
1. ASII
アメリカ (国家) 情報交換標準 (コード) コード。
コンピュータには数字しかなく、すべてが数字で表され、画面に表示される文字も例外ではありません。
1バイトで表現できる数値は0~255で、例えばaは97、bは98とキーボード上のすべての文字を表示するのに十分です。この数字と文字に対応するエンコード規則は Asc11 コードと呼ばれ、ASC11 コードの最上位ビットはすべて 0、つまり ASC11 コードの値は 0 ~ 127 になります。
2. GB2312 および GBK (中国のローカル文字セット)
中国本土では各漢字を表すのに 2 バイトを使用し、漢字のバイトの最上位ビットは 1 です。この符号化形式は (gb2312) 国家標準コードと呼ばれ、gb2312 コードに対応する数値は負の数になります。
gb2312 に基づいて、GBK と呼ばれる繁体字中国語文字など、さらにいくつかの文字が追加されています
添付ファイル:
GB18030 エンコードは、より多くの中国語文字があり、2 桁のみを使用しているため、GBK エンコードに基づく拡張です。エンコーディングでは必要な中国語の文字に対応できなくなったため、より多くの中国語の文字エンコーディングをサポートするために 24 ビット混合方式が採用されています。
3. ANSI
各国語を表示するための ASCII エンコードを拡張するために、さまざまな国や地域で異なる標準が策定され、その結果、GB2312、BIG5、JIS などのそれぞれのエンコード標準が作成されました。文字を表すために 2 バイトを使用するこれらのさまざまな中国語の拡張エンコード方式は、ANSI エンコードと呼ばれ、「MBCS (Multi-Bytes Charecter Set、マルチバイト文字セット)」とも呼ばれます。簡体字中国語システムでは、ANSI エンコードは GB2312 エンコードを表します。日本語オペレーティング システムでは、ANSI エンコードは JIS エンコードを表します。したがって、中国語 Windows で gb2312 にトランスコードするには、gbk はテキストを ANSI エンコードとして保存するだけで済みます。 異なる ANSI エンコーディングは相互に互換性がありません。
4. ローカル文字セット
中国本土で使用されるコンピュータ システムでは、GBK および GB2312 がシステムのローカル文字セットと呼ばれます。
中国語の「中国」の文字は、中国本土のエンコードは16進数のD6D0、台湾ではA4A4です。台湾のエンコードはBIG5ビッグファイブコードと呼ばれます。ある国のローカリゼーション システムに表示されている文字が電子メールを介して別の国のローカリゼーション システムに送信されると、表示されるのは元の文字ではなく、別の国の文字または文字化けです。
5. Unicode エンコーディング
ISO 組織は世界中でシンボルを統一しており、それを Unicode エンコーディングと呼んでいます。
記号「中」は世界中で16進数の4e2dです。 すべてのコンピューターが Unicode エンコードを使用している場合、「中」という単語は世界中のコンピューターで「中」として表示されます。Unicode でエンコードされた文字は 2 バイトを占め、AC11 コードで表される文字の場合は、すべてのビットのバイトが追加されるだけです。 AS11 コードによって元々占有されていたバイトの前の 0 に等しい。表現される文字数は 65535 を超えない。実際には、エンコードには使用されない。
Unicode はまだ統一された世界を形成していません。長い間、ローカライズされた文字エンコーディングは Unicode エンコーディングと共存します。
Java の文字はすべて Unicode エンコーディングを使用します。
Java は、Unicode を通じてクロスプラットフォーム機能を保証することを前提として、ローカル プラットフォームの文字セットもサポートします。
6. UTF-8
Java言語やその他のプログラムの開発プロセスでは、特にXMLにはUTF-8 UTF-16も含まれます。広い意味の Unicode には、UTF8 と utf-16 も含まれます
UTF-8
-- ASC11 コード文字はそのまま残り、1 バイトのみを占めます。
--他の国の文字の場合、UTF-8 は 2 バイトまたは 3 バイトを使用してそれらを表します。
-- UTF-8 でエンコードされたファイルを使用する場合は、通常、ファイルの先頭の 3 バイトのデータとして EF BB BF を使用します。
7. UTF-8 と Unicode エンコード間の変換規則
-- 0001-007f (1 バイト)
0xxxxxx
-- 0000 または 0080 から 07ff までの文字、
110xxxxx 10xxxxxx (11 有効ビット) s ) (0080-07ff の間) Unicode は 16 ビットですが、実際には有効なビットは 11 ビットのみで、残りはフラグです。
-- 0800 から ffff、1110xxxx 10xxxxxx 10xxxxxx (16 有効ビット) までの文字。ソフトウェアは、UTF-8 エンコードの固定ビット値に基づいて、文字が 1 バイトを占めるか、それとも 3 バイトを占めるかを簡単に判断できます。バイト。
8. UTF-8の利点
-- ox00は表示されません(C言語では、
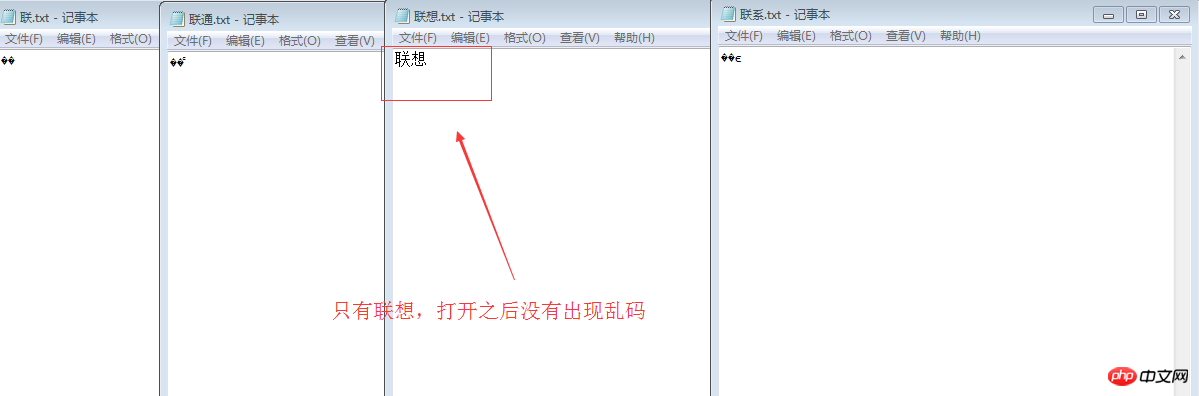
ue で開き、16 進数を確認してください。C1AA CDA8 C1AA CFE8 //これらはすべて GB2312 エンコーディングです。中程度の場合は D6D0、つまり C1AA が接続され、CDA8 が CFE8 に接続されます。バイナリ表現は次の方法で取得できます:
int x=0xCDA8; System.out.println(Integer.toBinaryString(x) );
//11000001 10101010 Lian 11001101 10101000 メモ帳のファイルはデフォルトで中国語の文字セット GB2312 に従って保存されるため、単語「Lian」は1100 0001 1010 1010 に解析され、文字は 1100 1101 1010 1000 として保存されました。メモ帳ドキュメントを開いたとき、これらのバイナリ形式はたまたま UTF-8 のルールに対応していたので、システムはこれを UTF-8 でエンコードされたファイルと見なしました。が UTF-8 として解釈されて文字化けが表示される 解決策は、保存時に UTF-8 を直接押して保存すると文字化けが表示されなくなります。
10. プログラムを使用して文字のエンコードを確認します中国語の文字の GB2312 コードを確認します
漢字の UTF-8 コードを確認します
漢字の Unicode コードを確認します
public static void main(String[] args) throws UnsupportedEncodingException {
String str="中国"; //查看字符的unicode码,将一个字符转成整数,得到的就是unicode值/* for(int i=0;i<str.length();i++){
int unicodeCode=str.charAt(i);
System.out.println(unicodeCode); // 20013,22269
System.out.println(Integer.toHexString(unicodeCode)); //对应的16进制 4e2d,56fd
}*///查看字符的gb2312码byte [] buff =str.getBytes("gb2312"); for(int i=0;i<buff.length;i++){
System.out.println(buff[i]); // -42,-48, -71,-6System.out.println(Integer.toHexString(buff[i])); //ffffffd6 ,ffffffd0 ffffffb9,fffffffa }
}以上がJava の基本入門のための文字エンコーディングの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



