

毎日インターネットを閲覧していると、素敵な写真を目にすることが多く、その写真を保存してダウンロードしたり、デスクトップの壁紙やデザイン素材として使用したくなります。次の記事では、Python を使用して最も単純な Web クローラーを実装するための関連情報を紹介します。必要な方は一緒に参照してください。
前書き
ウェブ クローラー (ウェブ スパイダー、ウェブ ロボット、FOAF コミュニティではウェブ チェイサーとしても知られています) は、特定の規則に従って World Wide Web を自動的にクロールする方法です。情報番組またはスクリプト。最近、私は Python クローラーに非常に興味を持っています。ここで私の学習過程を共有し、皆様からの提案を歓迎したいと思います。私たちはお互いにコミュニケーションをとり、一緒に進歩していきます。さっそく、詳細な紹介を見てみましょう:
1. 開発ツール
私が使用するツールは、短くて簡潔な sublime text3 です (おそらく男性はこの言葉が好きではないでしょう)。 . 魅了されました。もちろん、コンピューターの構成が良好であれば、pycharm の方が適しているかもしれません。
sublime text3 を使用して Python 開発環境を構築するには、この記事を確認することをお勧めします:
[sublime を使用して Python 開発環境を構築する]
クローラーは、名前が示すように、上を這うバグのようなものです。インターネット。このようにして、私たちは欲しいものを手に入れることができます。
インターネット上をクロールしたいので、URLを理解する必要があります。正式名は「Uniform Resource Locator」、ニックネームは「link」です。その構造は主に 3 つの部分で構成されます:
(1) プロトコル: URL でよく見られる HTTP プロトコルなど。
(2) ドメイン名または IP アドレス: www.baidu.com などのドメイン名、IP アドレス、つまり、ドメイン名解決後の対応する IP。
(3) パス: ディレクトリまたはファイルなど。
3.urllibは最も単純なクローラーを開発します
(1) URL libの紹介
| モジュール | 紹介 |
|---|---|
| urllib.error | によって発生した例外クラスurllib.request. |
| urllib.parse | URL をコンポーネントに解析するか、コンポーネントから組み立てます。 |
| urllib.request | URL を開くための拡張ライブラリ。 |
| urllib.response | によって使用される応答クラスurllib. |
| urllib.robotparser | robots.txt ファイルをロードし、他の URL のフェッチ可能性に関する質問に答えます。 |
(2) 最も単純なクローラーを開発します
Baidu のホームページはシンプルでエレガントで、非常にシンプルで私たち爬虫類に適しています。
クローラーのコードは次のとおりです:
from urllib import request
def visit_baidu():
URL = "http://www.baidu.com"
# open the URL
req = request.urlopen(URL)
# read the URL
html = req.read()
# decode the URL to utf-8
html = html.decode("utf_8")
print(html)
if __name__ == '__main__':
visit_baidu()結果は以下のとおりです:
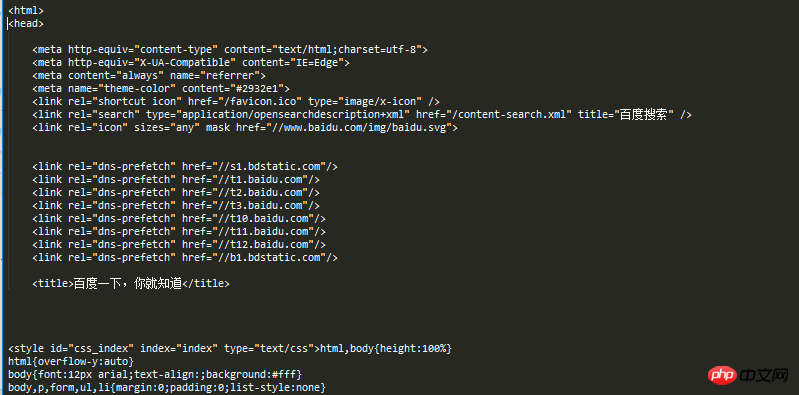
Baidu ホームページの空白スペースを右クリックして表示すると、実行結果と比較できます。レビュー要素。
もちろん、request は、urlopen メソッドを使用して開くことができる request オブジェクトを生成することもできます。
コードは次のとおりです:
from urllib import request def vists_baidu(): # create a request obkect req = request.Request('http://www.baidu.com') # open the request object response = request.urlopen(req) # read the response html = response.read() html = html.decode('utf-8') print(html) if __name__ == '__main__': vists_baidu()
実行結果は前と同じです。
(3) エラー処理
エラー処理は、主に URLError エラーと HTTPError エラーがあり、URLError エラーによってキャプチャすることもできます。
HTTPError は、その code 属性を通じて捕捉できます。
HTTPError を処理するコードは次のとおりです。
from urllib import request
from urllib import error
def Err():
url = "https://segmentfault.com/zzz"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.HTTPError as e:
print(e.code)
if __name__ == '__main__':
Err()実行結果は図に示すとおりです。

404 は印刷されたエラー コードです。この詳細情報については、Baidu を参照してください。
URLError は、reason 属性を通じて捕捉できます。
chuliHTTPError のコードは次のとおりです。
from urllib import request
from urllib import error
def Err():
url = "https://segmentf.com/"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.URLError as e:
print(e.reason)
if __name__ == '__main__':
Err()実行結果は図に示すとおりです。

エラーを処理するには、両方のエラーを結局のところ、コードは詳細であればあるほど明確になります。 HTTPError は URLError のサブクラスであるため、HTTPError を URLError の前に置く必要があることに注意してください。そうしないと、404 が Not Found として出力されるなど、URLError が出力されます。
コードは次のとおりです:
from urllib import request
from urllib import error
# 第一种方法,URLErroe和HTTPError
def Err():
url = "https://segmentfault.com/zzz"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.HTTPError as e:
print(e.code)
except error.URLError as e:
print(e.reason)URLを変更して、さまざまなエラーの出力フォームを表示できます。
概要
以上がPython での最も単純な Web クローラーのチュートリアルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



