

Java でのメモリ割り当てのヒープ、スタック、および定数プールの分析
Java メモリ割り当てには主に次の領域が含まれます:
1. レジスタ: プログラムでは制御できません
2. スタック: 基本的なタイプのデータとオブジェクトへの参照を格納しますが、オブジェクト自体はスタックに格納されません。ヒープに格納されます
3. ヒープ: new を使用して生成されたデータを格納します
4. 静的ドメイン: 静的メンバーをオブジェクトに格納します
5. 定数プール: 定数を格納します
6. ) アクセスメモリ) ストレージ: ハードディスクなどの永続的なストレージスペース
*********************************** ***** *******************************
Javaメモリ割り当てのスタック
一部関数の基本定義 型変数データとオブジェクト参照変数は関数のスタックメモリに確保されます。変数がコードのブロック内で定義されると、Java はスタック上の変数にメモリ領域を割り当てます。変数がスコープから出ると、Java は変数に割り当てられたメモリ領域を自動的に解放し、そのメモリ領域をすぐに使用できるようになります。他の目的に使用されること。
Java メモリ割り当てにおけるヒープ
ヒープ メモリは、new によって作成されたオブジェクトと配列を保存するために使用されます。 ヒープに割り当てられたメモリは、Java 仮想マシンの自動ガベージ コレクタによって管理されます。
ヒープ内に配列またはオブジェクトを生成した後、スタック内の変数の値がヒープ メモリ内の配列またはオブジェクトの最初のアドレスと等しくなるように、スタック内に特別な変数を定義することもできます。スタック内の変数は配列またはオブジェクトへの参照変数になります。参照変数は、配列またはオブジェクトに名前を付けることと同じであり、スタック内の参照変数を使用して、プログラム内のヒープ内の配列またはオブジェクトにアクセスできます。参照変数は、配列またはオブジェクトに名前を付けることと同じです。 参照変数は、定義時にスタック上に割り当てられる通常の変数で、プログラムがスコープ外で実行されると解放されます。配列やオブジェクト自体はヒープ内に割り当てられます。配列やオブジェクトを生成するために new を使用するステートメントが配置されているコード ブロックの外でプログラムが実行された場合でも、配列やオブジェクト自体が占有しているメモリは解放されません。オブジェクトにそれらを指す参照変数がない場合、それはガベージとなり使用できなくなりますが、依然としてメモリ空間を占有しており、後で不定の時点でガベージ コレクターによって収集 (解放) されます。これは、Java がより多くのメモリを消費する理由でもあります。実際、スタック内の変数はヒープメモリ内の変数を指します。これはJavaのポインタです。
定数プール(constant pool)
定数プールとは、コンパイル中に決定され、コンパイルされた .class ファイルに保存される一部のデータを指します。コード内で定義されているさまざまな基本型 (int、long など) とオブジェクト型 (String や配列 など) を含む 定数値 (final) に加えて、テキスト形式のシンボル参照:
- クラスとインターフェイスの完全修飾名、
- メソッド、名前、および記述子。
- 仮想マシンは、ロードされたタイプごとに一定のプールを維持する必要があります。定数プールは、この型で使用される定数の順序付きセットで、直接定数 (文字列、整数、浮動小数点定数) や他の型、フィールド、メソッドへのシンボリック参照が含まれます。 文字列定数の場合、その値は定数プールにあります。 JVM の定数プールは、メモリ内にテーブルの形式で存在します。String 型の場合、リテラル文字列値を格納するために使用される固定長の CONSTANT_String_info テーブルがあります。 注: このテーブルには、シンボルではなくリテラル文字列値のみが格納されます。 。ただし、定数プール内の文字列値の格納場所を明確に理解する必要があります。
プログラムが実行されると、定数プールはヒープではなくメソッド領域に格納されます。
ヒープとスタック
Javaのヒープはランタイムデータ領域であり、そこからクラス(オブジェクトが領域を割り当てます。これらのオブジェクトはnew、newarray、anearray、multianewarrayなどの命令を通じて作成され、プログラムは必要ありません) ヒープはガベージ コレクションを担当します。ヒープの利点は、メモリ サイズを動的に割り当てることができ、
ライフタイムを事前にコンパイラに伝える必要がないことです。実行時に動的にメモリを割り当てます。Java のガベージ コレクターはこれらの使用されなくなったデータを自動的に収集しますが、欠点は実行時に動的にメモリを割り当てる必要があるため、アクセス速度が遅いことです。 スタックの利点は、アクセス速度がヒープよりもレジスタに次いで速いことと、スタックデータを共有できることです。ただし、スタックに格納されるデータのサイズと有効期間を決定する必要があり、柔軟性に欠けるという欠点があります。スタックには主に、いくつかの基本的なタイプの変数データ (int、short、long、byte、float、double、boolean、char) とオブジェクト ハンドル (参照) が格納されます。 *********************************************** ****************** スタックと定数プール内のオブジェクトは共有できます ヒープオブジェクトは共有できません。スタック内のデータのサイズとライフサイクルを決定できます。データへの参照がなくなると、データは消えます。ヒープ内のオブジェクトはガベージ コレクターによってリサイクルされるため、サイズやライフ サイクルを決定する必要がなく、柔軟性に優れています。 文字列の場合、その オブジェクト参照は、コンパイル中に作成された場合 (二重引用符で直接定義された場合)、定数プールに保存されます。 , 実行時に決定される(新しいものが出てくる)場合は、ヒープ 等しい文字列の場合、定数プールには常にコピーが 1 つだけ存在し、ヒープには複数の コピーが存在します。 たとえば、次のコード: これもインタビューの質問です: Strings=newString(“xyz”); はオブジェクトをいくつ生成しますか? 1 つまたは 2 つ、定数プールに「xyz」がない場合は 2 つです。 出力結果: true [1] では、文字列の "+" 接続に文字列参照があるため、JVM は文字列参照を持ちます。参照の値は、プログラムのコンパイル中に決定できません。つまり、「a」+ bb は、プログラムの実行中に動的に割り当てられ、接続後に b に割り当てられるだけです。したがって、上記のプログラムの結果は false になります。 [2] と [1] の唯一の違いは、bb 文字列が最終的に変更されることです。最終的に変更された変数の場合、コンパイル時に定数値のローカル コピーに解析され、独自の定数プールに保存されます。バイトコードストリームに埋め込まれます。したがって、このときの「a」+bbと「a」+「b」の効果は同じです。したがって、上記のプログラムの結果は true になります。 結論: 基本型の変数と定数のメモリへの配置 基本型の変数と定数は、変数と参照はスタックに、定数は定数プールに格納されます。 次のコードのような:
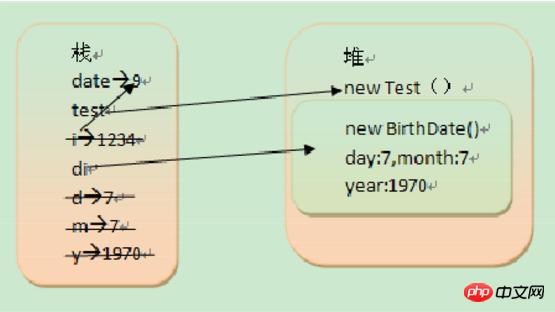
编译器先处理int i1 = 9;首先它会在栈中创建一个变量为i1的引用,然后查找栈中是否有9这个值,如果没找到,就将9存放进来,然后将i1指向9。接着处理int i2 = 9;在创建完i2的引用变量后,因为在栈中已经有9这个值,便将i2直接指向9。这样,就出现了i1与i2同时均指向9的情况。最后i3也指向这个9。 成员变量和局部变量在内存中的分配 对于成员变量和局部变量:成员变量就是方法外部,类的内部定义的变量;局部变量就是方法或语句块内部定义的变量。局部变量必须初始化。 形式参数是局部变量,局部变量的数据存在于栈内存中。栈内存中的局部变量随着方法的消失而消失。 成员变量存储在堆中的对象里面,由垃圾回收器负责回收。 如以下代码: 对于以上这段代码,date为局部变量,i,d,m,y都是形参为局部变量,day,month,year为成员变量。下面分析一下代码执行时候的变化: main方法开始执行:int date = 9; date局部变量,基础类型,引用和值都存在栈中。 Test test = new Test();test为对象引用,存在栈中,对象(new Test())存在堆中。 test.change(date); i为局部变量,引用和值存在栈中。当方法change执行完成后,i就会从栈中消失。 BirthDate d1= new BirthDate(7,7,1970); d1为对象引用,存在栈中,对象(new BirthDate())存在堆中,其中d,m,y为局部变量存储在栈中,且它们的类型为基础类型,因此它们的数据也存储在栈中。day,month,year为成员变量,它们存储在堆中(new BirthDate()里面)。当BirthDate构造方法执行完之后,d,m,y将从栈中消失。 main方法执行完之后,date变量,test,d1引用将从栈中消失,new Test(), new BirthDate()将等待垃圾回收。 String s1 = "china";
String s2 = "china";
String s3 = "china";
String ss1 = new String("china");
String ss2 = new String("china");
String ss3 = new String("china");
ここでは、new を通じて文字列 (「china」と仮定) を生成するときに、最初に定数に進みます。 "china" オブジェクトが見つからない場合は、定数プールに文字列オブジェクトを作成し、ヒープ内の定数プールに "china" オブジェクトのコピーを作成します。 
String s0= "kvill";
String s1=new String("kvill");
String s2=new String("kvill");
System.out.println( s0==s1 );
s1.intern();
s2=s2.intern(); //把常量池中"kvill"的引用赋给s2
System.out.println( s0==s1);
System.out.println( s0==s1.intern() );
System.out.println( s0==s2 );
true
文字列定数プールの問題のいくつかの例: 【1】
String a = "ab"= "b"= "a" +== b)); = "ab" String bb = "b"= "a" +== b)); = "ab" String bb == "a" +== b)); "b"
int i1 = 9; int i2 = 9; int i3 = 9; final int INT1 = 9; final int INT2 = 9; final int INT3 = 9;
class BirthDate { private int day; private int month; private int year; public BirthDate(int d, int m, int y) {
day = d;
month = m;
year = y;
} // 省略get,set方法………}public class Test { public static void main(String args[]) { int date = 9;
Test test = new Test();
test.change(date);
BirthDate d1 = new BirthDate(7, 7, 1970);
} public void change(int i) {
i = 1234;
}
}
以上がJava でのメモリ割り当てのヒープ、スタック、および定数プールの分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7480
7480
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33


 Java の乱数ジェネレーター
Aug 30, 2024 pm 04:27 PM
Java の乱数ジェネレーター
Aug 30, 2024 pm 04:27 PM
Java の乱数ジェネレーターのガイド。ここでは、Java の関数について例を挙げて説明し、2 つの異なるジェネレーターについて例を挙げて説明します。
 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
Java は、初心者と経験豊富な開発者の両方が学習できる人気のあるプログラミング言語です。このチュートリアルは基本的な概念から始まり、高度なトピックに進みます。 Java Development Kit をインストールしたら、簡単な「Hello, World!」プログラムを作成してプログラミングを練習できます。コードを理解したら、コマンド プロンプトを使用してプログラムをコンパイルして実行すると、コンソールに「Hello, World!」と出力されます。 Java の学習はプログラミングの旅の始まりであり、習熟が深まるにつれて、より複雑なアプリケーションを作成できるようになります。
