

Mysqlに関連する操作は何ですか?
1》データベースの作成:
構文: create database データベース名; に注意してください>
例:
Mysql-> zytest を削除します
innoDB は A ストレージですmysql 用エンジンである inodb は、mysql テーブルのトランザクション ログ、ロールバック、クラッシュ、修復機能、およびマルチバージョン同時実行制御トランザクション セキュリティを提供します。 Mysql には、3.23.34a 以降、innoDB ストレージ エンジンが含まれています。 InnoDB は、外部キー制約を提供する最初のテーブル エンジンであり、innoDB でトランザクションを処理する機能を備えています。それは他のエンジンでは太刀打ちできないものでもあります。 、InnoDBは、Auto_incrementを使用して自動インクリメント列をサポートしています。 table は主キーである必要があります。親テーブルの情報が削除または更新されると、それに応じて子テーブルも変更される必要があります。 innodb ストレージ エンジンでは、作成されたテーブルのテーブル構造が frm ファイルに保存されます。 、 innodb_data_home_dir パラメーターが定義されていない場合、データとインデックスは、すべてのテーブルの innodb_data_home_dir および innodb_data_file_path 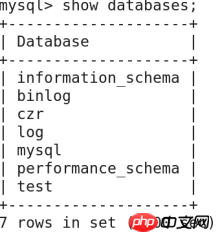
メタデータ ファイル ibdata1 で定義されたテーブルスペースに保存されます。デフォルトでは、InnoDB の各データ テーブルのメタデータは常に ibdata1 の共有テーブル領域に保存されるため、このファイルは必須です。
innodb_data_file_path = ibdata1:10M:autoextend
ファイルはまとめられています: *.ibd 各テーブルには個別のメタデータがあります、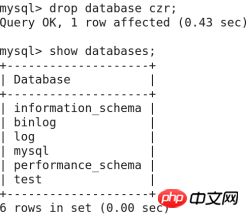 テーブル定義ファイル: *.frm
テーブル定義ファイル: *.frm
Inoodb ストレージ エンジンの
利点: 優れたトランザクション管理、クラッシュ、修復を提供します
欠点: 読み取りと書き込みの効率がやや悪く、比較的大きなデータ領域を消費します
ACIDはデータベーストランザクションを通常に実行するための4つの基本要素で、それぞれ原子性、一貫性、独立性、耐久性を指します 原子性:
トランザクションの原子性は1つを指しますつまり、トランザクションの半分だけを停止することは不可能です。たとえば、これらの 2 つのステップは、次の時点で完了する必要があります。または、それらは完了していません。 整合性
:
トランザクションの整合性は、トランザクションの実行によってデータベース内のデータが変更されないことを意味します。たとえば、整合性が a+b=10 である場合。 、トランザクションが a を変更すると、それに応じて b も変更されるはずです
独立性 (孤立性)
トランザクションの独立性は、2 つ以上のトランザクションが
時間差で実行されないことを意味します。データの不整合が発生します 耐久性: 2>MyISAMエンジン L q mysql-& gt; 3>查询Mysql默认存储引擎 如果想修改存储引擎,可以在 my.ini中进行修改或者my.cnf中的Default-storage-engine=引擎类型; 5》如何选择存储引擎: 在企业生产环境中,选择一个款合适的存储引擎是一个很复杂的问题。每一种存储引擎都有各自的优势,不能笼统的说,谁比谁好。通常用的比较多的 是innodb存储引擎 ==========================创建,修改,删除表: 1》创建表的方法: 2》表的完整性约束: | 约束条件 | 说明| | (1)primary key | 标识该字段为表的主键,具备唯一性| | (2)foreign key | 标识该字段为表的外键,与某表的主键联系| | (3)not null | 标识该属于的值不能为空| | (4)unique | 标识这个属性值是唯一| | (5)auto_increment | 标识该属性值的自动增加 | (6)default | 为该属性值设置默认值| 1>设置表的主键: 举例: 2>设置多个字段做主键 3>设置表的外键: (1) yy1表存储了zhangsan姓名和ID号 (2) yy2表存储了ID号和zhangsan的年龄(old) (3)数据填充yy1和yy2表 (4)更新测试: (5)删除测试: 4>设置表的非空值 5> 设置表的唯一性约束 6>设置表的属性值自动增加 7>、设置表的默认值 插入数据,应为ID为自增,值为空,user_name设置了默认值,所以也为空。 3》查看表结构的方法: 2>修改表的数据类型 3>修改表的字段名称 4>修改增加字段 v 增加没有约束条件的字段: v 增加有完整约束条件的字段 v 在表的第一个位置增加字段默认情况每次增加的字段。都在表的最后。 v 执行在那个位置插入新的字段,在phone后面增加 总结: 6>更改表的存储引擎 7>删除表的外键约束
トランザクションの耐久性とは、トランザクションが正常に実行された後、データベースに加えられたトランザクションが永続的に保存され、理由もなくロールバックされないことを意味します。
ccogene Rep
ローグ Myi は、拡張子
が付いたファイルストレージインデックスです 利点: 占有スペースがほとんどありません。処理速度が速い
欠点: トランザクション ログの整合性と同時実行性をサポートしていない 3>MEMORY エンジン Mysql の特別なエンジンで、エンタープライズ運用環境ではすべてのデータがメモリに保存されます。ほとんど役に立たない。データはメモリに保存されるため、メモリ内で例外が発生した場合。データの整合性に影響します。長所: 高速ストレージ
MyISAM: 外部キーをサポートせず、トランザクションをサポートせず、インデックスとデータが分離され、より多くのインデックスをロードでき、インデックスはメモリに比べて圧縮されます使用効率の点では、テーブル ロック メカニズムを使用して、複数の同時読み取りおよび書き込み操作を最適化しています。 使用用途: 実行されるプロジェクトのほとんどは、複数の読み取りと書き込みです。プロジェクトプラットフォームでは、MyISAM の読み取りパフォーマンスは Innodb よりもはるかに優れています
Innodb: 外部キー、トランザクション、ロールバックをサポートしますが、インデックスとデータは緊密にバインドされており、圧縮は使用されないため、INNODB の方がはるかに大きくなりますミサム。
使用状況: ホストされているほとんどのプロジェクトで挿入と更新を実行する場合は、InnoDB ロック、ページ ロック、行レベル ロックを選択する必要があります。テーブル レベルのロックには、テーブル共有読み取りロックとテーブル排他的書き込みの 2 つのモードがあります。ロック。
MyISAM: テーブルレベルのロック: myisam テーブルで読み取り操作を実行する場合、同じテーブルに対する他のユーザーの読み取りリクエストはブロックされませんが、ブロックされます。同じテーブルに対する他のユーザーの読み取りリクエスト> ; 書き込み操作; myisam テーブルに書き込むとき、同じテーブルに対する他のユーザーの読み取りリクエストと書き込みリクエストをブロックします
さらに、行ロック (行レベルでのロック) を提供します。 InnoDB テーブルの行ロックは絶対的ではありません。MySQL が SQL ステートメントの実行時にスキャンする範囲を決定できない場合、InnoDB テーブルはテーブル全体もロックします。
行レベルの利点ロックは次のとおりです:
1) 多くの接続がそれぞれ異なるクエリを実行する場合、LOCK 状態を軽減します。
2)例外が発生した場合、データの損失を軽減できます。一度にロールバックできるのは、少量のデータの 1 行または数行だけであるためです。 行レベルのロックの欠点は次のとおりです: 1) ページレベルのロックやテーブルレベルのロックよりも多くのメモリを消費します。 2) クエリにはページレベルのロックやテーブルレベルのロックよりも多くの I/O が必要なので、読み取り操作ではなく書き込み操作に行レベルのロックを使用することがよくあります。 3)デッドロックが発生しやすい。
注: inodb はこの時点で操作の行を決定できません。つまり、行レベルのテーブル ロックが使用されます)。ストレージ エンジン: ストレージ エンジン Mysql の機能であり、トランザクション処理を実行するかどうかなど、複数のストレージ エンジンと異なるストレージ メソッドを選択できます。 ;
2> MySQL エンジンの詳細をクエリする: Mysql->show engine innodb status\G;
Mysql-> show variables like 'storage_engine';

以下是存储引擎的对比: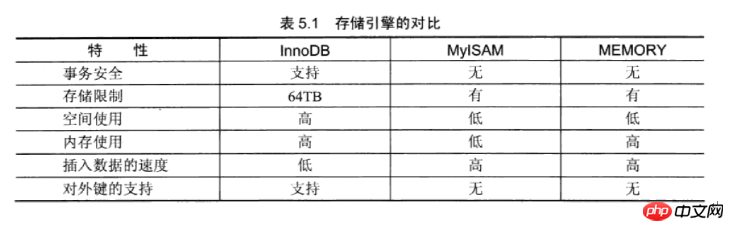
语法:create table 表名(
属性名数据类型完整约束条件,
属性名数据类型条完整约束件,
。。。。。。。。。
属性名数据类型
);
举例: create table example0(
id int,
name varchar(20),
sexboolean);
主键是一个表的特殊字段,这个字段是唯一标识表中的每条信息,主键和记录的关系,跟人的身份证一样。名字可以一样,但是身份证号码觉得不会一样, 主键用来标识每个记录,每个记录的主键值都不同,主键可以帮助Mysql以最快的速度查找到表中的某一条信息,主键必须满足的条件那就是它的唯一性,表中的 任意两条记录的主键值,不能相同,否则就会出现主键值冲突,主键值不能为空,可以是单一的字段,也可以多个字段的组合。 create table sxkj(
User_id int primary key,
user_name varchar(20),
user_sexchar(7));
举例: create table sxkj2(
user_id int ,
user_name float,
grade float,
primary key(user_id,user_name));
外键是表的一个特殊字段,如果aa是B表的一个属性且依赖于A表的主键,那么A表被称为父表。B表为被称为子表,
举例说明:
user_id 是A 表的主键,aa 是B表的外键,那么user_id的值为zhangsan,如果这个zhangsan离职了,需要从A表中删除,那么B表关于 zhangsan的信息也该得到相应的删除,这样可以保证信息的完整性。
语法:
constraint外键别名 foreign key(外键字段1,外键字段2)
references 表名(关联的主键字段1,主键字段2)
create table yy1(
user_id int primary key not null,
user_name varchar(20));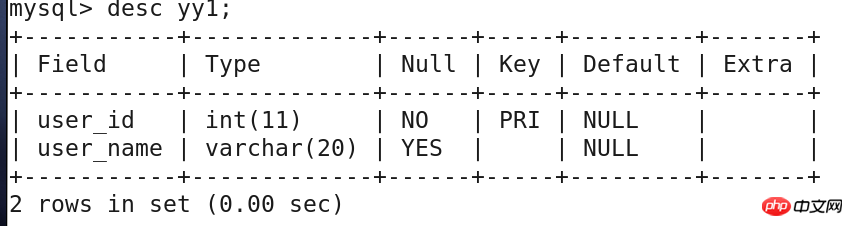
create table yy2(
user_id int primary key not null,
old int(5),
constraint y_fk foreign key(user_id)
references yy1(user_id)on delete cascade on update cascade);
insert into yy1 values('110','zhangsan');
insert into yy2 values('110','30');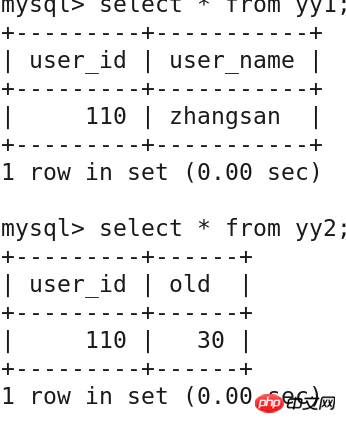
update yy1 set user_id='120' where user_name='zhangsan';
查询验证
select * from yy2;
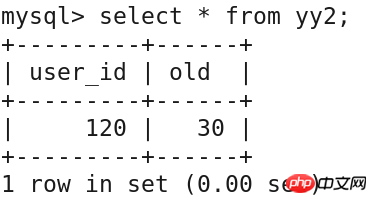
delete from yy1 where user_id='120';
查询验证
select * from yy2;

语法:属性名数据类型 NOT NULL
举例: create table C(
user_id int NOT NULL);
唯一性指的就是所有记录中该字段。不能重复出现。
语法:属性名数据类型 unique
举例: root@zytest 15:43>create table D(
->user_id int unique);
root@zytest 15:44>show create table D;
Auto_increment 是Mysql数据库中特殊的约束条件,它的作用是向表中插入数据时自动生成唯一的ID,一个表只能有一个字段使用 auto_increment 约束,必须是唯一的;
语法:属性名数据类型 auto_increment,默认该字段的值从1开始自增。
举例:
create table F( user_id int primary key auto_increment);
root@zytest 15:56>insert into F values();插入一条空的信息
Query OK, 1 row affected, 1 warning (0.00 sec)
root@zytest 15:56>select * from F;值自动从1开始自增
+---------+
| user_id |
+---------+
| 1 |
+---------+
1 row in set (0.01 sec)
在创建表时,可以指定表中的字段的默认值,如果插入一条新的纪录时,没有给这个字段赋值,那么数据库会自动的给这个字段插入一个默认 值,字段的默认值用default来设置。
语法: 属性名数据类型 default 默认值
举例: root@zytest 16:05>create table G(
user_id int primary key auto_increment,
user_name varchar(20) default 'zero');
root@zytest 16:05>insert into G values('','');
DESCRIBE可以查看那表的基本定义,包括、字段名称,字段的数据类型,是否为主键以及默认值等。。
(1)语法:describe 表名;可以缩写为desc
(2) show create table查询表详细的结构语句,
1>修改表名
语法:alter table 旧表名 rename 新表名;
举例; root@zytest 16:11>alter table A rename zyA;
Query OK, 0 rows affected (0.02 sec)
语法:alter table 表名 modify 属性名 数据类型;
举例; root@zytest 16:15>alter table A modify user_name double;
Query OK, 0 rows affected (0.18 sec)
语法: alter table 表名 change 旧属性名 新属性名 新数据类型; root@zytest 16:15>alter table A change user_name user_zyname float;
Query OK, 0 rows affected (0.10 sec) alter table 表名 ADD 属性名1 数据类型 [完整性约束条件] [FIRST |AFTER 属性名2]
root@zytest 16:18>alter table A add phone varchar(20);
Query OK, 0 rows affected (0.13 sec)root@zytest 16:42>alter table A add age int(4) not null;
Query OK, 0 rows affected (0.13 sec)root@zytest 16:45>alter table tt add num int(8) primary key first;
Query OK, 1 row affected (0.12 sec)
Records: 1 Duplicates: 0 Warnings: 0 root@zytest 16:46>alter table A add address varchar(30) not null after phone;
Query OK, 0 rows affected (0.10 sec)
Records: 0 Duplicates: 0 Warnings: 0
(1) 默认ADD 增加字段是在最后面增加
(2) 如果想在表的最前端增加字段用first关键字
(3) 如果想在某一个字段后面增加的新的字段,使用after关键字
5>删除一个字段
alter table 表名DROP 属性名;
举例: 删除A 表的age字段 root@zytest 16:51>alter table A drop age;
Query OK, 0 rows affected (0.11 sec)
Records: 0 Duplicates: 0 Warnings: 0 alter table表名 engine=存储引擎
alter table A engine=MyISAM; alter table 表名drop foreign key 外键别名;
alter table yy2 drop foreign key y_fk;
4》删除表的方法
1>删除没有被关联的普通表
drop table 表名;
2>删除被其它表关联的父表
在数据库中某些表之间建立了一些关联关系。一些成为了父表,被其子表关联,要删除这些父表,就不是那么简单了。删除方法,先删除所关联的 子表的外键,在删除主表。
以上がMysqlに関連する操作は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 PHPのビッグデータ構造処理スキル
May 08, 2024 am 10:24 AM
PHPのビッグデータ構造処理スキル
May 08, 2024 am 10:24 AM
ビッグ データ構造の処理スキル: チャンキング: データ セットを分割してチャンクに処理し、メモリ消費を削減します。ジェネレーター: データ セット全体をロードせずにデータ項目を 1 つずつ生成します。無制限のデータ セットに適しています。ストリーミング: ファイルやクエリ結果を 1 行ずつ読み取ります。大きなファイルやリモート データに適しています。外部ストレージ: 非常に大規模なデータ セットの場合は、データをデータベースまたは NoSQL に保存します。
 PHP で MySQL のバックアップと復元を使用するにはどうすればよいですか?
Jun 03, 2024 pm 12:19 PM
PHP で MySQL のバックアップと復元を使用するにはどうすればよいですか?
Jun 03, 2024 pm 12:19 PM
PHP で MySQL データベースをバックアップおよび復元するには、次の手順を実行します。 データベースをバックアップします。 mysqldump コマンドを使用して、データベースを SQL ファイルにダンプします。データベースの復元: mysql コマンドを使用して、SQL ファイルからデータベースを復元します。
 PHP で MySQL クエリのパフォーマンスを最適化するにはどうすればよいですか?
Jun 03, 2024 pm 08:11 PM
PHP で MySQL クエリのパフォーマンスを最適化するにはどうすればよいですか?
Jun 03, 2024 pm 08:11 PM
MySQL クエリのパフォーマンスは、検索時間を線形の複雑さから対数の複雑さまで短縮するインデックスを構築することで最適化できます。 PreparedStatement を使用して SQL インジェクションを防止し、クエリのパフォーマンスを向上させます。クエリ結果を制限し、サーバーによって処理されるデータ量を削減します。適切な結合タイプの使用、インデックスの作成、サブクエリの使用の検討など、結合クエリを最適化します。クエリを分析してボトルネックを特定し、キャッシュを使用してデータベースの負荷を軽減し、オーバーヘッドを最小限に抑えます。
 PHP を使用して MySQL テーブルにデータを挿入するにはどうすればよいですか?
Jun 02, 2024 pm 02:26 PM
PHP を使用して MySQL テーブルにデータを挿入するにはどうすればよいですか?
Jun 02, 2024 pm 02:26 PM
MySQLテーブルにデータを挿入するにはどうすればよいですか?データベースに接続する: mysqli を使用してデータベースへの接続を確立します。 SQL クエリを準備します。挿入する列と値を指定する INSERT ステートメントを作成します。クエリの実行: query() メソッドを使用して挿入クエリを実行します。成功すると、確認メッセージが出力されます。
 PHP で MySQL ストアド プロシージャを使用するにはどうすればよいですか?
Jun 02, 2024 pm 02:13 PM
PHP で MySQL ストアド プロシージャを使用するにはどうすればよいですか?
Jun 02, 2024 pm 02:13 PM
PHP で MySQL ストアド プロシージャを使用するには: PDO または MySQLi 拡張機能を使用して、MySQL データベースに接続します。ストアド プロシージャを呼び出すステートメントを準備します。ストアド プロシージャを実行します。結果セットを処理します (ストアド プロシージャが結果を返す場合)。データベース接続を閉じます。
 PHP を使用して MySQL テーブルを作成するにはどうすればよいですか?
Jun 04, 2024 pm 01:57 PM
PHP を使用して MySQL テーブルを作成するにはどうすればよいですか?
Jun 04, 2024 pm 01:57 PM
PHP を使用して MySQL テーブルを作成するには、次の手順が必要です。 データベースに接続します。データベースが存在しない場合は作成します。データベースを選択します。テーブルを作成します。クエリを実行します。接続を閉じます。
 MySQL 8.4 で mysql_native_password がロードされていないエラーを修正する方法
Dec 09, 2024 am 11:42 AM
MySQL 8.4 で mysql_native_password がロードされていないエラーを修正する方法
Dec 09, 2024 am 11:42 AM
MySQL 8.4 (2024 年時点の最新の LTS リリース) で導入された主な変更の 1 つは、「MySQL Native Password」プラグインがデフォルトで有効ではなくなったことです。さらに、MySQL 9.0 ではこのプラグインが完全に削除されています。 この変更は PHP および他のアプリに影響します
 Oracleデータベースとmysqlの違い
May 10, 2024 am 01:54 AM
Oracleデータベースとmysqlの違い
May 10, 2024 am 01:54 AM
Oracle データベースと MySQL はどちらもリレーショナル モデルに基づいたデータベースですが、Oracle は互換性、スケーラビリティ、データ型、セキュリティの点で優れており、MySQL は速度と柔軟性に重点を置いており、小規模から中規模のデータ セットに適しています。 ① Oracle は幅広いデータ型を提供し、② 高度なセキュリティ機能を提供し、③ エンタープライズレベルのアプリケーションに適しています。① MySQL は NoSQL データ型をサポートし、② セキュリティ対策が少なく、③ 小規模から中規模のアプリケーションに適しています。
