

Pandas データ処理例の表示: 世界的な上場企業のデータ収集
現在、フォーブス誌の 2016 年世界トップ 2000 上場企業データのコピーが手元にありますが、元のデータは標準化されていないため、さらに使用する前に処理する必要があります。
この記事では、データ整理のためのパンダの使用法を実践的な例を通して紹介します。
いつものように、最初に私の動作環境について話させてください、次のとおりです:
windows 7、64-bit
python 3.5
pandas version 0.19.2
オリジナルを入手した後データ、まずはデータを見て、どのようなデータ結果が必要なのかを考えてみましょう。
生データは次のとおりです:
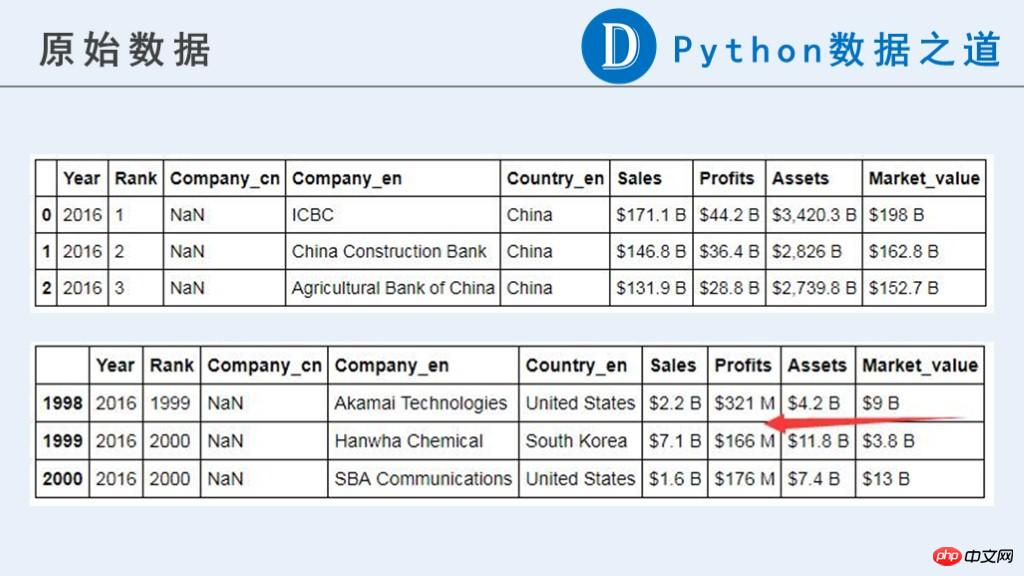
この記事では、将来の使用のために次の暫定的な結果が必要です。
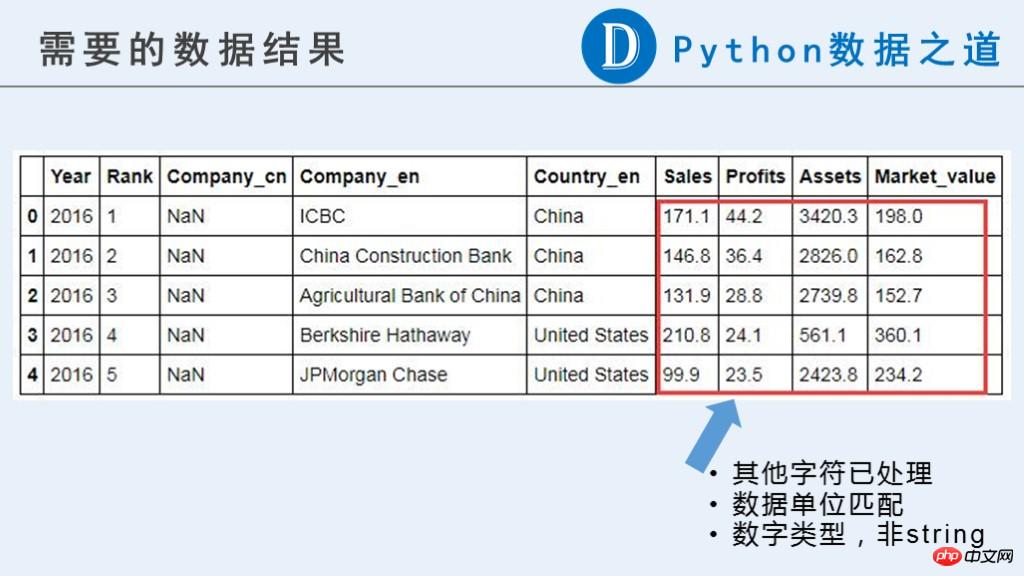
元のデータでは、企業に関連するデータ (「Sales」、「Profits」、「Assets」、「Market_value」) が、現時点では計算に使用できる数値タイプではないことがわかります。
元のコンテンツには、通貨記号「$」、「-」、純粋な文字で構成された文字列、その他異常と思われる情報が含まれています。さらに、これらのデータの単位は一貫していません。それぞれ「B」(Billion、10億)と「M」(Million、100万)で表されます。以降の計算の前に単位の統一が必要です。
1 処理方法 Method-1
最初に思い浮かぶ処理アイデアは、データ情報を数十億 ('B') と数百万 ('M') に分割し、個別に処理し、最後にそれらをマージすることです。プロセスは次のとおりです。
データをロードして列の名前を追加します
import pandas as pd
df_2016 = pd.read_csv('data_2016.csv', encoding='gbk',header=None)# 更新列名df_2016.columns = ['Year', 'Rank', 'Company_cn','Company_en', 'Country_en', 'Sales', 'Profits', 'Assets', 'Market_value']
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)データを10億単位で取得します('B')
# 数据单位为 B的数据(Billion,十亿)df_2016_b = df_2016[df_2016['Sales'].str.endswith('B')]
print(df_2016_b.shape)
df_2016_bデータを数百万単位で取得します('M')
# 数据单位为 M的数据(Million,百万)df_2016_m = df_2016[df_2016['Sales'].str.endswith('M')]
print(df_2016_m.shape)
df_2016_mこの方法は理解するのが比較的簡単ですが、操作がより煩雑になり、特に処理するデータの列が多い場合は、時間がかかります。
これ以上の処理についてはここでは説明しません。もちろん、この方法を試すこともできます。
以下はもう少し簡単な方法です。
2 処理方法 方法-2
2.1 データの読み込み
最初のステップはデータの読み込みです。これは方法-1と同じです。
以下は「Sales」列の処理です
2.2 関連する異常な文字を置換します
まず、ドル通貨記号「$」、純粋なアルファベット文字列「unknown」、「」などの関連する異常な文字を置換します。 B'。 ここでは、「B」を直接置き換えることができるように、データ単位を一律に 10 億単位に編成したいと考えています。また、「M」にはさらに多くの処理ステップが必要です。
2.3 「M」関連データの処理
数百万個の「M」を単位とするデータ、つまり「M」で終わるデータを処理する場合の考え方は以下の通りです。
(1) 検索条件マスクを設定する。
( 2) 文字列「M」を null 値に置き換えます
(3)用pd.to_numeric()转换为数字
(4)除以1000,转换为十亿美元,与其他行的数据一致
上面两个步骤相关的代码如下:
# 替换美元符号df_2016['Sales'] = df_2016['Sales'].str.replace('$','')# # 查看异常值,均为字母(“undefined”)# df_2016[df_2016['Sales'].str.isalpha()]# 替换异常值“undefined”为空白# df_2016['Sales'] = df_2016['Sales'].str.replace('undefined','')df_2016['Sales'] = df_2016['Sales'].str.replace('^[A-Za-z]+$','')# 替换符号十亿美元“B”为空白,数字本身代表的就是十亿美元为单位df_2016['Sales'] = df_2016['Sales'].str.replace('B','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df_2016['Sales'].str.endswith('M')
df_2016.loc[mask, 'Sales'] = pd.to_numeric(df_2016.loc[mask, 'Sales'].str.replace('M', ''))/1000df_2016['Sales'] = pd.to_numeric(df_2016['Sales'])
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)用同样类似的方法处理其他列
可以看到,这个方法比第一种方法还是要方便很多。当然,这个方法针对DataFrame的每列数据都要进行相关的操作,如果列数多了,也还是比较繁琐的。
有没有更方便一点的方法呢。 答案是有的。
插播一条硬广:技术文章转发太多。文章来自微信公众号“Python数据之道”(ID:PyDataRoad)。
3 处理方法 Method-3
在Method-2的基础上,将处理方法写成更通用的数据处理函数,根据数据的结构,拓展更多的适用性,则可以比较方便的处理相关数据。
3.1 加载数据
第一步还是加载数据,跟Method-1是一样的。
3.2 编写数据处理的自定义函数
参考Method-2的处理过程,编写数据处理的自定义函数’pro_col’,并在Method-2的基础上拓展其他替换功能,使之适用于这四列数据(“Sales”,“Profits”,“Assets”,“Market_value”)。
函数编写的代码如下:
def pro_col(df, col): # 替换相关字符串,如有更多的替换情形,可以自行添加df[col] = df[col].str.replace('$','')
df[col] = df[col].str.replace('^[A-Za-z]+$','')
df[col] = df[col].str.replace('B','')# 注意这里是'-$',即以'-'结尾,而不是'-',因为有负数df[col] = df[col].str.replace('-$','')
df[col] = df[col].str.replace(',','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df[col].str.endswith('M')
df.loc[mask, col] = pd.to_numeric(df.loc[mask, col].str.replace('M',''))/1000# 将字符型的数字转换为数字类型df[col] = pd.to_numeric(df[col])return df3.3 将自定义函数进行应用
针对DataFrame的每列,应用该自定义函数,进行数据处理,得到需要的结果。
pro_col(df_2016, 'Sales')
pro_col(df_2016, 'Profits')
pro_col(df_2016, 'Assets')
pro_col(df_2016, 'Market_value')
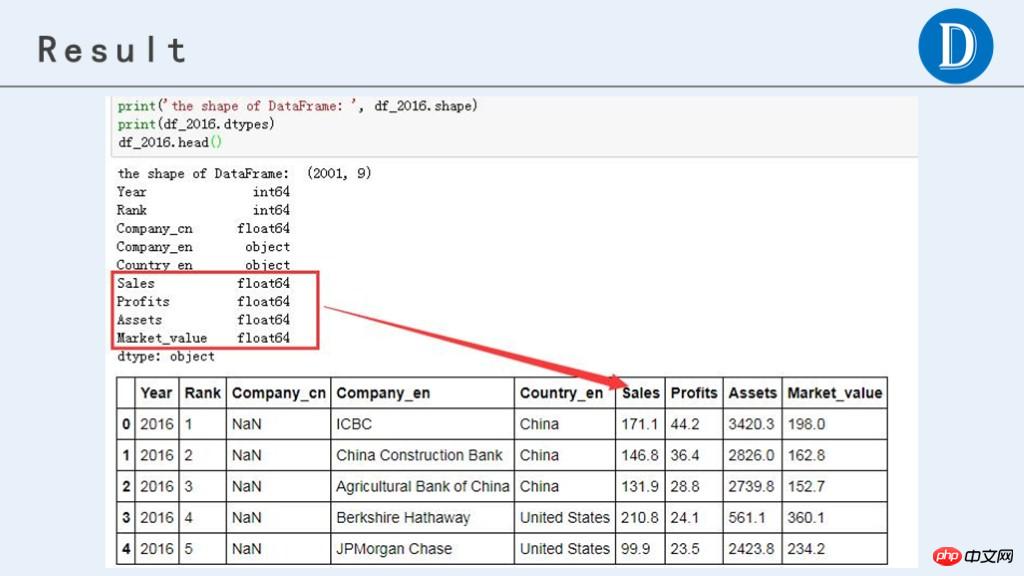
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()当然,如果DataFrame的列数特别多,可以用for循环,这样代码更简洁。代码如下:
cols = ['Sales', 'Profits', 'Assets', 'Market_value']for col in cols:
pro_col(df_2016, col)
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()最终处理后,获得的数据结果如下:
以上がPandas データ処理例の表示: 世界的な上場企業のデータ収集の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7500
7500
 15
1377
52
78
11
19
54
15
1377
52
78
11
19
54

 一般的なパンダのインストール問題の解決: インストール エラーの解釈と解決策
Feb 19, 2024 am 09:19 AM
一般的なパンダのインストール問題の解決: インストール エラーの解釈と解決策
Feb 19, 2024 am 09:19 AM
Pandas インストール チュートリアル: 一般的なインストール エラーとその解決策の分析、特定のコード サンプルが必要です はじめに: Pandas は、データ クリーニング、データ処理、およびデータ視覚化で広く使用されている強力なデータ分析ツールであるため、この分野で高く評価されていますデータサイエンスのただし、環境構成と依存関係の問題により、パンダのインストール時に問題やエラーが発生する可能性があります。この記事では、パンダのインストール チュートリアルを提供し、いくつかの一般的なインストール エラーとその解決策を分析します。 1.パンダをインストールする
 pandasを使用してtxtファイルを正しく読み取る方法
Jan 19, 2024 am 08:39 AM
pandasを使用してtxtファイルを正しく読み取る方法
Jan 19, 2024 am 08:39 AM
pandas を使用して txt ファイルを正しく読み取る方法には、特定のコード サンプルが必要です。パンダは、広く使用されている Python データ分析ライブラリです。CSV ファイル、Excel ファイル、SQL データベースなど、さまざまな種類のデータの処理に使用できます。同時に、txt ファイルなどのテキスト ファイルを読み取るために使用することもできます。ただし、txt ファイルを読み取るときに、エンコードの問題や区切り文字の問題など、いくつかの問題が発生することがあります。この記事ではパンダを使ってtxtを正しく読む方法を紹介します。
 pandas を使用して txt ファイルを読み取るための実践的なヒント
Jan 19, 2024 am 09:49 AM
pandas を使用して txt ファイルを読み取るための実践的なヒント
Jan 19, 2024 am 09:49 AM
pandas を使用して txt ファイルを読み取るための実践的なヒント、具体的なコード例が必要です データ分析とデータ処理では、txt ファイルは一般的なデータ形式です。 pandas を使用して txt ファイルを読み取ると、高速で便利なデータ処理が可能になります。この記事では、パンダをより効果的に使用して txt ファイルを読み取るのに役立ついくつかの実践的なテクニックを、具体的なコード例とともに紹介します。区切り文字付きの txt ファイルの読み取りパンダを使用して区切り文字付きの txt ファイルを読み取る場合は、read_c を使用できます。
 Pandas の効率的なデータ重複排除方法を明らかに: 重複データをすばやく削除するためのヒント
Jan 24, 2024 am 08:12 AM
Pandas の効率的なデータ重複排除方法を明らかに: 重複データをすばやく削除するためのヒント
Jan 24, 2024 am 08:12 AM
Pandas 重複排除メソッドの秘密: データを重複排除するための高速かつ効率的な方法 (特定のコード例が必要) データの分析と処理のプロセスでは、データの重複が頻繁に発生します。データが重複すると分析結果が誤解される可能性があるため、重複排除は非常に重要な手順です。強力なデータ処理ライブラリである Pandas では、データ重複排除を実現するためのさまざまな方法が提供されています。この記事では、一般的に使用されるいくつかの重複排除方法を紹介し、具体的なコード例を添付します。単一列に基づく重複排除の最も一般的なケースは、特定の列の値が重複しているかどうかに基づいています。
 シンプルなパンダのインストール チュートリアル: さまざまなオペレーティング システムにパンダをインストールする方法に関する詳細なガイダンス
Feb 21, 2024 pm 06:00 PM
シンプルなパンダのインストール チュートリアル: さまざまなオペレーティング システムにパンダをインストールする方法に関する詳細なガイダンス
Feb 21, 2024 pm 06:00 PM
シンプルなパンダのインストール チュートリアル: さまざまなオペレーティング システムにパンダをインストールする方法に関する詳細なガイダンス、特定のコード サンプルが必要です. データ処理と分析の需要が高まり続けるにつれて、パンダは多くのデータ サイエンティストやアナリストにとって推奨されるツールの 1 つになりました。 pandas は、大量の構造化データを簡単に処理および分析できる強力なデータ処理および分析ライブラリです。この記事では、さまざまなオペレーティング システムにパンダをインストールする方法を詳しく説明し、具体的なコード例を示します。 Windows オペレーティング システムにインストールする
 Golang はどのようにデータ処理効率を向上させますか?
May 08, 2024 pm 06:03 PM
Golang はどのようにデータ処理効率を向上させますか?
May 08, 2024 pm 06:03 PM
Golang は、同時実行性、効率的なメモリ管理、ネイティブ データ構造、豊富なサードパーティ ライブラリを通じてデータ処理効率を向上させます。具体的な利点は次のとおりです。 並列処理: コルーチンは複数のタスクの同時実行をサポートします。効率的なメモリ管理: ガベージ コレクション メカニズムによりメモリが自動的に管理されます。効率的なデータ構造: スライス、マップ、チャネルなどのデータ構造は、データに迅速にアクセスして処理します。サードパーティ ライブラリ: fasthttp や x/text などのさまざまなデータ処理ライブラリをカバーします。
 Redis を使用して Laravel アプリケーションのデータ処理効率を向上させる
Mar 06, 2024 pm 03:45 PM
Redis を使用して Laravel アプリケーションのデータ処理効率を向上させる
Mar 06, 2024 pm 03:45 PM
Redis を使用して Laravel アプリケーションのデータ処理効率を向上させる インターネット アプリケーションの継続的な開発に伴い、データ処理効率が開発者の焦点の 1 つになっています。 Laravel フレームワークに基づいてアプリケーションを開発する場合、Redis を使用してデータ処理効率を向上させ、データの高速アクセスとキャッシュを実現できます。この記事では、Laravel アプリケーションでのデータ処理に Redis を使用する方法を紹介し、具体的なコード例を示します。 1. Redis の概要 Redis は高性能なメモリ データです
 txt ファイルを読み取るパンダに関する FAQ
Jan 19, 2024 am 09:19 AM
txt ファイルを読み取るパンダに関する FAQ
Jan 19, 2024 am 09:19 AM
Pandas は Python 用のデータ分析ツールであり、データのクリーニング、処理、分析に特に適しています。データ分析プロセスでは、Txt ファイルなどのさまざまな形式のデータ ファイルを読み取る必要があることがよくあります。ただし、特定の操作中にいくつかの問題が発生する場合があります。この記事では、pandas での txt ファイルの読み取りに関するよくある質問への回答と、対応するコード例を紹介します。質問 1: txt ファイルを読み取るにはどうすればよいですか? txt ファイルは、pandas の read_csv() 関数を使用して読み取ることができます。それの訳は
