

PHP (この記事で言及されている場合の PHP バージョンはすべて 7.1.3) は、zend 仮想マシンでの実行プロセスです: スクリプト プログラム文字列を読み取り、それを変換します。字句アナライザーは単語シンボルであり、次に構文アナライザーが構文構造を検出して抽象構文ツリーを生成し、次に静的コンパイラーがオペコードを生成し、最後にインタープリターが各オペコードを実行するための機械語命令をシミュレートします。
上記のプロセス全体では、デッドコードの削除、条件付き定数の伝播、関数のインライン化などのさまざまな最適化手法を適用することで、生成されたオペコードを合理化し、コードの実行パフォーマンスを向上させることができます。
PHP 拡張機能 opcache は、共有メモリに基づいて生成されたオペコードのキャッシュの最適化をサポートします。これに基づいて、オペコードの静的コンパイルの最適化が追加されます。ここで説明する最適化は通常、オプティマイザー (Optimizer) によって管理されます。コンパイル原理では、各最適化は一般に最適化パス (Opt pass) によって記述されます。
一般に、2 種類の最適化パスがあります:
1 つは、変換パスに補助情報を提供するデータ フローおよび制御フローの分析情報を提供する分析パスです。
1 つは変換パスです。生成されたコードの変更には、命令の追加と削除、命令の変更と置換、命令の順序の調整などが含まれます。通常、生成されたコードの変更は、各パスの前後でダンプできます。
この記事は、opcache 拡張機能によって提供されるオプティマイザーと組み合わせたコンパイル原則に基づいており、PHP コンパイルの基本単位である op_array と、PHP 実行オペコードの最小単位を開始点として使用します。この記事では、Zend 仮想マシンにおけるコンパイル最適化テクノロジのアプリケーションを紹介し、各最適化パスがオペコードを段階的に最適化してコードの実行パフォーマンスを向上させる方法を整理します。最後に、PHP 言語仮想マシンの実行に基づいていくつかの見通しを示します。
静的コンパイル (静的コンパイル)、事前コンパイル (事前コンパイル) とも呼ばれます。 AOTと呼ばれます。つまり、ソース コードはターゲット コードにコンパイルされ、実行されると、ターゲット コードをサポートするプラットフォーム上で実行されます。
動的コンパイル (動的コンパイル) は、静的コンパイルに対して、「実行時のコンパイル」を指します。通常、コンパイルと実行にはインタプリタが使用されます。これは、ソース言語を 1 つずつ解釈して実行することを指します。
JITコンパイル(ジャストインタイムコンパイル)、つまり狭義のジャストインタイムコンパイルとは、あるコードが初めて実行されるときにコンパイルされ、その後実行されることを意味します。コンパイルせずに直接実行されます。これは動的コンパイルの特殊なケースです。
上記 3 種類の異なるコンパイル実行プロセスは、大まかに次のように説明できます: 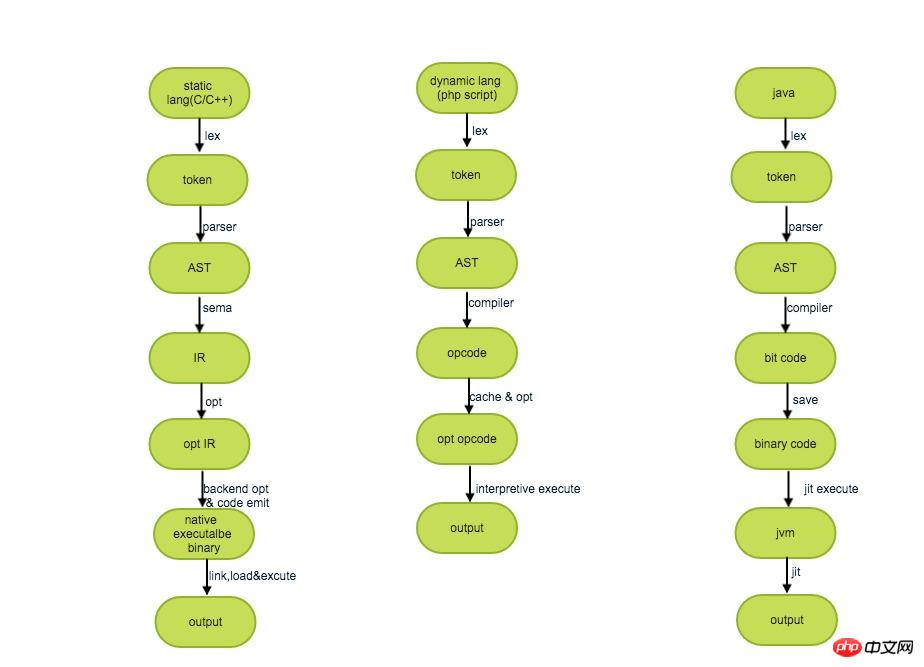
コンパイルの最適化では、プログラムから十分な情報を取得する必要があり、これはすべてのコンパイル最適化の基礎です。
コンパイラーのフロントエンドによって生成される結果は、構文ツリーまたはある種の低レベルの中間コードである可能性があります。しかし、結果がどのような形式であっても、プログラムが何を行うのか、どのように実行するのかについてはまだ多くがわかりません。コンパイラは、各プロシージャ内の制御フロー階層を検出するタスクを制御フロー分析に任せ、データ処理に関連するグローバル情報を決定するタスクをデータ フロー分析に任せます。
コントロールフローは、プログラムの制御構造情報を取得するための形式的な分析手法であり、データフロー分析と依存関係分析の基礎となります。制御の基本モデルは、コントロール フロー グラフ (CFG) です。単一プロセスの制御フローを分析するには、必要なノードを使用してループを見つける方法とインターバル分析の 2 つの方法があります。
データ フローは、プログラム コードからプログラムの意味情報を収集し、代数的手法を通じてコンパイル時に変数の定義と使用を決定します。データの基本モデルはデータ フロー グラフ (DFG) です。一般的なデータフロー分析はコントロールツリーベースのデータフロー分析であり、アルゴリズムは区間分析と構造分析に分かれます。
は、C 言語のスタック フレームの概念に似ています。スタック フレームは、実行中のプログラムの基本単位 (1 フレーム) であり、一般に関数呼び出しの基本単位です。ここでは、関数またはメソッド、PHP スクリプト ファイル全体、および PHP コードを表すために eval に渡される文字列が op_array にコンパイルされます。
実装では、op_array はプログラム実行の基本単位のすべての情報を含む構造体です。もちろん、opcode 配列は構造体の最も重要なフィールドですが、さらに、変数の型、注釈情報、例外キャプチャ情報、およびジャンプ待ち情報。
インタープリタ実行 (ZendVM) プロセスは、基本ユニット op_array で最小限の最適化されたオペコードを実行し、実行を順番にたどって、現在のオペコードを実行し、最後の RETRUN まで次のオペコードをプリフェッチします。これは特殊なオペコードであり、戻って終了します。
ここでのオペコードは、静的コンパイラの中間表現 (LLVM IR に類似) にもある程度似ています。通常、演算子、2 つのオペランド、および演算結果を含む 3 つのアドレス コードの形式もとります。 。両方のオペランドには型情報が含まれます。ここには、次の 5 種類の型情報があります。
コンパイル時変数 (略して CV) は、php スクリプトで定義される変数です。
ZendVM によって使用される一時変数である内部再利用可能変数 (VAR) は、他のオペコードと共有できます。
再利用不可能な内部変数 (TMP_VAR) (ZendVM によって使用される一時変数) は、他のオペコードと共有できません。
定数(CONST)、読み取り専用定数、値は変更できません。
役に立たない変数 (未使用)。オペコードは 3 つのアドレス コードを使用するため、すべてのオペコードにオペランド フィールドがあるわけではありません。デフォルトでは、この変数はフィールドを完成させるために使用されます。
型情報と演算子を使用すると、実行プログラムは特定のコンパイル済み C 関数ライブラリ テンプレートを照合して選択し、実行用の機械語命令をシミュレートして生成できます。
opcode は、ZendVM の zend_op 構造によって表されます。その主な構造は次のとおりです。 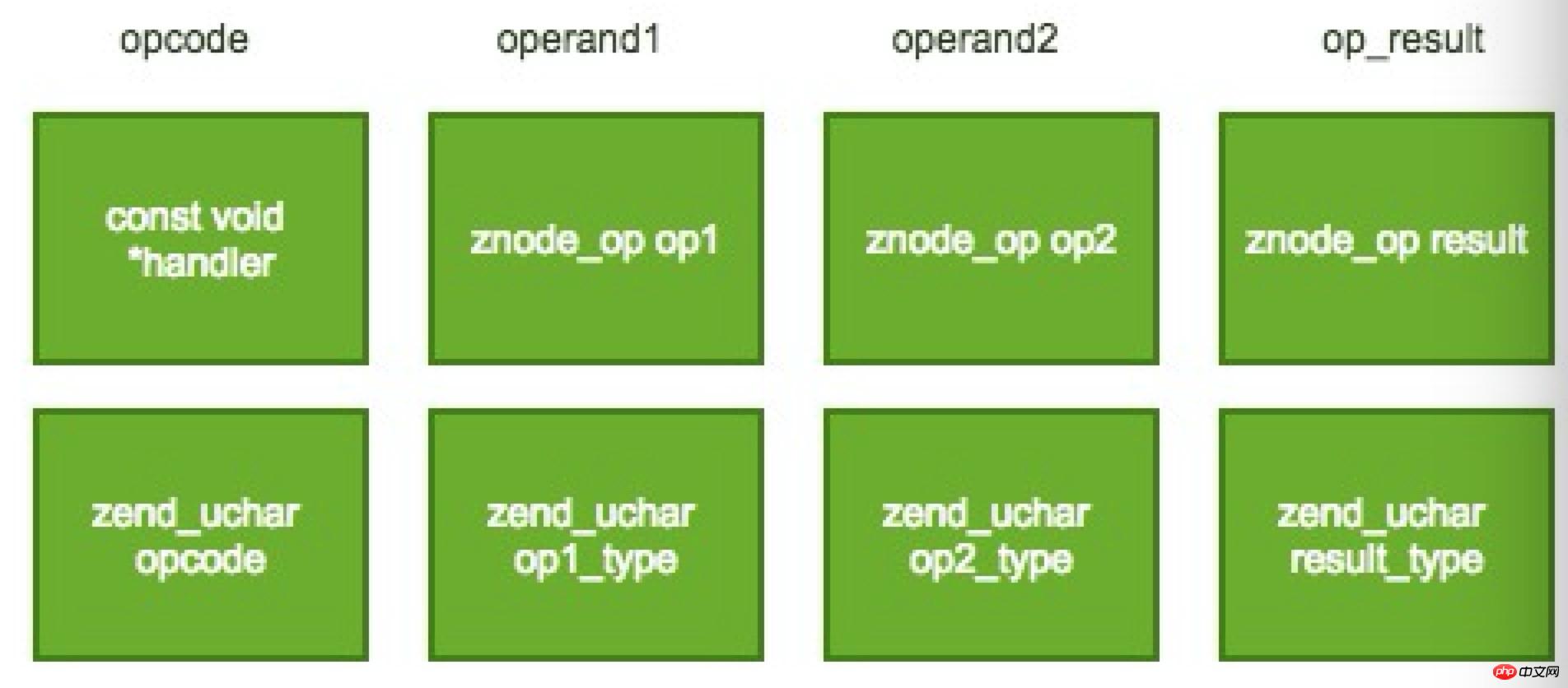
PHP スクリプトが字句解析と構文解析を通じて抽象構文ツリー構造を生成した後、次のようになります。静的にコンパイルおよび生成されたオペコード。さまざまな仮想マシンに命令を実行するための共通プラットフォームとして、さまざまな仮想マシンの特定の実装に依存します (ただし、PHP の場合、ほとんどは ZendVM を指します)。
オペコードが最適化されていれば、仮想マシンがオペコードを実行する前に、より実行効率の高いコードを取得できます。パスの機能は、オペコードを最適化し、オペコードを処理し、最適化を探すことです。実行効率の高いコードを生成するためにオペコードを変更します。
Zend 仮想マシン (ZendVM) では、opcache の静的コード オプティマイザーは zend オペコード最適化です。
最適化の効果を観察し、デバッグを容易にするために、最適化とデバッグのオプションも提供します:
optimizationlevel (opcache.optimizationlevel=0xFFFFFFFF) 最適化レベル ユーザーはデフォルトでオンになります。コマンド ライン パラメータを入力してシャットダウンを制御することもできます
optdebuglevel (opcache.optdebuglevel=-1) デバッグ レベルはデフォルトではオンになっていませんが、実行前にオペコード変換プロセスを提供します静的最適化に必要なスクリプト コンテキスト情報は、次のように構造体 zend_script にカプセル化されます:
typedef struct _zend_script {
zend_string *filename; //文件名
zend_op_array main_op_array; //栈帧
HashTable function_table; //函数单位符号表信息
HashTable class_table; //类单位符号表信息
} zend_script;zend
optimizerzend
optimizezend
optimizerオペコードのキャッシュについては、オペコードの非常に重要な最適化でもあります。その基本的なアプリケーション原理はおおよそ次のとおりです:
実行を除く最初の 3 つのステップは、基本的にフロントエンド コンパイラーの完全なプロセスですが、このコンパイル プロセスは高速ではありません。同じスクリプトが繰り返し実行される場合、最初の 3 つのステップのコンパイル時間により操作効率が大幅に制限されますが、各コンパイルで生成されるオペコードは変わりません。したがって、opcache 拡張機能は、初めてコンパイルするときにオペコードを特定の場所にキャッシュできます (Java は、次回同じときにオペコードを共有メモリから直接取得します)。スクリプトが実行されるため、コンパイル時間が節約されます。
opcache 拡張機能のオペコード キャッシュ プロセスは、おおよそ次のとおりです:
この記事は主に静的最適化パスに焦点を当てているため、キャッシュ最適化の具体的な実装についてはここでは説明しません。
2) ZendVM オプティマイザーの原則 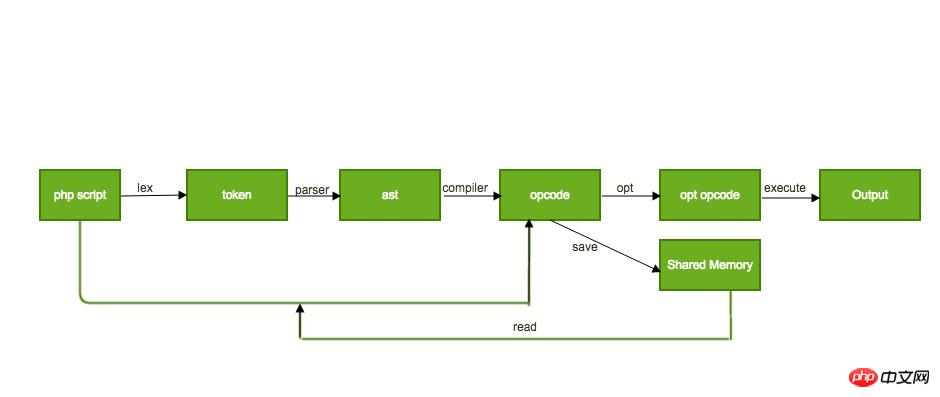 「Whale Book」(「Advanced Compiler Design and Implementation」) によると、最適化コンパイラーのより合理的な最適化パス シーケンスは次のとおりです:
「Whale Book」(「Advanced Compiler Design and Implementation」) によると、最適化コンパイラーのより合理的な最適化パス シーケンスは次のとおりです:
もちろん、現在のオペコードオプティマイザーは上記の最適化パスをすべて実装しているわけではなく、レジスタ割り当てなどのマシン関連の低レベル中間表現の最適化を実装する必要はありません。 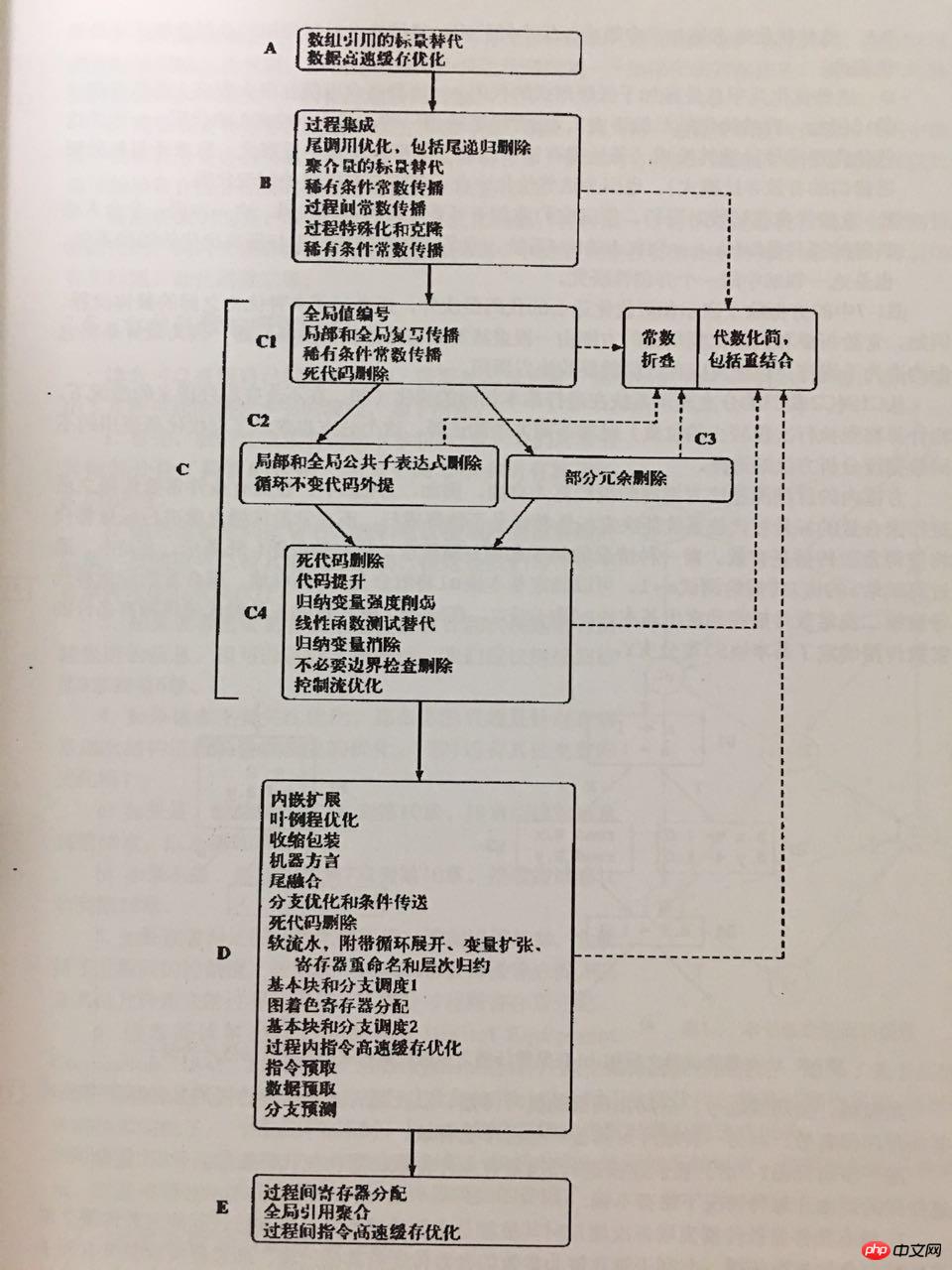
上記のスクリプト パラメーター情報を受信した後、opcache オプティマイザーは最小コンパイル単位を見つけます。これに基づき、最適化パスマクロとそれに対応する最適化レベルマクロにより、あるパスの登録制御を実現することができる。
登録された最適化では、定数最適化、冗長nop削除、関数呼び出し最適化変換パス、データフロー解析、制御フロー解析、呼び出し関係解析などの解析パスを含む最適化が一定の順序で直列に編成されています。
zend
optimizeスクリプトと実際の最適化登録zend_optimizeプロセスは次のとおりです:
zend_optimize_script(zend_script *script,
zend_long optimization_level, zend_long debug_level)
|zend_optimize_op_array(&script->main_op_array, &ctx);
遍历二元操作符的常量操作数,由运行时转化为编译时(反向pass2)
实际优化pass,zend_optimize
遍历二元操作符的常量操作数,由编译时转化为运行时(pass2)
|遍历op_array内函数zend_optimize_op_array(op_array, &ctx);
|遍历类内非用户函数zend_optimize_op_array(op_array, &ctx);
(用户函数设static_variables)
|若使用DFA pass & 调用图pass & 构建调用图成功
遍历二元操作符的常量操作数,由运行时转化为编译时(反向pass2)
设置函数返回值信息,供SSA数据流分析使用
遍历调用图的op_array,做DFA分析zend_dfa_analyze_op_array
遍历调用图的op_array,做DFA优化zend_dfa_optimize_op_array
若开调试,遍历dump调用图的每一个op_array(优化变换后)
若开栈矫正优化,矫正栈大小adjust_fcall_stack_size_graph
再次遍历调用图内的的所有op_array,
针对DFA pass变换后新产生的常量场景,常量优化pass2再跑一遍
调用图op_array资源清理
|若开栈矫正优化
矫正栈大小main_op_array
遍历矫正栈大小op_array
|清理资源该部分主要调用了SSA/DFA/CFG这几类用于opcode分析pass,涉及的pass有BB块、CFG、DFA(CFG、DOMINATORS、LIVENESS、PHI-NODE、SSA)。
用于opcode转换的pass则集中在函数zend_optimize内,如下:
zend_optimize |op_array类型为ZEND_EVAL_CODE,不做优化 |开debug, 可dump优化前内容 |优化pass1, 常量替换、编译时常量操作变换、简单操作转换 |优化pass2 常量操作转换、条件跳转指令优化 |优化pass3 跳转指令优化、自增转换 |优化pass4 函数调用优化(主要为函数调用优化) |优化pass5 控制流图(CFG)优化 |构建流图 |计算数据依赖 |划分BB块(basic block,简称BB,数据流分析基本单位) |BB块内基于数据流分析优化 |BB块间跳转优化 |不可到达BB块删除 |BB块合并 |BB块外变量检查 |重新构建优化后的op_array(基于CFG) |析构CFG |优化pass6/7 数据流分析优化 |数据流分析(基于静态单赋值SSA) |构建SSA |构建CFG 需要找到对应BB块序号、管理BB块数组、计算BB块后继BB、标记可到达BB块、计算BB块前驱BB |计算Dominator树 |标识循环是否可简化(主要依赖于循环回边) |基于phi节点构建完SSA def集、phi节点位置、SSA构造重命名 |计算use-def链 |寻找不当依赖、后继、类型及值范围值推断 |数据流优化 基于SSA信息,一系列BB块内opcode优化 |析构SSA |优化pass9 临时变量优化 |优化pass10 冗余nop指令删除 |优化pass11 压缩常量表优化
还有其他一些优化遍如下:
优化pass12 矫正栈大小 优化pass15 收集常量信息 优化pass16 函数调用优化,主要是函数内联优化
除此之外,pass 8/13/14可能为预留pass id。由此可看出当前提供给用户选项控制的opcode转换pass有13个。但是这并不计入其依赖的数据流/控制流的分析pass。
通常在函数调用过程中,由于需要进行不同栈帧间切换,因此会有开辟栈空间、保存返回地址、跳转、返回到调用函数、返回值、回收栈空间等一系列函数调用开销。因此对于函数体适当大小情况下,把整个函数体嵌入到调用者(Caller)内部,从而不实际调用被调用者(Callee)是一个提升性能的利器。
由于函数调用与目标机的应用二进制接口(ABI)强相关,静态编译器如GCC/LLVM的函数内联优化基本是在指令生成之前完成。
ZendVM的内联则发生在opcode生成后的FCALL指令的替换优化,pass id为16,其原理大致如下:
| 遍历op_array中的opcode,找到DO_XCALL四个opcode之一
| opcode ZEND_INIT_FCALL
| opcode ZEND_INIT_FCALL_BY_NAMEZ
| 新建opcode,操作码置为ZEND_INIT_FCALL,计算栈大小,
更新缓存槽位,析构常量池字面量,替换当前opline的opcode
| opcode ZEND_INIT_NS_FCALL_BY_NAME
| 新建opcode,操作码置为ZEND_INIT_FCALL,计算栈大小,
更新缓存槽位,析构常量池字面量,替换当前opline的opcode
| 尝试函数内联
| 优化条件过滤 (每个优化pass通常有较多限制条件,某些场景下
由于缺乏足够信息不能优化或出于代价考虑而排除)
| 方法调用ZEND_INIT_METHOD_CALL,直接返回不内联
| 引用传参,直接返回不内联
| 缺省参数为命名常量,直接返回不内联
| 被调用函数有返回值,添加一条ZEND_QM_ASSIGN赋值opcode
| 被调用函数无返回值,插入一条ZEND_NOP空opcode
| 删除调用被内联函数的call opcode(即当前online的前一条opcode)如下示例代码,当调用fname()时,使用字符串变量名fname来动态调用函数foo,而没有使用直接调用的方式。此时可通过VLD扩展查看其生成的opcode,或打开opcache调试选项(opcache.optdebuglevel=0xFFFFFFFF)亦可查看。
function foo() { }
$fname = 'foo';开启debug后dump可看出,发生函数调用优化前opcode序列(仅截取片段)为:
ASSIGN CV0($fname) string("foo")
INIT_FCALL_BY_NAME 0 CV0($fname)
DO_FCALL_BY_NAMEINIT_FCALL_BY_NAME这条opcode执行逻辑较为复杂,当开启激进内联优化后,可将上述指令序列直接合并成一条DO_FCALL string("foo")指令,省去间接调用的开销。这样也恰好与直接调用生成的opcode一致。
根据以上描述,可见向当前优化器加入一个pass并不会太难,大体步骤如下:
先向zend_optimize优化器注册一个pass宏(例如添加pass17),并决定其优化级别。
在优化管理器某个优化pass前后调用加入的pass(例如添加一个尾递归优化pass),建议在DFA/SSA分析pass之后添加,因为此时获得的优化信息更多。
实现新加入的pass,进行定制代码转换(例如zendoptimizefunc_calls实现一个尾递归优化)。针对当前已有pass,主要添加转换pass,这里一般也可利用SSA/DFA的信息。不同于静态编译优化一般是在贴近于机器相关的低层中间表示优化,这里主要是在opcode层的opcode/operand相应的一些转换。
实现pass前,与函数内联类似,通常首先收集优化所需信息,然后排除掉不适用该优化的一些场景(如非真正的尾不递归调用、参数问题无法做优化等)。实现优化后,可dump优化前后生成opcode结构的变化是否优化正确、是否符合预期(如尾递归优化最终的效果是变换函数调用为forloop的形式)。
以下是对基于动态的PHP脚本程序执行的一些看法,仅供参考。
由于LLVM从前端到后端,从静态编译到jit整个工具链框架的支持,使得许多语言虚拟机都尝试整合。当前PHP7时代的ZendVM官方还没采用,原因之一虚拟机opcode承载着相当复杂的分析工作。相比于静态编译器的机器码每一条指令通常只干一件事情(通常是CPU指令时钟周期),opcode的操作数(operand)由于类型不固定,需要在运行期间做大量的类型检查、转换才能进行运算,这极度影响了执行效率。即使运行时采用jit,以byte code为单位编译,编译出的字节码也会与现有解释器一条一条opcode处理类似,类型需要处理、也不能把zval值直接存在寄存器。
以函数调用为例,比较现有的opcode执行与静态编译成机器码执行的区别,如下图:
在不改变现有opcode设计的前提下,加强类型推断能力,进而为opcode的执行提供更多的类型信息,是提高执行性能的可选方法之一。
既然opcode承担如此复杂的分析工作,能否将其分解成多层的opcode归一化中间表示( intermediate representation, IR)。各优化可选择应用哪一层中间表示,传统编译器的中间表示依据所携带信息量、从抽象的高级语言到贴近机器码,分成高级中间表示(HIR) 、中级中间表示(MIR)、低级中间表示(LIR)。
オペコードのパス管理の最適化については、前回の記事でも触れた通り、改善の余地があるはずです。現在の分析はデータフロー/制御フロー分析に依存していますが、実行順序、実行回数などのプロセス間のパス管理、登録管理、複雑なパス分析の情報ダンプなどの分析と最適化がまだ不足しています。 llvm などの成熟したフレームワークと比較すると、まだ不足しています。
ZendVM は、多数の zval 値、型変換、その他の操作を実装しており、LLVM の助けを借りて実行用のマシンコードにコンパイルできますが、コンパイル時間は非常に急速に増大します。もちろんlibjitも使えます。
以上がPHP でのオペコード最適化についての深い理解 (画像とテキスト)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



