
私は少し前に「Linux カーネルの詳細な理解」を読み、そのメモリ管理の部分に多くの時間を費やしましたが、まだあまり明確ではない質問がたくさんあり、最近少し時間をかけて見直しました。 Linux におけるメモリ管理についての私の理解をここに記録しました。
私は、テクノロジーそのものの発展の歴史、つまり、そのテクノロジーがどのように発展してきたのか、そのテクノロジー以前にはどのような特徴があり、なぜ現在のテクノロジーに置き換えられたのかを理解することを好みます。テクノロジーは以前のテクノロジーの問題を解決します。これらを理解すると、特定のテクノロジーをより明確に理解できるようになります。資料によっては、開発プロセスやその背後にある原理には言及せず、あるコンセプトの意味や原理を、あたかも空から技術が降ってきたかのように直接紹介しているものもあります。ここで、メモリ管理の発展の歴史を踏まえて、今日のテーマについて話していきましょう。
まず最初に、この記事のテーマは Linux メモリ管理におけるセグメンテーションとページング テクノロジであることを説明しなければなりません。
歴史を振り返ってみましょう。初期のコンピューターでは、プログラムは物理メモリ上で直接実行されていました。つまり、実行中にアクセスするプログラムはすべて物理アドレスになります。このシステムが実行するプログラムが 1 つだけであれば、そのプログラムが必要とするメモリがマシンの物理メモリを超えない限り問題はなく、面倒なメモリ管理を考慮する必要はありません。あなたのプログラムだけ、それだけです。お金を節約しましょう。十分に食べるかどうかはあなた次第です。ただし、今日のシステムはすべてマルチタスクとマルチプロセッシングをサポートしているため、CPU およびその他のハードウェアの使用率が高くなるため、システム内の限られた物理メモリを複数のプログラムにタイムリーに割り当てる方法を考慮する必要があります。と効果的な方法、このこと自体をメモリ管理と呼びます。
理解を容易にするために、初期のコンピューターシステムにおけるメモリ割り当て管理の例を示します。
プログラム 1、2、3 の 3 つのプログラムがあります。プログラム 1 は実行中に 10M のメモリが必要で、プログラム 2 は実行中に 100M のメモリが必要で、プログラム 3 は実行中に 20M のメモリが必要です。システムがプログラム A と B を同時に実行する必要がある場合、初期のメモリ管理プロセスはおそらく次のようになり、最初の 10M の物理メモリを A に割り当て、次の 10M ~ 110M を B に割り当てます。このメモリ管理方法は比較的簡単です。この時点でプログラム C を実行したいとします。システムのメモリが 128M しかないと仮定します。明らかに、この方法によれば、プログラム C はメモリ不足のため実行できません。メモリ。仮想メモリ技術を使用すると、メモリ領域が足りない場合に、プログラムが使用しないデータをディスク領域に交換でき、メモリ領域を拡張できることは誰もが知っています。このメモリ管理方法のより明らかな問題のいくつかを見てみましょう。記事の冒頭で述べたように、テクノロジーを深く理解するには、その開発の歴史を理解することが最善です。
プログラムは物理メモリに直接アクセスするため、現時点ではプログラムが使用するメモリ空間は分離されていません。たとえば、上で述べたように、A のアドレス空間は 0 ~ 10M の範囲ですが、A に 10M ~ 128M のアドレス空間のデータを操作するコードがある場合、プログラム B とプログラム C はクラッシュする可能性があります (すべてのプログラムがシステムのアドレス空間全体を占有する可能性があります)。このように、多くの悪意のあるプログラムやトロイの木馬プログラムは他のプログラムを簡単に破壊することができ、システムのセキュリティが保証されないため、ユーザーにとっては耐えられません。
上で述べたように、プログラム A、B、C を同時に実行したい場合、唯一の方法は、仮想メモリ技術を使用して、プログラムによって一時的に使用されていないデータを書き込むことです。プログラムをディスクにコピーし、必要に応じてディスクからメモリに戻します。ここで、プログラム C を実行する必要がある場合、プログラム A をディスクにスワップすることはできません。プログラム C には 20M のメモリが必要ですが、A には 10M のスペースしかないため、プログラム B をディスクにスワップする必要があります。ディスクは 100M で、プログラム C を実行するには、100M のデータをメモリからディスクに書き込み、プログラム B を実行するときにディスクからメモリにデータを読み取る必要があることがわかります。 IO 操作には時間がかかるため、このプロセスの効率は非常に低くなります。
プログラムを実行する必要があるたびに、メモリ内に十分な大きさの空き領域を割り当てる必要がありますが、問題は、この空き場所を決定できないことです。再配置の問題は、プログラム内で参照されている変数や関数のアドレスです。わからない場合は、コンパイル情報を確認してください。
メモリ管理とは、プロセスのアドレス空間をどうやって分離するか、メモリ使用効率をどう改善するか、プログラム実行時の再配置問題をどう解決するか、という上記3つの問題を解決する方法を見つけることにほかならないでしょうか?
以下は、検証できないコンピューター業界の引用です。「コンピューター システム内のあらゆる問題は、中間層を導入することで解決できます。」
現在のメモリ管理方法では、プログラムと物理メモリの間に仮想メモリの概念が導入されています。仮想メモリはプログラムと内部メモリの間に配置され、プログラムは仮想メモリのみを参照することができ、物理メモリに直接アクセスすることはできません。各プログラムには独自の独立したプロセス アドレス空間があり、プロセスの分離が実現されます。ここでのプロセス アドレス空間とは、仮想アドレスを指します。名前が示すように、仮想アドレスであるため、実際のアドレス空間ではなく仮想的なものになります。
プログラムと物理アドレス空間の間に仮想アドレスを追加したため、仮想アドレスから物理アドレスにマッピングする方法を解決する必要があります。プログラムは最終的には物理メモリで実行する必要があり、主に 2 つのタイプがあります。 : セグメンテーションとページング技術。
セグメンテーション: この方法は、人々が使用した最初の方法の 1 つであり、基本的な考え方は、プログラムが必要とするメモリ アドレス空間のサイズの仮想空間を特定の物理アドレス空間にマッピングすることです。
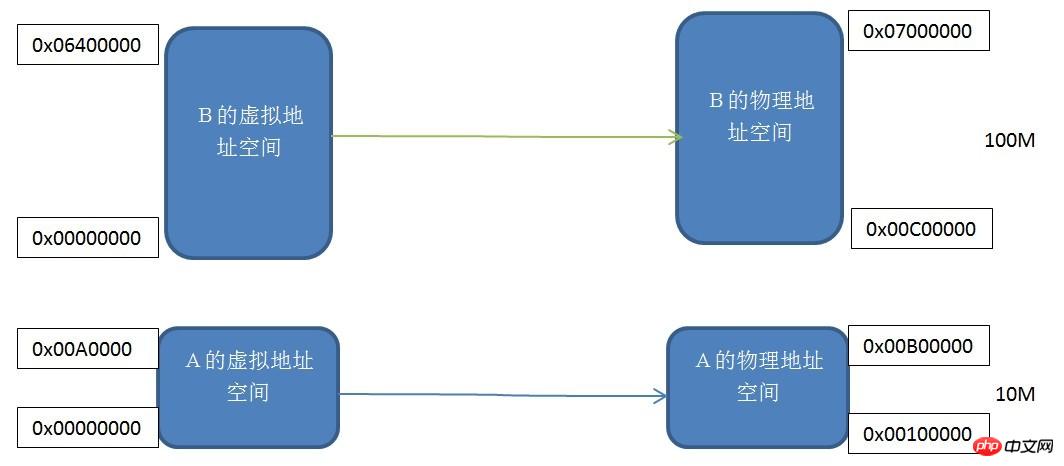
セグメントマッピングの仕組み
各プログラムは、独自の独立した仮想独立プロセスアドレス空間を持っています。プログラム A と B の仮想アドレス空間は両方とも 0x00000000 から始まることがわかります。同じサイズの 2 つの仮想アドレス空間を実際の物理アドレス空間に 1 つずつマッピングします。つまり、仮想アドレス空間の各バイトは、実際のアドレス空間の各バイトに対応します。このマッピング プロセスはソフトウェアによって設定されます。実際の変換はハードウェアによって行われます。
このセグメント化されたメカニズムは、記事の冒頭で述べたプロセス アドレス空間の分離とプログラム アドレスの再配置という 3 つの問題を解決します。プログラム A とプログラム B には独自の独立した仮想アドレス空間があり、プログラム A が仮想アドレス空間にアクセスするアドレスが 0x00000000 ~ 0x00A00000 の範囲にない場合、仮想アドレス空間は重複しない物理アドレス空間にマップされます。カーネルはこのリクエストを拒否するため、アドレス空間の分離の問題は解決されます。アプリケーション A は、仮想アドレス空間 0x00000000-0x00A00000 だけを気にする必要があり、どの物理アドレスにマップされているかを気にする必要がないため、プログラムは再配置せずに常にこの仮想アドレス空間に従って変数とコードを配置します。
セグメンテーションのメカニズムが上記の 2 つの問題をどのように解決しても、それは大きな進歩ですが、メモリ効率の問題はまだ解決できません。このメモリ マッピング メカニズムは依然としてプログラムに基づいているため、メモリが不十分な場合はプログラム全体をディスクにスワップする必要があり、メモリ使用効率は依然として非常に低いです。では、効率的なメモリ使用とはどのようなものでしょうか?実際、プログラムのローカル動作原理によれば、プログラム実行中の一定期間、頻繁に使用されるデータはごく一部です。したがって、現時点では、よりきめ細かいメモリの分割とマッピングの方法が必要です。Linux の Buddy アルゴリズムとスラブ メモリ割り当てメカニズムを思い浮かべてください。仮想アドレスを物理アドレスに変換するもう 1 つの方法は、ページング メカニズムです。
ページングメカニズム:
ページングメカニズムは、メモリのアドレス空間をいくつかの小さな固定サイズのページに分割することです。Linux の ext ファイル システムがディスクを複数のブロックに分割するのと同じように、各ページのサイズはメモリによって決まります。これは、メモリとディスクの使用率をそれぞれ改善するために行われます。次のことを想像してください。ディスク領域を N 等分し、各部分 (1 ブロック) のサイズが 1M で、ディスクに保存したいファイルが 1K バイトである場合、残りの 999 バイトは無駄になります。したがって、よりきめ細かいディスク パーティショニング方法が必要です。これは、もちろん、保存されているファイルのサイズに基づいて行うことができます。メモリ内のメカニズムは外部とは異なります。ファイル システムのディスク パーティショニング メカニズムは非常に似ています。
Linuxの一般的なページサイズは4KBです。プロセスのアドレス空間をページごとに分割し、よく使われるデータとコードページをメモリにロードし、あまり使われないコードとデータをディスクに保存します。以下に示す説明:
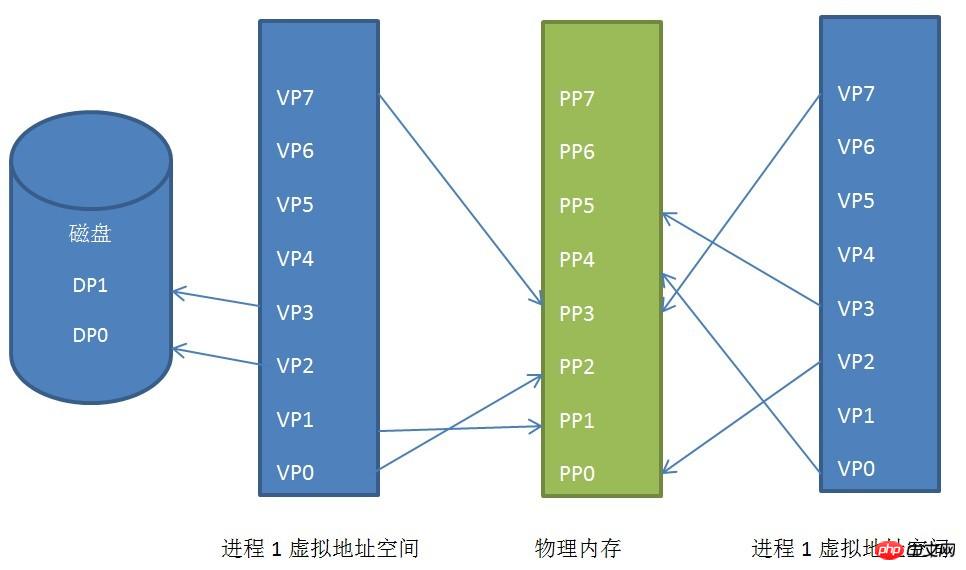
プロセスの仮想アドレス空間、物理アドレス空間、ディスク間のページマッピング関係
プロセス 1 とプロセス 2 の仮想アドレス空間が不連続な物理アドレスにマッピングされていることがわかります。空間(これは非常に重要です。ある日、十分な連続した物理アドレス空間がなくなったとしても、不連続なアドレス空間がたくさんある場合、このテクノロジーがなければプログラムは実行できなくなります)、あるいは一部を共有している場合さえあります。物理アドレス空間の、これは共有メモリです。
プロセス 1 の仮想ページ VP2 と VP3 がディスクにスワップされ、プログラムがこれら 2 つのページを必要とするとき、Linux カーネルはページフォールト例外を生成し、例外管理プログラムがそれをメモリに読み込みます。
これはページング メカニズムの原理です。もちろん、Linux でのページング メカニズムの実装は、グローバル ディレクトリ、上位レベルのディレクトリ、ページなどのいくつかのレベルのページング メカニズムを通じて実装されます。中間ディレクトリとページテーブルですが、基本的に動作原理は変わりません。
ページングメカニズムの実装にはハードウェア実装が必要です。このハードウェアの名前は MMU (Memory Management Unit) であり、特に仮想アドレスから物理アドレスへの変換、つまり仮想ページから物理ページの検索を担当します。
以上がLinux におけるメモリ管理の詳細な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



