

Python3 がリクエスト モジュールを使用してページ コンテンツをクロールする方法の詳細な例

この記事では主に、request モジュールを使用して python3 を使用してページ コンテンツをクロールする実際の方法を紹介します。興味のある方は学習してください。1. 私の個人用デスクトップ システムに pip
をインストールします。システムはデフォルトでは pip をインストールしません。後で request モジュールをインストールするために pip が使用されることを考慮して、ここでの最初のステップは pip をインストールすることです。
$ sudo apt install python-pip
インストールが成功しました。PIP バージョンを確認します:
$ pip -V
2. リクエストモジュールをインストールします
ここでは、pip を通じてインストールしました:
$ pip install requests
インポートを実行するエラーがない場合は、インストールが成功したことを意味します。 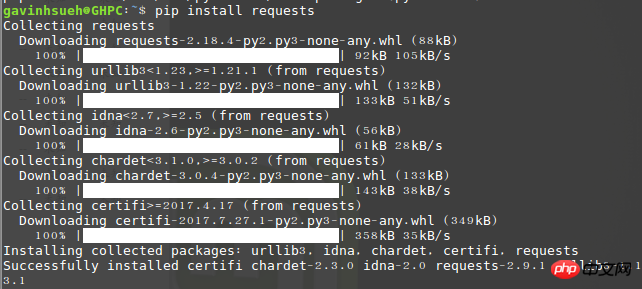
インストールが成功したかどうかを確認してください
3. beautifulsoup4をインストールします
Beautiful Soupは、HTMLまたはXMLファイルからデータを抽出できるPythonライブラリです。これにより、慣例的なドキュメント ナビゲーション、お気に入りのコンバーターを使用してドキュメントを検索および変更する方法が可能になります。 Beautiful Soup を使用すると、数時間、あるいは数日間の作業を節約できます。
$ sudo apt-get install python3-bs4
注: ここでは python3 のインストール方法を使用しています。python2 を使用している場合は、次のコマンドを使用してインストールできます。
$ sudo pip install beautifulsoup4
4.リクエストモジュールの簡単な分析
1) リクエストを送信します
まず第一に、もちろん、リクエストモジュールをインポートする必要があります:>>> import requests
次に、クロールされた対象の Web ページ。ここでは例として以下を取り上げます:
>>> r = requests.get('http://www.jb51.net/article/124421.htm')
ここでは、r という名前の応答オブジェクトが返されます。このオブジェクトから必要な情報はすべて取得できます。ここのgetはhttpのレスポンスメソッドなので、類推でput、delete、post、headに置き換えることもできます。
>>> payload = {'newwindow': '1', 'q': 'python爬虫', 'oq': 'python爬虫'}
>>> r = requests.get("https://www.google.com/search", params=payload)3) 応答コンテンツ
>>> import requests
>>> r = requests.get('https://github.com/timeline.json')
>>> r.textリクエストはサーバーからのコンテンツを自動的にデコードします。ほとんどの Unicode 文字セットはシームレスにデコードできます。 r.text と r.content の違いについて少し追加します。簡単に言うと、
>>> r = requests.get('http://www.cnblogs.com/') >>> r.encoding 'utf-8'
5) 応答ステータス コードを取得します
応答ステータス コードを検出できます:
>>> r = requests.get('http://www.cnblogs.com/') >>> r.status_code 200
オペレーティングシステム: linuxmint
Python バージョン: python 3.5.2使用モジュール:requests、Beautifulsoup4
コードは次のとおりです:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
_author_ = 'GavinHsueh'
import requests
import bs4
#要抓取的目标页码地址
url = 'http://www.ranzhi.org/book/ranzhi/about-ranzhi-4.html'
#抓取页码内容,返回响应对象
response = requests.get(url)
#查看响应状态码
status_code = response.status_code
#使用BeautifulSoup解析代码,并锁定页码指定标签内容
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
element = content.find_all(id='book')
print(status_code)
print(element)クロールは成功しました
クロール結果が文字化けする問題について
以上がPython3 がリクエスト モジュールを使用してページ コンテンツをクロールする方法の詳細な例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7555
7555
 15
1384
52
83
11
28
96
15
1384
52
83
11
28
96

![WLAN拡張モジュールが停止しました[修正]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) WLAN拡張モジュールが停止しました[修正]
Feb 19, 2024 pm 02:18 PM
WLAN拡張モジュールが停止しました[修正]
Feb 19, 2024 pm 02:18 PM
Windows コンピュータの WLAN 拡張モジュールに問題がある場合、インターネットから切断される可能性があります。この状況はイライラすることがよくありますが、幸いなことに、この記事では、この問題を解決し、ワイヤレス接続を再び正常に動作させるのに役立ついくつかの簡単な提案を提供します。 WLAN 拡張モジュールが停止しました。 WLAN 拡張モジュールが Windows コンピュータで動作を停止した場合は、次の提案に従って修正してください。 ネットワークとインターネットのトラブルシューティング ツールを実行して、ワイヤレス ネットワーク接続を無効にし、再度有効にします。 WLAN 自動構成サービスを再起動します。 電源オプションを変更します。 変更します。詳細な電源設定 ネットワーク アダプター ドライバーを再インストールする いくつかのネットワーク コマンドを実行する それでは、詳しく見てみましょう
 WLAN 拡張モジュールを開始できません
Feb 19, 2024 pm 05:09 PM
WLAN 拡張モジュールを開始できません
Feb 19, 2024 pm 05:09 PM
この記事では、無線 LAN 拡張モジュールが起動できないことを示すイベント ID10000 を解決する方法について詳しく説明します。このエラーは、Windows 11/10 PC のイベント ログに表示される場合があります。 WLAN 拡張モジュールは、独立系ハードウェア ベンダー (IHV) および独立系ソフトウェア ベンダー (ISV) がカスタマイズされたワイヤレス ネットワーク機能をユーザーに提供できるようにする Windows のコンポーネントです。 Windows のデフォルト機能を追加することで、ネイティブ Windows ネットワーク コンポーネントの機能を拡張します。 WLAN 拡張モジュールは、オペレーティング システムがネットワーク コンポーネントをロードするときに、初期化の一部として開始されます。無線 LAN 拡張モジュールに問題が発生して起動できない場合、イベント ビューアのログにエラー メッセージが表示されることがあります。
 PythonでCURLリクエストとPythonリクエストの相互変換を実現する方法
May 03, 2023 pm 12:49 PM
PythonでCURLリクエストとPythonリクエストの相互変換を実現する方法
May 03, 2023 pm 12:49 PM
curl と Pythonrequests は両方とも、HTTP リクエストを送信するための強力なツールです。 curl はターミナルから直接リクエストを送信できるコマンドライン ツールですが、Python のリクエスト ライブラリは、Python コードからリクエストを送信するためのよりプログラム的な方法を提供します。 curl を Pythonrequestscurl コマンドに変換するための基本的な構文は次のとおりです。curl[OPTIONS]URLcurl コマンドを Python リクエストに変換する場合、オプションと URL を Python コードに変換する必要があります。これは、curlPOST コマンドの例です:curl-XPOST https://example.com/api
 Python クローラーのリクエスト ライブラリの使用方法
May 16, 2023 am 11:46 AM
Python クローラーのリクエスト ライブラリの使用方法
May 16, 2023 am 11:46 AM
1. リクエスト ライブラリをインストールします。学習プロセスでは Python 言語を使用するため、Python を事前にインストールする必要があります。私は Python 3.8 をインストールしました。インストールした Python のバージョンは、コマンド python --version を実行することで確認できます。 Python 3.X 以降をインストールします。 Python をインストールした後、次のコマンドを使用してリクエスト ライブラリを直接インストールできます。 pipinstallrequestsPs: Alibaba や Douban などの国内の pip ソースに切り替えることができ、高速です。機能を実証するために、nginx を使用して簡単な Web サイトをシミュレートしました。ダウンロード後、ルート ディレクトリで nginx.exe プログラムを実行するだけです。
 Python で一般的に使用される標準ライブラリとサードパーティ ライブラリ 2-sys モジュール
Apr 10, 2023 pm 02:56 PM
Python で一般的に使用される標準ライブラリとサードパーティ ライブラリ 2-sys モジュール
Apr 10, 2023 pm 02:56 PM
1. sys モジュールの紹介 前に紹介した os モジュールは主にオペレーティング システム用ですが、この記事の sys モジュールは主に Python インタプリタ用です。 sys モジュールは Python に付属するモジュールで、Python インタープリターと対話するためのインターフェイスです。 sys モジュールは、Python ランタイム環境のさまざまな部分を処理するための多くの関数と変数を提供します。 2. sys モジュールの一般的に使用されるメソッド: dir() メソッドを使用して、sys モジュールにどのメソッドが含まれているかを確認できます: import sys print(dir(sys))1.sys.argv - コマンド ライン パラメーター sys を取得します。 argv は、プログラムの外部からコマンドを実装するために使用されます。プログラムにはパラメータが渡され、コマンド ライン パラメータの列を取得できます。
 Pythonプログラミング:名前付きタプルの使い方のポイントを詳しく解説
Apr 11, 2023 pm 09:22 PM
Pythonプログラミング:名前付きタプルの使い方のポイントを詳しく解説
Apr 11, 2023 pm 09:22 PM
はじめに この記事では、Python コレクション モジュールの紹介に引き続き、今回はその中の名前付きタプル、つまり、namedtuple の使い方を主に紹介します。これ以上の苦労はせずに、始めましょう – いいね、フォロー、転送することを忘れないでください~ ^_^名前付きタプルの作成 Python コレクションの名前付きタプル クラスnamedTuples は、タプル内の各位置に意味を与え、コードの読みやすさを向上させます。これらは通常のタプルが使用される場所ならどこでも使用でき、位置インデックスではなく名前によってフィールドにアクセスする機能を追加します。これは、Python 組み込みモジュール コレクションから取得されます。使用される一般的な構文は次のとおりです。 import collections XxNamedT
 Python がリクエストを使用して Web ページをリクエストする方法
Apr 25, 2023 am 09:29 AM
Python がリクエストを使用して Web ページをリクエストする方法
Apr 25, 2023 am 09:29 AM
リクエストは urllib2 のすべての機能を継承します。リクエストは、HTTP 接続の永続性と接続プーリング、セッションを維持するための Cookie の使用、ファイルのアップロード、応答コンテンツのエンコードの自動決定、国際化された URL と POST データの自動エンコードをサポートします。インストール方法は、pip を使用してインストールします。 $pipinstallrequestsGET リクエスト 基本的な GET リクエスト (ヘッダー パラメーターとパラメータ パラメーター) 1. 最も基本的な GET リクエストは、get メソッド 'response=requests.get("http://www.baidu.com/ "
 Python のインポートはどのように機能するのでしょうか?
May 15, 2023 pm 08:13 PM
Python のインポートはどのように機能するのでしょうか?
May 15, 2023 pm 08:13 PM
こんにちは、私の名前はsomenzzです。鄭兄弟と呼んでください。 Python のインポートは非常に直感的ですが、それでも、パッケージがそこにあるにもかかわらず、ModuleNotFoundError が発生することがあります。明らかに、相対パスは非常に正しいですが、エラー ImportError:attemptedrelativeimportwithnoknownparentpackage により、同じディレクトリにモジュールがインポートされ、別のものです。ディレクトリのモジュールは完全に異なります。この記事は、インポートの使用時によく発生するいくつかの問題を分析することで、インポートを簡単に処理するのに役立ちます。これに基づいて、属性を簡単に作成できます。
