

以下のエディターは、Hadoop での Java Web クローラーの実装に関する記事を提供します (例による説明)。編集者はこれがとても良いと思ったので、参考として共有します。エディターに従って、この Web クローラーの実装を見てみましょう。ビッグデータに関するものです。 Java での Web クローラーの実装と Heritrix での Web クローラーの実装に関する前の 2 つの記事に基づいて、今回は完全なデータ収集、データのアップロード、データ分析、データ結果の読み取り、およびデータの視覚化を完了する必要があります。
Cygwin: Windows プラットフォーム上で実行される UNIX のようなシミュレーション環境を使用する必要があります。オンラインで直接検索してダウンロードし、インストールします。Hadoop: Hadoop 環境を構成し、分散ファイル システム (Hadoop) を実装します。 HDFS と呼ばれる分散ファイル システムは、収集されたデータを HDFS に直接アップロードして保存し、MapReduce で分析するために使用されます。
Eclipse: コードを作成するには、Hadoop jar パッケージをインポートして MapReduce を作成する必要があります。プロジェクト; Jsoup: 正規表現と組み合わせた HTML jar パッケージの解析により、Web ページのソース コードをより適切に解析できます。 ディレクトリ: 1.2. Hadoop Huang Jing の設定
3. Eclipse 開発環境の構築
-------->1.公式 Web サイトから Cygwin
をインストールして設定します。 Cygwin インストール ファイルを次の場所からダウンロードします。 https://cygwin.com/install.html
ダウンロードして実行した後、インストール インターフェイスに入ります。
インストール中にネットワークミラーから拡張パッケージを直接ダウンロードしますインストール後に cygwin コンソールインターフェイスに入り、
SSH をインストールするために ssh および ssl サポートパッケージを選択する必要があります。入力: no、yes、ntsec、no、no
注: win7 では、パスワードを入力してこのステップを確認する必要があります 完了後、Cygwin sshd が作成されます。サービスは Windows オペレーティング システムで構成され、Just Serve を開始します。
次に、ssh パスワード不要のログインを設定します cygwin を再実行します。 ssh localhost を実行すると、ログインするためにパスワードを使用するように求められます。 ssh-keygen コマンドを使用して ssh キーを生成し、Enter キーを押して終了します。 生成後、.ssh ディレクトリに入り、コマンド cp id_rsa.pub allowed_keys コマンドを使用してキーを構成します。 終了するには exit を使用してください。 システムに再ログインした後は、パスワードを入力せずに ssh localhost 経由でシステムに直接入ることができます。 2. Hadoop 環境を構成する
2. Hadoop 環境を構成する
hadoop-env.sh ファイルを変更し、JDK インストール ディレクトリの JAVA_HOME の場所設定を追加します。
# The java implementation to use. Required. export JAVA_HOME=/cygdrive/c/Java/jdk1.7.0_67
Program Files は PROGRA~1 と省略されます
hdfs-site.xml を変更し、ストレージ コピーを 1 に設定します (構成が疑似分散されているため)
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
HDFS: Hadoop 分散ファイル システムHDFS のコマンドを通じてファイルまたはフォルダーを動的に CRUD できます
権限の問題がある可能性があることに注意してください。hdfs-site.xml で次の内容を構成する必要があります。回避: 
<property> <name>dfs.permissions</name> <value>false</value> </property>
mapred-site.xmlを変更し、JobTrackerが実行されるサーバーとポート番号を設定します(現在このマシンで実行されているため、localhostを直接記述するだけで、ポートは任意の空きポートにバインドできます)
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
上記の内容を設定した後、Cygwinのhadoopディレクトリに入ります
bin ディレクトリで、HDFS ファイル システムをフォーマットし (最初に使用する前にフォーマットする必要があります)、起動コマンド 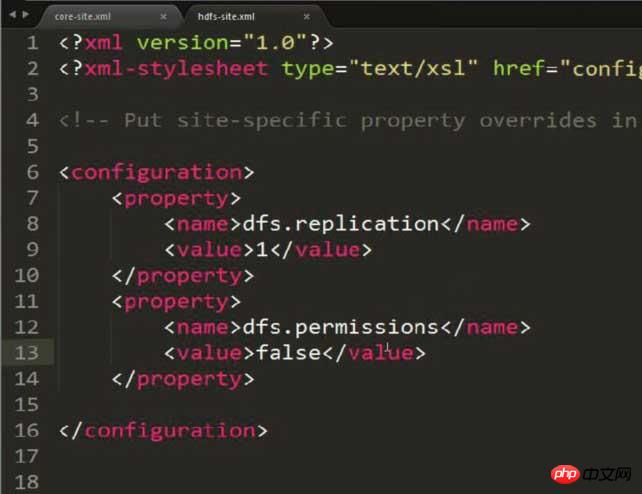
3 を入力します。
一般的な設定方法は、ビッグデータ [2] HDFS デプロイメントとファイルの読み取りと書き込み (Eclipse Hadoop 設定を含む) について書いたブログに記載されています。ただし、現時点では改善する必要があります。
 Eclipseを起動したら、MapReduceインターフェースに切り替えます。
Eclipseを起動したら、MapReduceインターフェースに切り替えます。
在windows工具选项选择showviews的others里面查找map/reduce locations。
在Map/Reduce Locations窗口中建立一个Hadoop Location,以便与Hadoop进行关联。

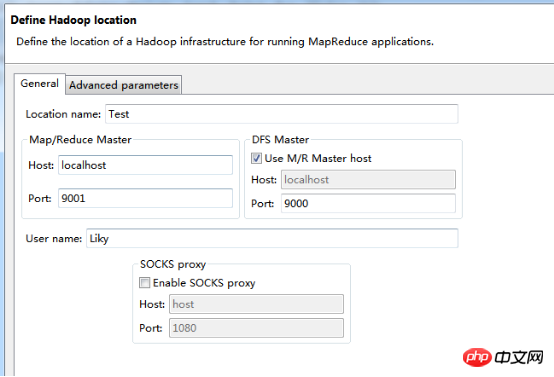
注意:此处的两个端口应为你配置hadoop的时候设置的端口!!!
完成后会建立好一个Hadoop Location
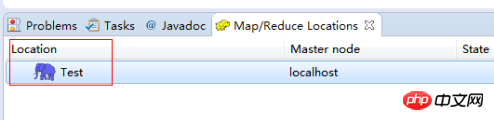
在左侧的DFS Location中,还可以看到HDFS中的各个目录
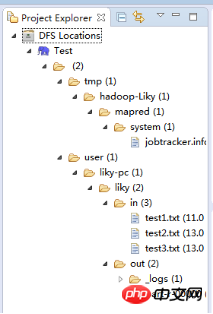
并且你可以在其目录下自由创建文件夹来存取数据。
下面你就可以创建mapreduce项目了,方法同正常创建一样。
4、网络数据爬取
现在我们通过编写一段程序,来将爬取的新闻内容的有效信息保存到HDFS中。
此时就有了两种网络爬虫的方法:
其一就是利用heritrix工具获取的数据;
其一就是java代码结合jsoup编写的网络爬虫。
方法一的信息保存到HDFS:
直接读取生成的本地文件,用jsoup解析html,此时需要将jsoup的jar包导入到项目中。
package org.liky.sina.save;
//这里用到了JSoup开发包,该包可以很简单的提取到HTML中的有效信息
import java.io.File;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class SinaNewsData {
private static Configuration conf = new Configuration();
private static FileSystem fs;
private static Path path;
private static int count = 0;
public static void main(String[] args) {
parseAllFile(new File(
"E:/heritrix-1.12.1/jobs/sina_news_job_02-20170814013255352/mirror/"));
}
public static void parseAllFile(File file) {
// 判断类型
if (file.isDirectory()) {
// 文件夹
File[] allFile = file.listFiles();
if (allFile != null) {
for (File f : allFile) {
parseAllFile(f);
}
}
} else {
// 文件
if (file.getName().endsWith(".html")
|| file.getName().endsWith(".shtml")) {
parseContent(file.getAbsolutePath());
}
}
}
public static void parseContent(String filePath) {
try {
//用jsoup的方法读取文件路径
Document doc = Jsoup.parse(new File(filePath), "utf-8");
//读取标题
String title = doc.title();
Elements descElem = doc.getElementsByAttributeValue("name",
"description");
Element descE = descElem.first();
// 读取内容
String content = descE.attr("content");
if (title != null && content != null) {
//通过Path来保存数据到HDFS中
path = new Path("hdfs://localhost:9000/input/"
+ System.currentTimeMillis() + ".txt");
fs = path.getFileSystem(conf);
// 建立输出流对象
FSDataOutputStream os = fs.create(path);
// 使用os完成输出
os.writeChars(title + "\r\n" + content);
os.close();
count++;
System.out.println("已经完成" + count + " 个!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}以上がHadoopでのJava Webクローラーの実装方法の紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



