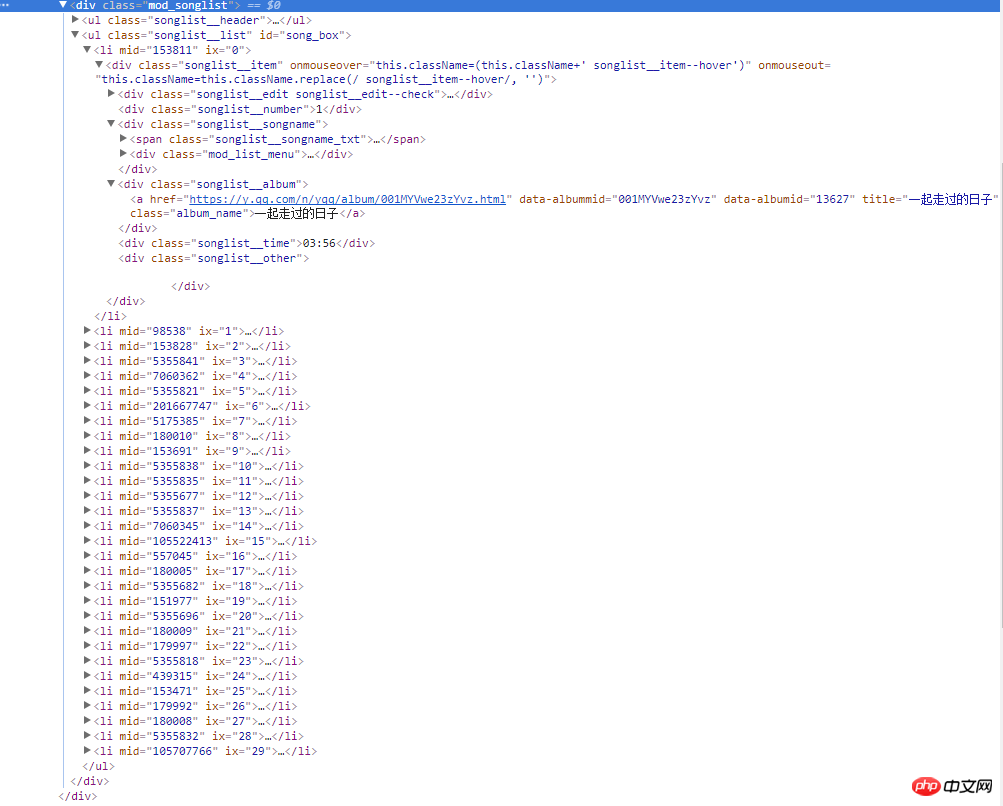
右側のスクリーンショットは、Web ページのソース コードです。すべての曲情報は、クラス名が mod_songlist の div フローティング レイヤー内にあり、クラス名が Songlist_list の順序なしリスト ul の下にあります。 li 要素はシングルを表示します。クラス名 Songlist__album の下の a タグには、シングルのリンク、名前、期間が含まれます。 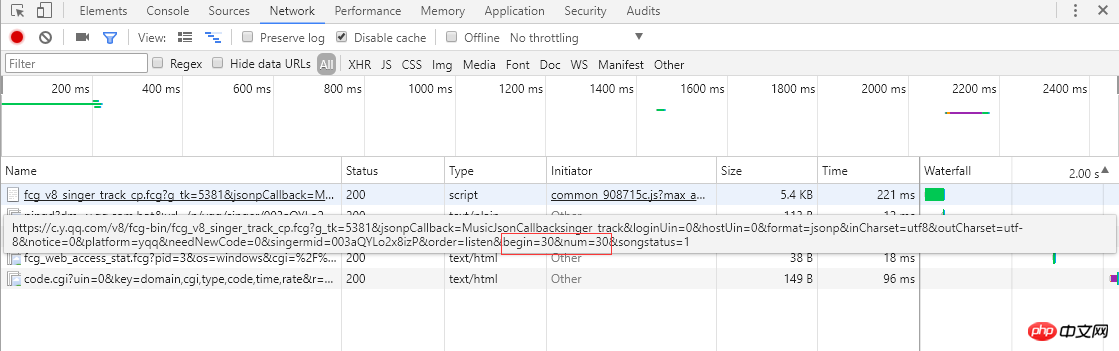
1) ここでは、Python の Urllib 標準ライブラリを使用し、ダウンロード メソッドをカプセル化します。 ) を解析しますWeb ページのコンテンツ、ここではサードパーティのプラグイン BeautifulSoup が使用されます。詳細については、BeautifulSoup API を参照してください。
def download(url, user_agent='wswp', num_retries=2):
if url is None:
return None
print('Downloading:', url)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
request = urllib.request.Request(url, headers=headers) # 设置用户代理wswp(Web Scraping with Python)
try:
html = urllib.request.urlopen(request).read().decode('utf-8')
except urllib.error.URLError as e:
print('Downloading Error:', e.reason)
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
# retry when return code is 5xx HTTP erros
return download(url, num_retries-1) # 请求失败,默认重试2次,
return htmldef music_scrapter(html, page_num=0):
try:
soup = BeautifulSoup(html, 'html.parser')
mod_songlist_div = soup.find_all('div', class_='mod_songlist')
songlist_ul = mod_songlist_div[1].find('ul', class_='songlist__list')
'''开始解析li歌曲信息'''
lis = songlist_ul.find_all('li')
for li in lis:
a = li.find('div', class_='songlist__album').find('a')
music_url = a['href'] # 单曲链接
urls.add_new_url(music_url) # 保存单曲链接
# print('music_url:{0} '.format(music_url))
print('total music link num:%s' % len(urls.new_urls))
next_page(page_num+1)
except TimeoutException as err:
print('解析网页出错:', err.args)
return next_page(page_num + 1)
return Nonedef get_music():
try:
while urls.has_new_url():
# print('urls count:%s' % len(urls.new_urls))
'''跳转到歌曲链接,获取歌曲详情'''
new_music_url = urls.get_new_url()
print('url leave count:%s' % str( len(urls.new_urls) - 1))
html_data_info = download(new_music_url)
# 下载网页失败,直接进入下一循环,避免程序中断
if html_data_info is None:
continue
soup_data_info = BeautifulSoup(html_data_info, 'html.parser')
if soup_data_info.find('div', class_='none_txt') is not None:
print(new_music_url, ' 对不起,由于版权原因,暂无法查看该专辑!')
continue
mod_songlist_div = soup_data_info.find('div', class_='mod_songlist')
songlist_ul = mod_songlist_div.find('ul', class_='songlist__list')
lis = songlist_ul.find_all('li')
del lis[0] # 删除第一个li
# print('len(lis):$s' % len(lis))
for li in lis:
a_songname_txt = li.find('div', class_='songlist__songname').find('span', class_='songlist__songname_txt').find('a')
if 'https' not in a_songname_txt['href']: #如果单曲链接不包含协议头,加上
song_url = 'https:' + a_songname_txt['href']
song_name = a_songname_txt['title']
singer_name = li.find('div', class_='songlist__artist').find('a').get_text()
song_time =li.find('div', class_='songlist__time').get_text()
music_info = {}
music_info['song_name'] = song_name
music_info['song_url'] = song_url
music_info['singer_name'] = singer_name
music_info['song_time'] = song_time
collect_data(music_info)
except Exception as err: # 如果解析异常,跳过
print('Downloading or parse music information error continue:', err.args)<span style="font-size: 16px;">爬虫跑起来了,一页一页地去爬取专辑的链接,并保存到集合中,最后通过get_music()方法获取单曲的名称,链接,歌手名称和时长并保存到Excel文件中。</span><br><span style="font-size: 14px;"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/a1138f33f00f8d95b52fbfe06e562d24-4.png" class="lazy" alt="" style="max-width:90%" style="max-width:90%"><strong><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/9282b5f7a1dc4a90cee186c16d036272-5.png" class="lazy" alt=""></strong></span>
<br>
2.url リンク マネージャーは、コレクション データ構造を使用して単一のリンクを保存します。なぜコレクションを使用するのですか?同じアルバムから複数のシングルが (同じアルバム URL で) 取得される可能性があるため、これによりリクエストの数を減らすことができます。<br>
class UrlManager(object):<br> def __init__(self):<br> self.new_urls = set() # 使用集合数据结构,过滤重复元素<br> self.old_urls = set() # 使用集合数据结构,过滤重复元素
def add_new_url(self, url):<br> if url is None:<br> return<br> if url not in self.new_urls and url not in self.old_urls:<br> self.new_urls.add(url)<br><br> def add_new_urls(self, urls):<br> if urls is None or len(urls) == 0:<br> return<br> for url in urls:<br> self.add_new_url(url)<br><br> def has_new_url(self):<br> return len(self.new_urls) != 0<br><br> def get_new_url(self):<br> new_url = self.new_urls.pop()<br> self.old_urls.add(new_url)<br> return new_url<br><br>
ログイン後にコピー
4. 追記def add_new_url(self, url):<br> if url is None:<br> return<br> if url not in self.new_urls and url not in self.old_urls:<br> self.new_urls.add(url)<br><br> def add_new_urls(self, urls):<br> if urls is None or len(urls) == 0:<br> return<br> for url in urls:<br> self.add_new_url(url)<br><br> def has_new_url(self):<br> return len(self.new_urls) != 0<br><br> def get_new_url(self):<br> new_url = self.new_urls.pop()<br> self.old_urls.add(new_url)<br> return new_url<br><br>
最後に、QQ Music のシングル情報をクロールすることに成功したことをお祝いしなければなりません。今回は、Selenium が不可欠な単一のクロールに成功しました。今回は、Selenium のいくつかの簡単な機能のみを使用しました。今後は、クローラーだけでなく UI 自動化の面でも Selenium について詳しく学習します。
今後最適化が必要な点:
1. ダウンロードリンクが多く、一つ一つダウンロードするのが遅い 今後はマルチスレッドの同時ダウンロードを使用する予定です。
2. ダウンロード速度が速すぎるため、サーバーが IP を無効にし、同じドメイン名へのアクセスが頻繁に発生する問題を回避するために、各リクエストの間に待機メカニズムと待機間隔が設けられています。
3. Web ページの解析は重要なプロセスです。現在、BeautifulSoup ライブラリは lxml ほど効率的ではありません。 lxmlは後で。
以上がPython で qq music をクロールする処理の例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
18
19
15
1376
52
77
11
18
19

 PSフェザーリングは、遷移の柔らかさをどのように制御しますか?
Apr 06, 2025 pm 07:33 PM
PSフェザーリングは、遷移の柔らかさをどのように制御しますか?
Apr 06, 2025 pm 07:33 PM
羽毛の鍵は、その漸進的な性質を理解することです。 PS自体は、勾配曲線を直接制御するオプションを提供しませんが、複数の羽毛、マッチングマスク、および細かい選択により、半径と勾配の柔らかさを柔軟に調整して、自然な遷移効果を実現できます。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
MySQLには、無料のコミュニティバージョンと有料エンタープライズバージョンがあります。コミュニティバージョンは無料で使用および変更できますが、サポートは制限されており、安定性要件が低く、技術的な能力が強いアプリケーションに適しています。 Enterprise Editionは、安定した信頼性の高い高性能データベースを必要とするアプリケーションに対する包括的な商業サポートを提供し、サポートの支払いを喜んでいます。バージョンを選択する際に考慮される要因には、アプリケーションの重要性、予算編成、技術スキルが含まれます。完璧なオプションはなく、最も適切なオプションのみであり、特定の状況に応じて慎重に選択する必要があります。
 PSフェザーリングをセットアップする方法は?
Apr 06, 2025 pm 07:36 PM
PSフェザーリングをセットアップする方法は?
Apr 06, 2025 pm 07:36 PM
PSフェザーリングは、イメージエッジブラー効果であり、エッジエリアのピクセルの加重平均によって達成されます。羽の半径を設定すると、ぼやけの程度を制御でき、値が大きいほどぼやけます。半径の柔軟な調整は、画像とニーズに応じて効果を最適化できます。たとえば、キャラクターの写真を処理する際に詳細を維持するためにより小さな半径を使用し、より大きな半径を使用してアートを処理するときにかすんだ感覚を作成します。ただし、半径が大きすぎるとエッジの詳細を簡単に失う可能性があり、効果が小さすぎると明らかになりません。羽毛効果は画像解像度の影響を受け、画像の理解と効果の把握に従って調整する必要があります。
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 MySQLインストール後に開始できないサービスのソリューション
Apr 08, 2025 am 11:18 AM
MySQLインストール後に開始できないサービスのソリューション
Apr 08, 2025 am 11:18 AM
MySQLは開始を拒否しましたか?パニックにならないでください、チェックしてみましょう!多くの友人は、MySQLのインストール後にサービスを開始できないことを発見し、彼らはとても不安でした!心配しないでください、この記事はあなたがそれを落ち着いて対処し、その背後にある首謀者を見つけるためにあなたを連れて行きます!それを読んだ後、あなたはこの問題を解決するだけでなく、MySQLサービスの理解と問題のトラブルシューティングのためのあなたのアイデアを改善し、より強力なデータベース管理者になることができます! MySQLサービスは開始に失敗し、単純な構成エラーから複雑なシステムの問題に至るまで、多くの理由があります。最も一般的な側面から始めましょう。基本知識:サービススタートアッププロセスMYSQLサービススタートアップの簡単な説明。簡単に言えば、オペレーティングシステムはMySQL関連のファイルをロードし、MySQLデーモンを起動します。これには構成が含まれます
 MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLのインストール障害の主な理由は次のとおりです。1。許可の問題、管理者として実行するか、SUDOコマンドを使用する必要があります。 2。依存関係が欠落しており、関連する開発パッケージをインストールする必要があります。 3.ポート競合では、ポート3306を占めるプログラムを閉じるか、構成ファイルを変更する必要があります。 4.インストールパッケージが破損しているため、整合性をダウンロードして検証する必要があります。 5.環境変数は誤って構成されており、環境変数はオペレーティングシステムに従って正しく構成する必要があります。これらの問題を解決し、各ステップを慎重に確認して、MySQLを正常にインストールします。
