

Python で Django で haystack を使用する方法: 全文検索フレームワークの例

以下のエディターは、Python と Django での haystack の使用に関する記事を提供します: 全文検索フレームワーク (例付きの説明)。編集者はこれがとても良いものだと思ったので、皆さんの参考として今から共有します。編集者をフォローして一緒に見てみましょう
haystack: 全文検索フレームワーク
whoosh: 純粋な Python で書かれた全文検索エンジン
jieba: 無料の中国語単語分割パッケージ
まず、これら 3 つのパッケージをインストールします
pip install django-haystack
pip install whoosh
pip install jieba
1 settings.py ファイルを変更し、アプリケーション haystack をインストールします
2。 settings.py ファイル内で検索エンジンを設定します
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'3. templates ディレクトリの下に "search/indexes/blog/" ディレクトリを作成し、ブログ アプリケーション名の下にファイル blog_text.txt を作成します
#指定インデックスの属性
{{ object.title }}
{{ object.text}}
{{ object.keywords }}
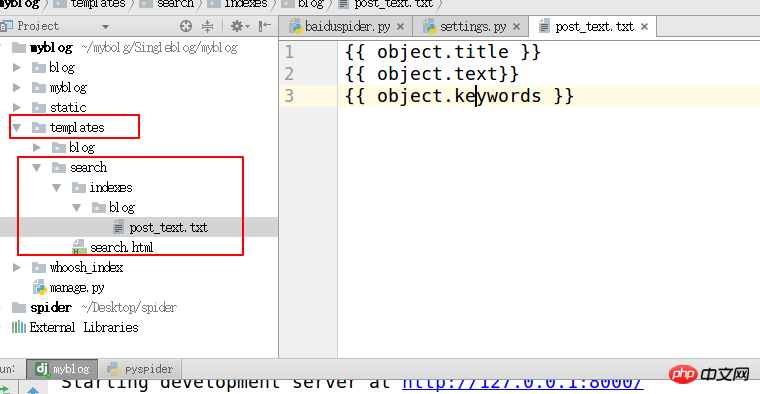
4. search_indexes を作成します
from haystack import indexes from models import Post #指定对于某个类的某些数据建立索引 class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) def get_model(self): return Post #搜索的模型类 def index_queryset(self, using=None): return self.get_model().objects.all()
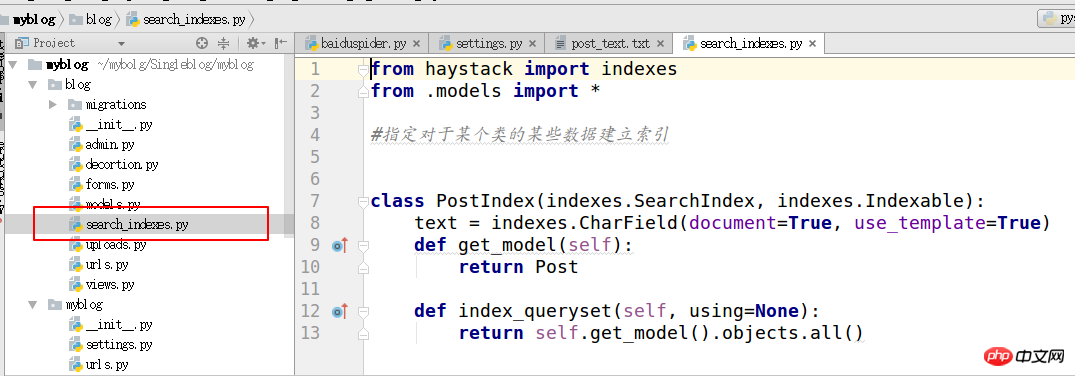
5.
1. haystack ファイルを変更します
2. 仮想環境 py_django で haystack ディレクトリを見つけます。このディレクトリは、使用している Python 環境に応じて異なります。
3. site-packages/haystack/backends/ ChineseAnalyzer.py という名前のファイルを作成し、中国語単語分割用の次のコードを記述します
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()6.
1. whoosh_backend.py ファイルをコピーして変更します。コピーしたファイルに中国語単語分割モジュールを次の名前でインポートします
whoosh_cn_backend.py
from . ChineseAnalyzer import ChineseAnalyzer
2. 単語分析クラスを中国語に変更します
analyzer=StemmingAnalyzer()を探して次のように変更します。 analyzer= ChineseAnalyzer()
7. 最後のステップは、初期インデックス データを作成することです
python manage.py build_index
8. template/indexes/ に検索テンプレートを作成し、search.html テンプレートを作成します
結果はページ分割され、ビューはテンプレートに渡されます。 コンテキストは次のとおりです
query: 検索キーワード
page: 現在のページのページ オブジェクト
paginator: paginator オブジェクト
9 モジュールをインポートします。独自のアプリケーション ビュー
from haystack.generic_views import SearchView
カスタム コンテキストをテンプレートに渡せるように、get_context_data メソッドをオーバーライドするクラスを定義します。
class GoodsSearchView(SearchView): def get_context_data(self, *args, **kwargs): context = super().get_context_data(*args, **kwargs) context['iscart']=1 context['qwjs']=2 return context
この URL をアプリケーションの URL ファイルに追加し、クラスをビュー メソッド .as_view() として使用します
url('^search/$', views.BlogSearchView.as_view())
以上がPython で Django で haystack を使用する方法: 全文検索フレームワークの例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7321
7321
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

 ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
多くのウェブサイト開発者は、ランプアーキテクチャの下でnode.jsまたはPythonサービスを統合する問題に直面しています:既存のランプ(Linux Apache MySQL PHP)アーキテクチャWebサイトのニーズ...
 Scapy Crawlerを使用するときにパイプラインの永続的なストレージファイルを書き込めない理由は何ですか?
Apr 01, 2025 pm 04:03 PM
Scapy Crawlerを使用するときにパイプラインの永続的なストレージファイルを書き込めない理由は何ですか?
Apr 01, 2025 pm 04:03 PM
Scapy Crawlerを使用する場合、パイプラインの永続的なストレージファイルを書くことができない理由は?ディスカッションデータクローラーにScapy Crawlerを使用することを学ぶとき、あなたはしばしば...
 PythonプロセスプールがTCPリクエストを同時に処理し、クライアントが立ち往生する理由は何ですか?
Apr 01, 2025 pm 04:09 PM
PythonプロセスプールがTCPリクエストを同時に処理し、クライアントが立ち往生する理由は何ですか?
Apr 01, 2025 pm 04:09 PM
Python Process Poolは、クライアントが立ち往生する原因となる同時TCP要求を処理します。ネットワークプログラミングにPythonを使用する場合、同時のTCP要求を効率的に処理することが重要です。 ...
 Python functools.partialオブジェクトによって内部的にカプセル化された元の関数を表示する方法は?
Apr 01, 2025 pm 04:15 PM
Python functools.partialオブジェクトによって内部的にカプセル化された元の関数を表示する方法は?
Apr 01, 2025 pm 04:15 PM
python functools.partialオブジェクトのpython functools.partialを使用してPythonを使用する視聴方法を深く探索します。
 LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示する際の許可の問題の解決策PythonターミナルでPythonバージョンを表示しようとするとき、Pythonを入力してください...
 Pythonクロスプラットフォームデスクトップアプリケーション開発:どのGUIライブラリが最適ですか?
Apr 01, 2025 pm 05:24 PM
Pythonクロスプラットフォームデスクトップアプリケーション開発:どのGUIライブラリが最適ですか?
Apr 01, 2025 pm 05:24 PM
Pythonクロスプラットフォームデスクトップアプリケーション開発ライブラリの選択多くのPython開発者は、WindowsシステムとLinuxシステムの両方で実行できるデスクトップアプリケーションを開発したいと考えています...
 Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python:Hourglassグラフィック図面と入力検証この記事では、Python NoviceがHourglass Graphic Drawingプログラムで遭遇する可変定義の問題を解決します。コード...
 Pythonで大規模な製品データセットを効率的にカウントしてソートするにはどうすればよいですか?
Apr 01, 2025 pm 08:03 PM
Pythonで大規模な製品データセットを効率的にカウントしてソートするにはどうすればよいですか?
Apr 01, 2025 pm 08:03 PM
データの変換と統計:大規模なデータセットの効率的な処理この記事では、製品情報を含むデータリストを別の含有しているものに変換する方法を詳細に紹介します...
