

Beautifulsoup とセレンの使い方の簡単な紹介
Beautifulsoup と selenium の簡単な使い方
リクエストライブラリのレビュー
長い間 requests を使っていませんでした。後で簡単なクローラーを書くので、少しだけ書いておきますレビュー。 requests了,因为一会儿要写个简单的爬虫,所以还是随便写一点复习下。
import requests r = requests.get('https://api.github.com/user', auth=('haiyu19931121@163.com', 'Shy18137803170'))print(r.status_code) # 状态码200print(r.json()) # 返回json格式print(r.text) # 返回文本print(r.headers) # 头信息print(r.encoding) # 编码方式,一般utf-8# 当写入文件比较大时,避免内存耗尽,可以一次写指定的字节数或者一行。# 一次读一行,chunk_size=512为默认值for chunk in r.iter_lines():print(chunk)# 一次读取一块,大小为512for chunk in r.iter_content(chunk_size=512):print(chunk)
注意iter_lines和iter_content返回的都是字节数据,若要写入文件,不管是文本还是图片,都需要以wb的方式打开。
Beautifulsoup的使用
进入正题,早就听说这个著名的库,以前写爬虫用正则表达式虽然不麻烦,但有时候会匹配不准确。使用Beautifulsoup可以准确从HTML标签中提取数据。虽然是慢了点,但是简单好使呀。
from bs4 import BeautifulSoup html_doc = """<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>"""# 就注意一点,第二个参数指定解析器,必须填上,不然会有警告。推荐使用lxmlsoup = BeautifulSoup(html_doc, 'lxml')
紧接着上面的代码,看下面一些简单的操作。使用点属性的行为,会得到第一个查找到的符合条件的数据。是find方法的简写。
soup.a soup.find('p')
上面的两句是等价的。
# soup.body是一个Tag对象。是body标签中所有html代码print(soup.body)
<body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> </body>
# 获取body里所有文本,不含标签print(soup.body.text)# 等同于下面的写法soup.body.get_text()# 还可以这样写,strings是所有文本的生成器for string in soup.body.strings:print(string, end='')
The Dormouse's story Once upon a time there were three little sisters; and their names were Elsie, Lacie and Tillie; and they lived at the bottom of a well. ...
# 获得该标签里的文本。print(soup.title.string)
The Dormouse's story
# Tag对象的get方法可以根据属性的名称获得属性的值,此句表示得到第一个p标签里class属性的值print(soup.p.get('class'))# 和下面的写法等同print(soup.p['class'])
['title']
# 查看a标签的所有属性,以字典形式给出print(soup.a.attrs)
{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}# 标签的名称soup.title.name
title
find_all
使用最多的当属find_all / find方法了吧,前者查找所有符合条件的数据,返回一个列表。后者则是这个列表中的第一个数据。find_all有一个limit参数,限制列表的长度(即查找符合条件的数据的个数)。当limit=1其实就成了find方法 。
find_all同样有简写方法。
soup.find_all('a', id='link1') soup('a', id='link1')
上面两种写法是等价的,第二种写法便是简写。
find_all(self, name=None, attrs={}, recursive=True, text=None,
limit=None, **kwargs)name
name就是想要搜索的标签,比如下面就是找到所有的p标签。不仅能填入字符串,还能传入正则表达式、列表、函数、True。
传入True的话,就没有限制,什么都查找了。
recursive
调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False 。
# title不是html的直接子节点,但是会检索其下所有子孙节点soup.html.find_all("title")# [The Dormouse's story ]# 参数设置为False,只会找直接子节点soup.html.find_all("title", recursive=False)# []# title就是head的直接子节点,所以这个参数此时无影响a = soup.head.find_all("title", recursive=False)# [The Dormouse's story ]keyword和attrs
使用keyword,加上一个或者多个限定条件,缩小查找范围。
# 查看所有id为link1的p标签soup.find_all('a', id='link1')
如果按类查找,由于class关键字Python已经使用。可以用class_,或者不指定关键字,又或者使用attrs填入字典。
soup.find_all('p', class_='story')
soup.find_all('p', 'story')
soup.find_all('p', attrs={"class": "story"})上面三种方法等价。class_可以接受字符串、正则表达式、函数、True。
text
搜索文本值,好像使用string参数也是一样的结果。
a = soup.find_all(text='Elsie')# 或者,4.4以上版本请使用texta = soup.find_all(string='Elsie')
text参数也可以接受字符串、正则表达式、True、列表。
CSS选择器
还能使用CSS选择器呢。使用select方法就好了,select始终返回一个列表。
列举几个常用的操作。
# 所有div标签soup.select('div')# 所有id为username的元素soup.select('.username')# 所有class为story的元素soup.select('#story')# 所有div元素之内的span元素,中间可以有其他元素soup.select('div span')# 所有div元素之内的span元素,中间没有其他元素soup.select('div > span')# 所有具有一个id属性的input标签,id的值无所谓soup.select('input[id]')# 所有具有一个id属性且值为user的input标签soup.select('input[id="user"]')# 搜索多个,class为link1或者link2的元素都符合soup.select("#link1, #link2")一个爬虫小例子
上面介绍了requests和beautifulsoup4的基本用法,使用这些已经可以写一些简单的爬虫了。来试试吧。
此例子来自《Python编程快速上手——让繁琐的工作自动化》[美] AI Sweigart
这个爬虫会批量下载XKCD漫画网的图片,可以指定下载的页面数。
import osimport requestsfrom bs4 import BeautifulSoup# exist_ok=True,若文件夹已经存在也不会报错os.makedirs('xkcd')
url = 'https://xkcd.com/'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/57.0.2987.98 Safari/537.36'}def save_img(img_url, limit=1):
r = requests.get(img_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')try:
img = 'https:' + soup.find('div', id='comic').img.get('src')except AttributeError:print('Image Not Found')else:print('Downloading', img)
response = requests.get(img, headers=headers)with open(os.path.join('xkcd', os.path.basename(img)), 'wb') as f:for chunk in response.iter_content(chunk_size=1024*1024):
f.write(chunk)# 每次下载一张图片,就减1limit -= 1# 找到上一张图片的网址if limit > 0:try:
prev = 'https://xkcd.com' + soup.find('a', rel='prev').get('href')except AttributeError:print('Link Not Exist')else:
save_img(prev, limit)if __name__ == '__main__':
save_img(url, limit=20)print('Done!')Downloading Downloading Downloading Downloading Downloading Downloading Downloading Downloading Downloading ... Done!
多线程下载
单线程的速度有点慢,比如可以使用多线程,由于我们在获取prev的时候,知道了每个网页的网址是很有规律的。它像这样。只是最后的数字不一样,所以我们可以很方便地使用range
import osimport threadingimport requestsfrom bs4 import BeautifulSoup
os.makedirs('xkcd')
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/57.0.2987.98 Safari/537.36'}def download_imgs(start, end):for url_num in range(start, end):
img_url = 'https://xkcd.com/' + str(url_num)
r = requests.get(img_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')try:
img = 'https:' + soup.find('div', id='comic').img.get('src')except AttributeError:print('Image Not Found')else:print('Downloading', img)
response = requests.get(img, headers=headers)with open(os.path.join('xkcd', os.path.basename(img)), 'wb') as f:for chunk in response.iter_content(chunk_size=1024 * 1024):
f.write(chunk)if __name__ == '__main__':# 下载从1到30,每个线程下载10个threads = []for i in range(1, 30, 10):
thread_obj = threading.Thread(target=download_imgs, args=(i, i + 10))
threads.append(thread_obj)
thread_obj.start()# 阻塞,等待线程执行结束都会等待for thread in threads:
thread.join()# 所有线程下载完毕,才打印print('Done!')iter_lines と iter_content は、テキストであろうと画像であろうと、ファイルを書き込む場合は次のことを行う必要があることに注意してください。 < コードで開く>wb モードで開始します。 🎜🎜Beautifulsoup の使用🎜🎜 本題に移ります。この有名なライブラリについては以前から聞いていましたが、正規表現を使用してクローラを作成するのは面倒ではありませんでしたが、場合によってはマッチングが不正確になることがありました。 。 Beautifulsoup を使用して、HTML タグからデータを正確に抽出します。少し遅いですが、シンプルで使いやすいです。 🎜🎜from selenium import webdriverfrom selenium.webdriver.common.keys import Keysimport time browser = webdriver.Chrome()# Chrome打开百度首页browser.get('https://www.baidu.com/')# 找到输入区域input_area = browser.find_element_by_id('kw')# 区域内填写内容input_area.send_keys('The Zen of Python')# 找到"百度一下"search = browser.find_element_by_id('su')# 点击search.click()# 或者按下回车# input_area.send_keys('The Zen of Python', Keys.ENTER)time.sleep(3) browser.get('https://www.zhihu.com/') time.sleep(2)# 返回到百度搜索browser.back() time.sleep(2)# 退出浏览器browser.quit()
find メソッドの略称です。 🎜🎜browser.back() # 返回按钮browser.forward() # 前进按钮browser.refresh() # 刷新按钮browser.close() # 关闭当前窗口browser.quit() # 退出浏览器
browser = webdriver.Chrome() browser.get('https://passport.csdn.net/account/login') browser.find_element_by_id('username').send_keys('haiyu19931121@163.com') browser.find_element_by_id('password').send_keys('**********') browser.find_element_by_class_name('logging').click()
find_all
🎜 最もよく使われるメソッドは間違いなくfind_all / 検索</コード> メソッド さて、前者は条件を満たすすべてのデータを検索し、リストを返します。後者は、このリストの最初のデータです。 <strong><code>find_all には、リストの長さ (つまり、見つかった条件を満たすデータの数) を制限する limit パラメータがあります。 limit=1 の場合、実際には find メソッドになります。 🎜🎜find_all にも短縮メソッドがあります。 🎜🎜rrreee🎜🎜上記 2 つの書き方は同等で、2 番目の書き方は略語です。 🎜rrreeename
🎜name は、検索するタグです。たとえば、以下はすべての p タグを検索します。文字列を入力できるだけでなく、正規表現、リスト、関数、True を渡すこともできます。 🎜🎜rrreee🎜🎜 True を渡すと、制限はなくなり、すべてが検索されます。 🎜再帰的
🎜 タグのfind_all() メソッドを呼び出すと、現在のタグの直接の子ノードのみを検索する場合、Beautiful Soup はすべての子孫ノードを取得します。タグでは、パラメータ recursive=False を使用できます。 🎜🎜rrreee🎜キーワードと属性
🎜 キーワードを使用し、1 つ以上の条件を追加して検索範囲を絞り込みます。 🎜🎜rrreee🎜🎜クラスで検索すると、class キーワードがあるため、Python はすでにそれを使用しています。class_ を使用することも、キーワードを指定しないことも、attrs を使用して辞書に入力することもできます。 🎜🎜rrreee🎜🎜上記の 3 つの方法は同等です。 class_ は、文字列、正規表現、関数、および True を受け入れることができます。 🎜text
🎜テキスト値を検索します。文字列パラメータを使用しても同じ結果が得られるようです。 🎜🎜rrreee🎜🎜 text パラメーターは、文字列、正規表現、True、リストも受け入れることができます。 🎜CSS セレクター
🎜 CSS セレクターを使用することもできます。 select メソッドを使用するだけで、select は常にリストを返します。 🎜🎜一般的な操作をいくつか挙げます。 🎜🎜rrreee🎜🎜小さなクローラーの例🎜🎜リクエストと beautifulsoup4 の基本的な使い方は上で紹介されています。これらを使用すると、すでにいくつかの簡単なクローラーを作成できます。ぜひ試してみてください。 🎜🎜この例は、「Python プログラミングですぐに始めよう - 面倒な作業を自動化する」[米国] AI Sweigart からのものです🎜🎜このクローラーは、XKCD コミックス ネットワークから画像をバッチでダウンロードします。番号を指定できます。ダウンロードするページの数。 🎜🎜rrreee🎜rrreee🎜マルチスレッドダウンロード🎜🎜 シングルスレッドの速度は少し遅いですが、たとえば、
prev を取得すると URL がわかるため、マルチスレッドを使用できます。各ウェブページの内容は非常に規則的です。こんなふうになります。最後の数値のみが異なるため、range を使用して簡単にトラバースできます。 🎜🎜りー🎜来看下结果吧。
初步了解selenium
selenium用来作自动化测试。使用前需要下载驱动,我只下载了Firefox和Chrome的。网上随便一搜就能下载到了。接下来将下载下来的文件其复制到将安装目录下,比如Firefox,将对应的驱动程序放到C:\Program Files (x86)\Mozilla Firefox,并将这个路径添加到环境变量中,同理Chrome的驱动程序放到C:\Program Files (x86)\Google\Chrome\Application并将该路径添加到环境变量。最后重启IDE开始使用吧。
模拟百度搜索
下面这个例子会打开Chrome浏览器,访问百度首页,模拟输入The Zen of Python,随后点击百度一下,当然也可以用回车代替。Keys下是一些不能用字符串表示的键,比如方向键、Tab、Enter、Esc、F1~F12、Backspace等。然后等待3秒,页面跳转到知乎首页,接着返回到百度,最后退出(关闭)浏览器。
from selenium import webdriverfrom selenium.webdriver.common.keys import Keysimport time browser = webdriver.Chrome()# Chrome打开百度首页browser.get('https://www.baidu.com/')# 找到输入区域input_area = browser.find_element_by_id('kw')# 区域内填写内容input_area.send_keys('The Zen of Python')# 找到"百度一下"search = browser.find_element_by_id('su')# 点击search.click()# 或者按下回车# input_area.send_keys('The Zen of Python', Keys.ENTER)time.sleep(3) browser.get('https://www.zhihu.com/') time.sleep(2)# 返回到百度搜索browser.back() time.sleep(2)# 退出浏览器browser.quit()
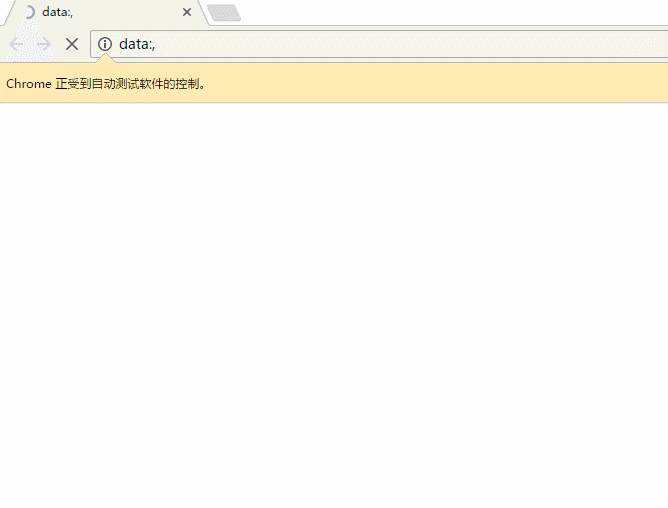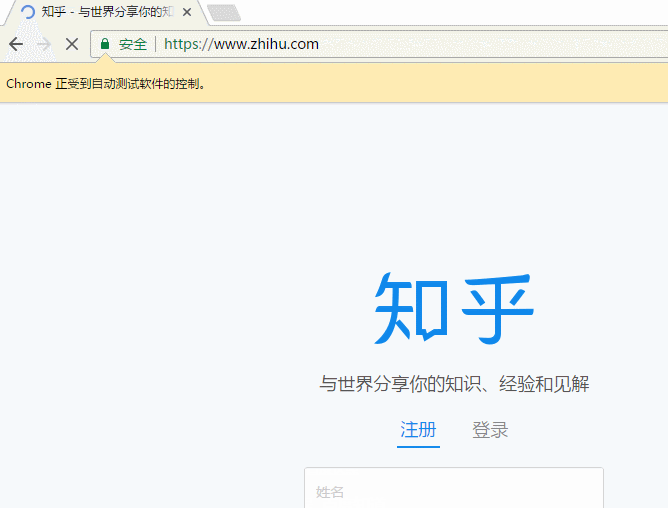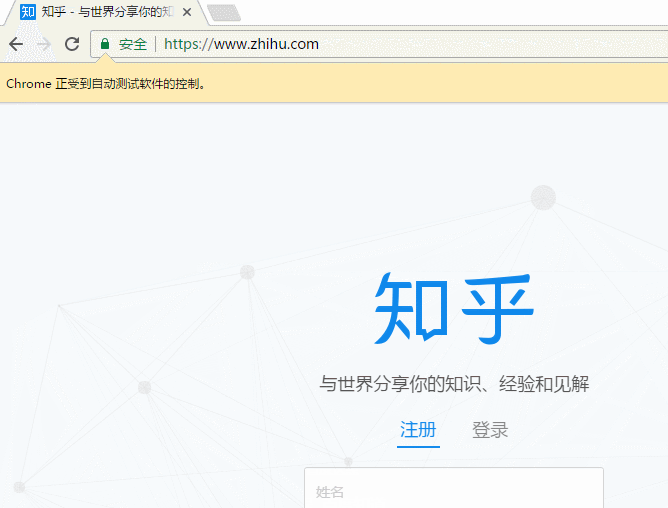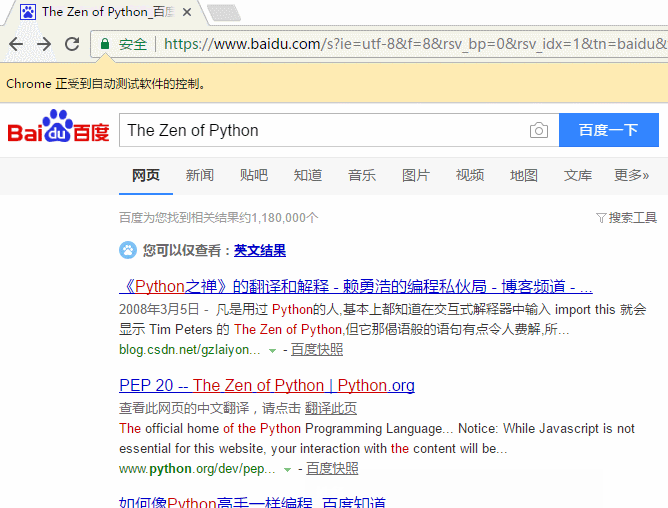
send_keys模拟输入内容。可以使用element的clear()方法清空输入。一些其他模拟点击浏览器按钮的方法如下
browser.back() # 返回按钮browser.forward() # 前进按钮browser.refresh() # 刷新按钮browser.close() # 关闭当前窗口browser.quit() # 退出浏览器
查找方法
以下列举常用的查找Element的方法。
| 方法名 | 返回的WebElement |
|---|---|
| find_element_by_id(id) | 匹配id属性值的元素 |
| find_element_by_name(name) | 匹配name属性值的元素 |
| find_element_by_class_name(name) | 匹配CSS的class值的元素 |
| find_element_by_tag_name(tag) | 匹配标签名的元素,如div |
| find_element_by_css_selector(selector) | 匹配CSS选择器 |
| find_element_by_xpath(xpath) | 匹配xpath |
| find_element_by_link_text(text) | 完全匹配提供的text的a标签 |
| find_element_by_partial_link_text(text) | 提供的text可以是a标签中文本中的一部分 |
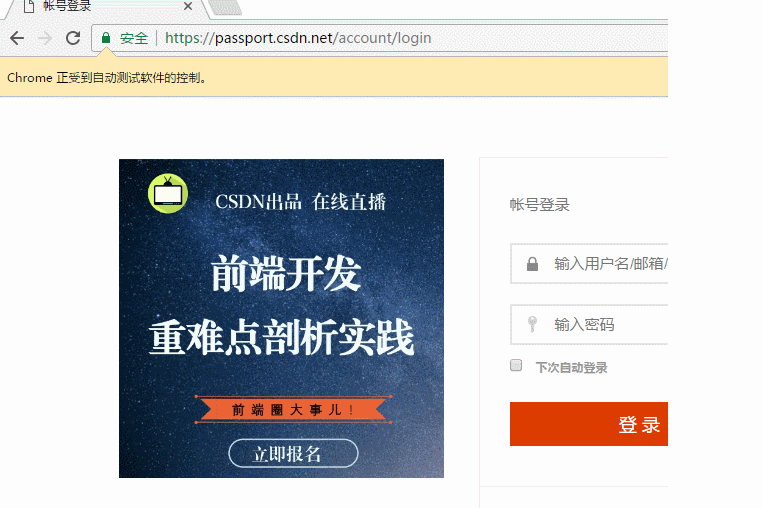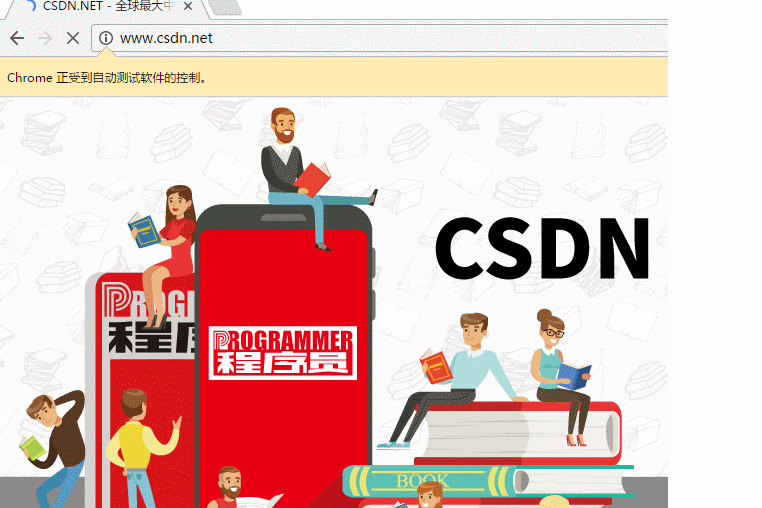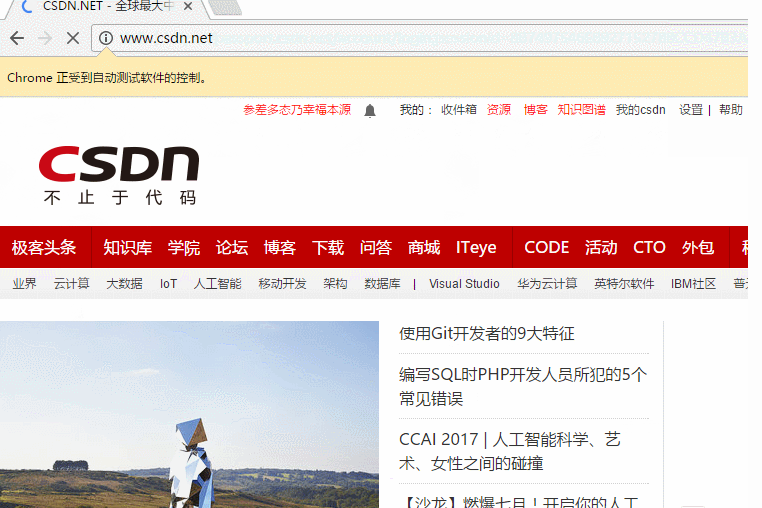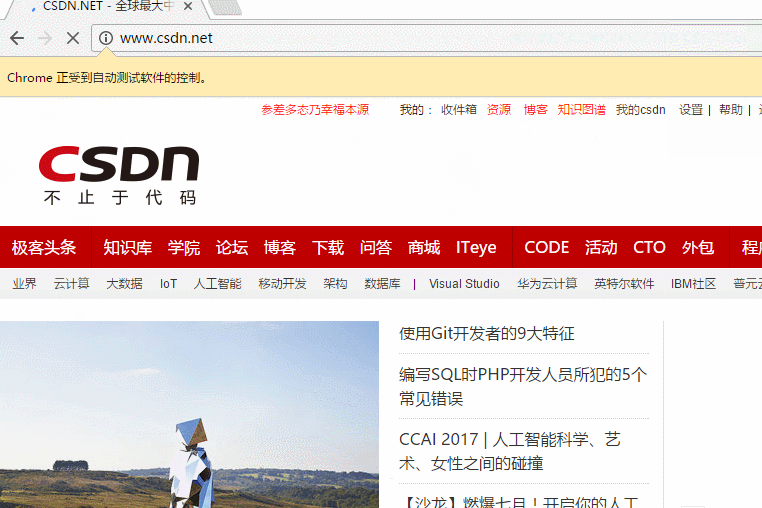
登录CSDN
以下代码可以模拟输入账号密码,点击登录。整个过程还是很快的。
browser = webdriver.Chrome() browser.get('https://passport.csdn.net/account/login') browser.find_element_by_id('username').send_keys('haiyu19931121@163.com') browser.find_element_by_id('password').send_keys('**********') browser.find_element_by_class_name('logging').click()
以上差不多都是API的罗列,其中有自己的理解,也有照搬官方文档的。
by @sunhaiyu
2017.7.13
以上がBeautifulsoup とセレンの使い方の簡単な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7463
7463
 15
1376
52
77
11
18
18
15
1376
52
77
11
18
18

 マグネットリンクの使い方
Feb 18, 2024 am 10:02 AM
マグネットリンクの使い方
Feb 18, 2024 am 10:02 AM
マグネット リンクは、リソースをダウンロードするためのリンク方法であり、従来のダウンロード方法よりも便利で効率的です。マグネット リンクを使用すると、中間サーバーに依存せずに、ピアツーピア方式でリソースをダウンロードできます。この記事ではマグネットリンクの使い方と注意点を紹介します。 1. マグネット リンクとは? マグネット リンクは、P2P (Peer-to-Peer) プロトコルに基づくダウンロード方式です。ユーザーはマグネット リンクを通じてリソースの発行者に直接接続し、リソースの共有とダウンロードを完了できます。従来のダウンロード方法と比較して、磁気
 mdfおよびmdsファイルの使用方法
Feb 19, 2024 pm 05:36 PM
mdfおよびmdsファイルの使用方法
Feb 19, 2024 pm 05:36 PM
mdf ファイルと mds ファイルの使用方法 コンピューター技術の継続的な進歩により、さまざまな方法でデータを保存および共有できるようになりました。デジタル メディアの分野では、特殊なファイル形式に遭遇することがよくあります。この記事では、一般的なファイル形式である mdf および mds ファイルについて説明し、その使用方法を紹介します。まず、mdf ファイルと mds ファイルの意味を理解する必要があります。 mdf は CD/DVD イメージ ファイルの拡張子で、mds ファイルは mdf ファイルのメタデータ ファイルです。
 CrystalDiskmarkとはどのようなソフトウェアですか? -crystaldiskmarkの使い方は?
Mar 18, 2024 pm 02:58 PM
CrystalDiskmarkとはどのようなソフトウェアですか? -crystaldiskmarkの使い方は?
Mar 18, 2024 pm 02:58 PM
CrystalDiskMark は、シーケンシャルおよびランダムの読み取り/書き込み速度を迅速に測定する、ハード ドライブ用の小型 HDD ベンチマーク ツールです。次に、編集者が CrystalDiskMark と Crystaldiskmark の使用方法を紹介します。 1. CrystalDiskMark の概要 CrystalDiskMark は、機械式ハード ドライブとソリッド ステート ドライブ (SSD) の読み取りおよび書き込み速度とパフォーマンスを評価するために広く使用されているディスク パフォーマンス テスト ツールです。 ). ランダム I/O パフォーマンス。これは無料の Windows アプリケーションで、使いやすいインターフェイスとハード ドライブのパフォーマンスのさまざまな側面を評価するためのさまざまなテスト モードを提供し、ハードウェアのレビューで広く使用されています。
 foobar2000のダウンロード方法は? -foobar2000の使い方
Mar 18, 2024 am 10:58 AM
foobar2000のダウンロード方法は? -foobar2000の使い方
Mar 18, 2024 am 10:58 AM
foobar2000 は、音楽リソースをいつでも聴くことができるソフトウェアです。あらゆる種類の音楽をロスレス音質で提供します。音楽プレーヤーの強化版により、より包括的で快適な音楽体験を得ることができます。その設計コンセプトは、高度なオーディオをコンピュータ上で再生可能 デバイスを携帯電話に移植し、より便利で効率的な音楽再生体験を提供 シンプルでわかりやすく、使いやすいインターフェースデザイン 過度な装飾や煩雑な操作を排除したミニマルなデザインスタイルを採用また、さまざまなスキンとテーマをサポートし、自分の好みに合わせて設定をカスタマイズし、複数のオーディオ形式の再生をサポートする専用の音楽プレーヤーを作成します。過度の音量による聴覚障害を避けるために、自分の聴覚の状態に合わせて調整してください。次は私がお手伝いさせてください
 Baidu Netdisk アプリの使用方法
Mar 27, 2024 pm 06:46 PM
Baidu Netdisk アプリの使用方法
Mar 27, 2024 pm 06:46 PM
クラウド ストレージは今日、私たちの日常生活や仕事に欠かせない部分になっています。中国有数のクラウド ストレージ サービスの 1 つである Baidu Netdisk は、強力なストレージ機能、効率的な伝送速度、便利な操作体験により多くのユーザーの支持を得ています。また、重要なファイルのバックアップ、情報の共有、オンラインでのビデオの視聴、または音楽の聴きたい場合でも、Baidu Cloud Disk はニーズを満たすことができます。しかし、Baidu Netdisk アプリの具体的な使用方法を理解していないユーザーも多いため、このチュートリアルでは Baidu Netdisk アプリの使用方法を詳しく紹介します。まだ混乱しているユーザーは、この記事に従って詳細を学ぶことができます。 Baidu Cloud Network Disk の使用方法: 1. インストール まず、Baidu Cloud ソフトウェアをダウンロードしてインストールするときに、カスタム インストール オプションを選択してください。
 NetEase メールボックス マスターの使用方法
Mar 27, 2024 pm 05:32 PM
NetEase メールボックス マスターの使用方法
Mar 27, 2024 pm 05:32 PM
NetEase Mailbox は、中国のネットユーザーに広く使用されている電子メール アドレスとして、その安定した効率的なサービスで常にユーザーの信頼を獲得してきました。 NetEase Mailbox Master は、携帯電話ユーザー向けに特別に作成された電子メール ソフトウェアで、電子メールの送受信プロセスが大幅に簡素化され、電子メールの処理がより便利になります。 NetEase Mailbox Master の使い方と具体的な機能について、以下ではこのサイトの編集者が詳しく紹介しますので、お役に立てれば幸いです。まず、モバイル アプリ ストアで NetEase Mailbox Master アプリを検索してダウンロードします。 App Store または Baidu Mobile Assistant で「NetEase Mailbox Master」を検索し、画面の指示に従ってインストールします。ダウンロードとインストールが完了したら、NetEase の電子メール アカウントを開いてログインします。ログイン インターフェイスは次のとおりです。
 BTCC チュートリアル: BTCC 取引所で MetaMask ウォレットをバインドして使用する方法は?
Apr 26, 2024 am 09:40 AM
BTCC チュートリアル: BTCC 取引所で MetaMask ウォレットをバインドして使用する方法は?
Apr 26, 2024 am 09:40 AM
MetaMask (中国語ではリトル フォックス ウォレットとも呼ばれます) は、無料で評判の高い暗号化ウォレット ソフトウェアです。現在、BTCC は MetaMask ウォレットへのバインドをサポートしており、バインド後は MetaMask ウォレットを使用してすぐにログイン、値の保存、コインの購入などが可能になり、初回バインドで 20 USDT のトライアル ボーナスも獲得できます。 BTCCMetaMask ウォレットのチュートリアルでは、MetaMask の登録方法と使用方法、および BTCC で Little Fox ウォレットをバインドして使用する方法を詳しく紹介します。メタマスクウォレットとは何ですか? 3,000 万人を超えるユーザーを抱える MetaMask Little Fox ウォレットは、現在最も人気のある暗号通貨ウォレットの 1 つです。無料で使用でき、拡張機能としてネットワーク上にインストールできます。
 Xiaoai スピーカーの使用方法 Xiaoai スピーカーを携帯電話に接続する方法
Feb 22, 2024 pm 05:19 PM
Xiaoai スピーカーの使用方法 Xiaoai スピーカーを携帯電話に接続する方法
Feb 22, 2024 pm 05:19 PM
スピーカーの再生ボタンを長押し後、ソフトウェア内でWi-Fiに接続すると使用可能になります。チュートリアル 該当するモデル: Xiaomi 12 システム: EMUI11.0 バージョン: Xiaoai Classmate 2.4.21 分析 1 まずスピーカーの再生ボタンを見つけ、長押ししてネットワーク配信モードに入ります。 2 携帯電話の Xiaoai Speaker ソフトウェアで Xiaomi アカウントにログインし、クリックして新しい Xiaoai Speaker を追加します。 3. Wi-Fi の名前とパスワードを入力した後、Xiao Ai に電話して使用することができます。補足: Xiaoai Speakerにはどのような機能がありますか? 1 Xiaoai Speakerには、システム機能、ソーシャル機能、エンターテイメント機能、ナレッジ機能、ライフ機能、スマートホーム、トレーニングプランがあります。概要/注意事項: 簡単に接続して使用するには、Xiao Ai アプリを事前に携帯電話にインストールしておく必要があります。
