

Pythonの文字エンコーディングと関数の使い方を詳しく解説

次のエディターは、Python の文字エンコーディングと関数の基本的な使用法に関する記事をお届けします。編集者はこれがとても良いと思ったので、参考として共有します。エディターをフォローして一緒に見てみましょう
1. Python2 の文字のデコードとエンコードの問題
現在 Python2 を使用している場合は、文字エンコードの問題があることをご存知でしょう。最も簡単な例を次に示します。 Bar: Python2 では、コマンドラインで中国語を直接出力することはできません。もちろん、エラーは報告されません。理解できない文字化けが表示されるだけです。中国語を直接表示したい場合は、Python2 ファイルのヘッダーで文字エンコード形式を宣言できます。以下の図に示すように、
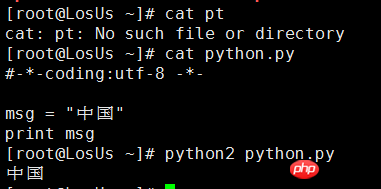
ここで #-*-coding:utf-8 -*- は、Python2 でのデコードとエンコードに使用されるエンコードを宣言するために使用されます。 :
エンコードとデコードの世界では、誰もが知っているテキストを見つける必要があります。このようにも理解できます。私は中国人で、今日本人とコミュニケーションを取っているのですが、彼の言っていることが全く理解できませんし、彼も理解できないのですが、他に方法はないのでしょうか?もしかしたら、国際言語である英語が必要かもしれません。このようにして、さまざまな国の人々がコミュニケーションをとることができます(ただし、0-0 で大丈夫かどうかはわかっていますが)。エンコードでも同様です。gbk も utf-8 も相手の形式が何を意味するかはわかりません。したがって、gbk を使用して utf-8 のエンコーディングを理解したい場合は、utf-8 を Unicode にデコードする必要があり、Unicode は gkb を認識します。ここで、Python2 で Unicode を gbk
#-*- coding:utf-8 -*- msg = "中国" print msg #解码在编码的过程,encoding是申明用申明这段代码是什么编码 gbk_str = msg.decode(encoding='utf-8').encode(encoding='gbk') print gbk_str #其实两种输出的结果是一样的
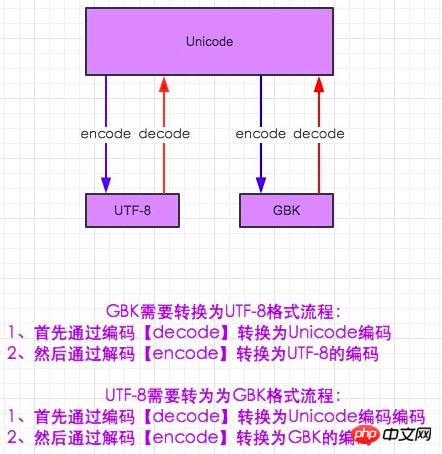 にエンコードする必要があります。デフォルトでは、IDE でコードを解釈するために gbk が使用されるため、Python コマンド ラインに中国語を直接入力することはできないため、#-*-coding:utf-8 -*- を使用してヘッダーを宣言します。次のコードを何語で説明できますか?注意深い人は問題を発見したはずです。ステートメントのヘッダーでは次の単語の説明にのみ utf-8 が使用されていますが、コマンド ラインではエラーが報告されていないにもかかわらず、ここで直接出力されるのはなぜでしょうか。すべて、DOS コマンド行でのデフォルトのサポートは gbk 形式の文字コードですか?ここには別の概念が関係しています。 Python がメモリ インタプリタに入ると、ファイルがメモリにロードされた後、デフォルトで Unicode が使用され、Unicode は外部コードであるため、当然 utf-8 エンコードまたは gbk エンコードに変換できます。 。 Gu で中国語が表示できるようになりました。
にエンコードする必要があります。デフォルトでは、IDE でコードを解釈するために gbk が使用されるため、Python コマンド ラインに中国語を直接入力することはできないため、#-*-coding:utf-8 -*- を使用してヘッダーを宣言します。次のコードを何語で説明できますか?注意深い人は問題を発見したはずです。ステートメントのヘッダーでは次の単語の説明にのみ utf-8 が使用されていますが、コマンド ラインではエラーが報告されていないにもかかわらず、ここで直接出力されるのはなぜでしょうか。すべて、DOS コマンド行でのデフォルトのサポートは gbk 形式の文字コードですか?ここには別の概念が関係しています。 Python がメモリ インタプリタに入ると、ファイルがメモリにロードされた後、デフォルトで Unicode が使用され、Unicode は外部コードであるため、当然 utf-8 エンコードまたは gbk エンコードに変換できます。 。 Gu で中国語が表示できるようになりました。 追記: ここで結論に達します:
Python2 ではデコード操作が必要ですが、メモリが Unicode であるためエンコードは必要ありません
1.2、Python3 の文字エンコードの問題:
まあ、他にも何が言えるでしょうか? Python3 はデフォルトで utf-8 を使用してコードを解釈します。つまり、行の先頭には #-*-coding:utf-8 -*- (GBM) が付いているため、デコードの問題はありません。ただし、utf-8 の文字エンコーディング形式を gbk にエンコードする場合について、ここで言及しておきます (実際、将来忘れてしまうのではないかと心配しています、ふふ)。ここにはバイト形式のものが出力されます。バイトとは一体何ですか?ここで簡単にお話しさせてください。実際、これは ASCII コード内のこの文字の対応する位置です。信じられない方は、コードのスクリーンショットを見てみましょう:
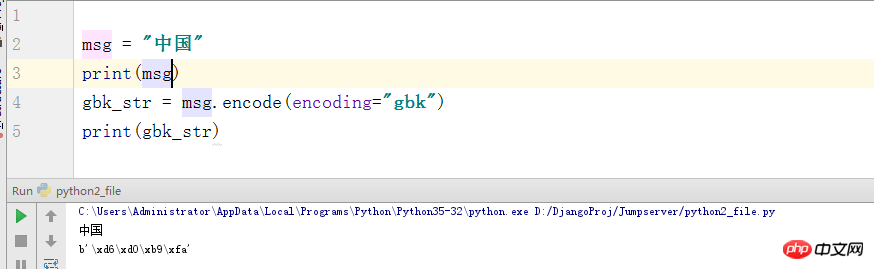
この写真では、中国に関する理解できない鳥のテキストが大量に拡散されていることがわかります。ただし、英語は表示されたままです。しかし、リストをインターセプトすると、最後のビット c の出力が 99 であることがわかります。実際、ここでの出力は ASCII の c に対応する位置で、3 バイトは漢字であるため、6 つの段落が表示されます。鳥のテキストについては、あまり説明する必要はありません。
追記: 誰もが覚えておくべきことの 1 つは、Python2 の str は Python3 のバイト形式であり、Python2 の str は実際には Unicode です
2. Python3 のファイル操作の補足
2.1。 "+" の操作: ここでは 3 つ説明しますが、実際にはこれらはほとんど役に立ちません。単なる知識ポイントです
r+: 読み取り可能、追加可能です w+: ソース ファイルをクリアしてから、 write new contenta+: 追加、読み取り可能
f = open('lyrics','r+',encoding='utf-8') #这里的lyrics是文件名字
f.read() #我先读取
f.write("Leon Have Dream") #在后面追加
f.close()r+: 最初に f.read() 、次に f.write() の場合、ファイルの最後に追加されます。 write(direct) は、ファイルの先頭の内容を () の内容に直接置き換えます
f = open('lyricsback','w+',encoding='utf-8')
f.read()
f.write("Leon Have Dream")
f.read()
f.close()f = open('lyricsback','a+',encoding='utf-8')
f.read()
f.write("Leon Have A Draem")
f.read()
f.close()a+: 実際、読み取り可能なコンテンツを追加するという点で r+ に非常に似ています。終わり
PS:这里的补充一下,为什么在使用r+的时候先执行f.read()再执行f.write()就会在文件的结尾追加和直接使用f.write()直接就替换文件最前边的内容呢?这是因为Python在读文件的时候自己维护这一个“指针”,如果我们使用f.read()就相当于读完了这个文件,这时候指针也就会在最后面了。下面我在补充“f”这个对象的几个用法来证明Python文件指针。
f = open('lyricsback','r+' ,encoding='utf-8')
print(f.tell()) #this number is 0
f.seek(12) # 将指针向后面移动几个字节,一个汉字是三个字节
print(f.tell()) # this is seek number
f.write("Love Girl") #这里就从seek到地方替换
print(f.tell()) # tell()用法就是文件的指针位置
f.close()2.2、加b的方式对文件进行操作
rb:将文件以二进制的方式从硬盘中读取出来,这里得记住在open()函数中不要加encoding= 这个参数因为二进制不存在编码上的问题
wb:将文件以二进制的方式写入内容,不过在f.write()中加上encode="utf-8",意思就是申明编码的格式,并且会清楚原来文件内容
ab:只能以二进制方式追加。
三、函数
什么是函数?函数可以简单理解一段命令的集合。为什么需要用函数?这里有一个非常简单的原因,比如说你需要对一段代码反复进行操作,这里你当然可以一直复制再粘贴,但是这样灵活性和日后的维护成本将会变大。
#比方说现在需要写一个报警(调用接口)的程序,这里就用监控做比喻 if cpu > 80%: 连接邮箱服务器 发送消息 关闭连接 if memery > 80%: 连接邮箱服务器 发送消息 关闭连接 if disk > 80% 连接邮箱服务器 发送消息 关闭连接 #通过写这样的一个程序我们发现我们一直在重复调用发送邮箱的这一套接口。这样我们是否能想出一个办法解决这样的重复操作呢?请看下一个版本 发送邮件(): l连接邮箱服务器 发送连接 关闭连接 if cpu > 80% 发送邮件() if memery > 80%: 发送邮件() ....... # 这样以此类推,我们只需要挑用发送邮件的这个接口就可以节省代码的发送邮件了
通过上面的代码我们发现,我们只需要将报警的这一套流程放到一个公共的地方,等下面触发报警的条件的时候调用报警的函数,这样我们就可以省去当每次触发报警的时候我们自己在写报警的步骤了。但是函数是怎么定义呢?又有什么语法和定义呢?请看下面的一段代码,其中代码输出的是“Leon Have A Dream”
def leon(): #leon是函数名字
print("Leon Have A Dream")
leon() #调用函数带参数的函数:
a = 10 b = 5 def calc(a,b): print(a ** b) c = calc(a,b) print(c)
首先上面这些代码执行完会输出两个字符,一个是10000,一个是None,为什么会这样呢?首先c是等于执行了一遍calc这个函数,所以输出10000这个数字是肯定的,但是为什么还会输出一个None呢?原来我们的“c”执行了仪表calc函数,而calc函数中没有任何的返回值,所以c == None 。
PS:函数的返回结果就是return,其中return的含义就是:把函数的执行结果返回给外面,从而让挑用函数的“对象”得到执行结果
下面我们在看与之相似的列子
a = 10 b = 5 def calc(a,b): print(a ** b) return a + b c = calc(a,b) c = calc(10,6) print(c)
首先会输出的有三个值,分别是100000,1000000,16,为什么会是这三个呢,下面用一副图来说一下

PS:
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
Python中的全局变量和局部变量

PS:函数内部是可以修改列表,字典,集合,实例(class),我们通过下面一个图来说明
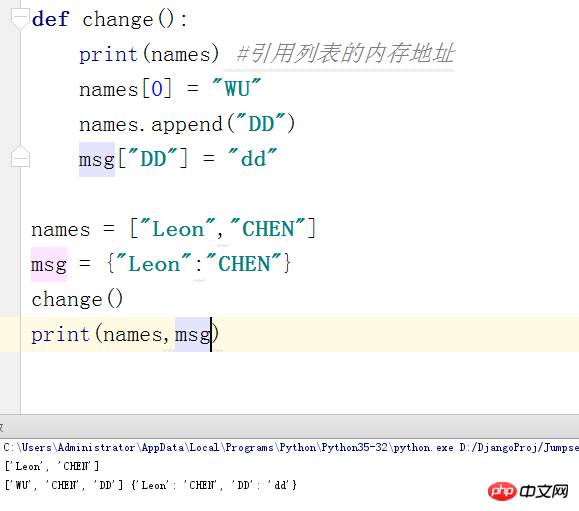
为什么列表和字典等会被添加和修改呢,原来函数内部知识引用了字典和列表的内存地址,而内存地址无法修改(可以重新开辟一块内存地址),而每个字典和列表中的每一个值都有对应的内存地址,但是记住我们函数是引用的列表或者字典本身的内存地址,所以这样打印到出来的也就会跟着改变了。
全局与局部变量
在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:
在定义局部变量的子程序内,局部变量起作用;在其它地方全局变量起作用。
位置参数:
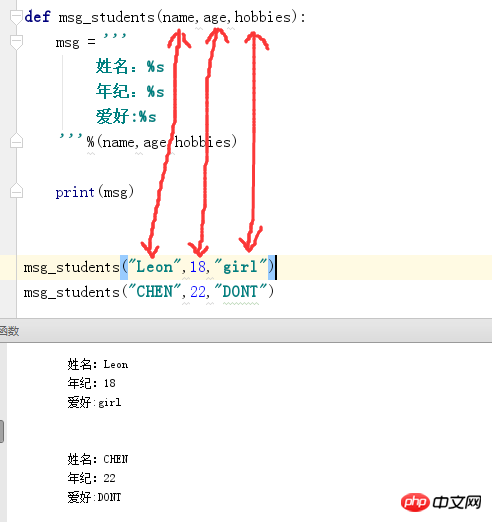
像上面这样实参和形参一一对应的上就是就是位置参数
默认参数:
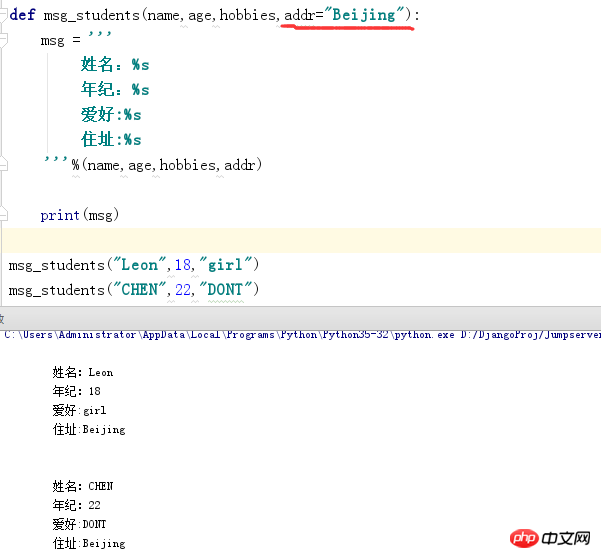
在函数将一个位置参数设置成一个默认的值的那一个变量就是默认参数,记住默认参数得在位置参数得后面
关键参数:
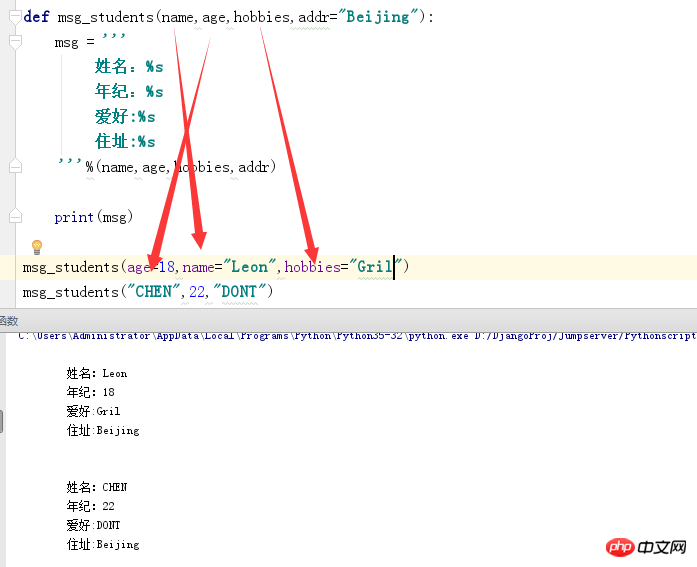
像上面这样实参和形参不一一对应,并且在调用函数的时候给参数赋值的叫做关键参数
非固定函数:
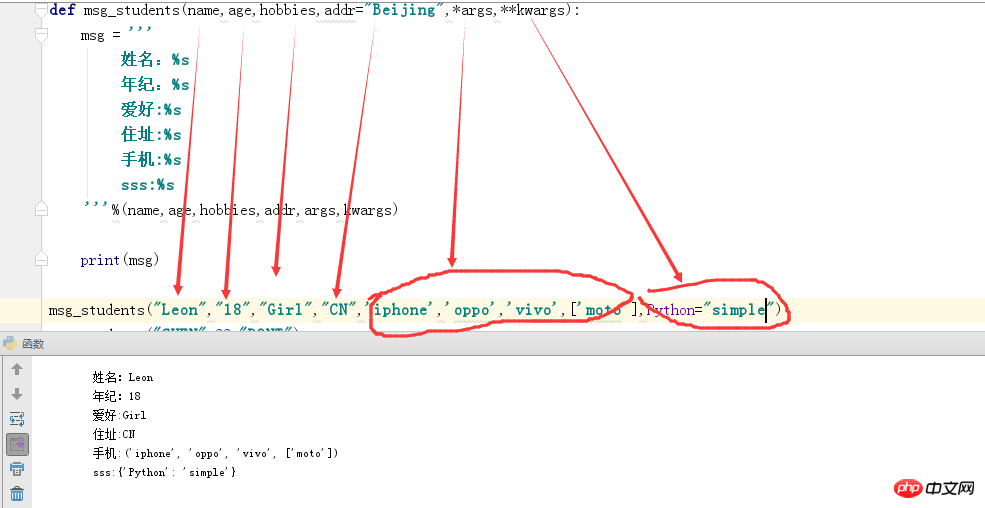
通过输出结果我们发现*args是接收多余的字符串类型的参数,而想Python="simple"(字典)类型的会传入给**kwargs,这就是非固定参数;当你不知道这个参数需要多少个参数时可以使用该函数类型
递归函数——二分查找
a = [1,2,3,4,5,7,9,10,11,12,14,15,16,17,19,21]
def calc(num,find_num):
print(num)
mid = int(len(num) / 2)
if mid == 0:
if num[mid] == find_num:
print("find it %s"%find_num)
else:
print("cannt find num")
if num[mid] == find_num:
print("find_num %s"%find_num)
elif num[mid] > find_num:
calc(num[0:mid],find_num)
elif num[mid] < find_num:
calc(num[mid+1:],find_num)
calc(a,12)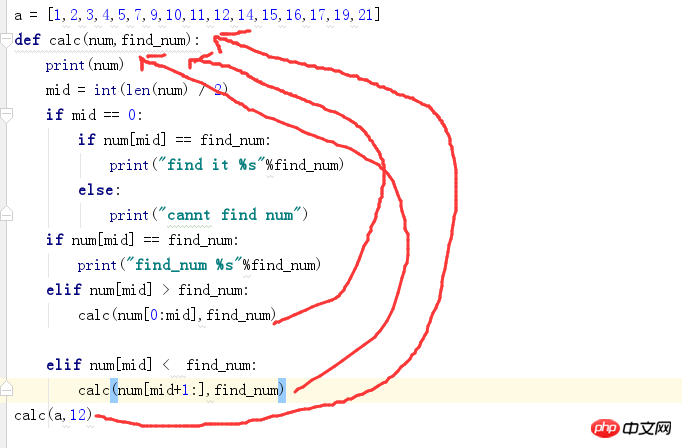
递归的特性
函数必须有明确的结束(判断)条件,也就是上图一开始的mid[0] 不能等于0,因为这样就会没有意义了
每次进入更深一层递归时,问题规模相比上次递归都应有所减少
递归函数每次向下递归一次,上次的函数占用的内存地址不会被释放,而是一直会被阻塞主,等待函数全部执行完毕后释放,所以也可以说递归是相当消耗内存空间的,对此Python有递归的深度,如果超过该深度函数将会被推出(栈溢出)
匿名函数:
calc = lambda x:x+2 # x是形参,冒号后的内容是该匿名函数执行的动作 print(calc(5)) #匿名函数意识需要通过调用来执行的 calc = lambda x,y,z:x*y*z #匿名函数可以传入多个形参,各个参数之间用逗号隔开 print(calc(2,4,6)) c = map(lambda x:x*2,[2,5,4,6]) #map方法需要 传入两个参数一个是function(函数),itrables(可迭代)的数据类型 for i in c: print(i) #三元运算 for i in map(lambda x:x**2 if x >5 else x - 1,[1,2,3,5,7,8,9]): #lambda最多支持三元运算,map是直接调用匿名函数,但是如果想打印map的内容,需要循环 print(i)
高阶函数:
def calc(x,y,f): print(f(x) + f(y)) calc(10,-10,abs)
高阶函数的特性
把一个函数的内存地址传给另外一个函数,当做参数
一个函数把另外一个函数的当做返回值返回
满足上面的这个两个特性中的一个就可以称为高阶函数,这里因为偷懒,就是直接调用了Python中的内置函数
以上がPythonの文字エンコーディングと関数の使い方を詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

 PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPとPythonには独自の利点と短所があり、選択はプロジェクトのニーズと個人的な好みに依存します。 1.PHPは、大規模なWebアプリケーションの迅速な開発とメンテナンスに適しています。 2。Pythonは、データサイエンスと機械学習の分野を支配しています。
 Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
PythonとJavaScriptには、コミュニティ、ライブラリ、リソースの観点から、独自の利点と短所があります。 1)Pythonコミュニティはフレンドリーで初心者に適していますが、フロントエンドの開発リソースはJavaScriptほど豊富ではありません。 2)Pythonはデータサイエンスおよび機械学習ライブラリで強力ですが、JavaScriptはフロントエンド開発ライブラリとフレームワークで優れています。 3)どちらも豊富な学習リソースを持っていますが、Pythonは公式文書から始めるのに適していますが、JavaScriptはMDNWebDocsにより優れています。選択は、プロジェクトのニーズと個人的な関心に基づいている必要があります。
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
VSコードはPythonの書き込みに使用でき、Pythonアプリケーションを開発するための理想的なツールになる多くの機能を提供できます。ユーザーは以下を可能にします。Python拡張機能をインストールして、コードの完了、構文の強調表示、デバッグなどの関数を取得できます。デバッガーを使用して、コードを段階的に追跡し、エラーを見つけて修正します。バージョンコントロールのためにGitを統合します。コードフォーマットツールを使用して、コードの一貫性を維持します。糸くずツールを使用して、事前に潜在的な問題を発見します。
 ターミナルVSCODEでプログラムを実行する方法
Apr 15, 2025 pm 06:42 PM
ターミナルVSCODEでプログラムを実行する方法
Apr 15, 2025 pm 06:42 PM
VSコードでは、次の手順を通じて端末でプログラムを実行できます。コードを準備し、統合端子を開き、コードディレクトリが端末作業ディレクトリと一致していることを確認します。プログラミング言語(pythonのpython your_file_name.pyなど)に従って実行コマンドを選択して、それが正常に実行されるかどうかを確認し、エラーを解決します。デバッガーを使用して、デバッグ効率を向上させます。
 VSCODE拡張機能は悪意がありますか?
Apr 15, 2025 pm 07:57 PM
VSCODE拡張機能は悪意がありますか?
Apr 15, 2025 pm 07:57 PM
VSコード拡張機能は、悪意のあるコードの隠れ、脆弱性の活用、合法的な拡張機能としての自慰行為など、悪意のあるリスクを引き起こします。悪意のある拡張機能を識別する方法には、パブリッシャーのチェック、コメントの読み取り、コードのチェック、およびインストールに注意してください。セキュリティ対策には、セキュリティ認識、良好な習慣、定期的な更新、ウイルス対策ソフトウェアも含まれます。
 Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Pythonは、自動化、スクリプト、およびタスク管理に優れています。 1)自動化:OSやShutilなどの標準ライブラリを介してファイルバックアップが実現されます。 2)スクリプトの書き込み:Psutilライブラリを使用してシステムリソースを監視します。 3)タスク管理:スケジュールライブラリを使用してタスクをスケジュールします。 Pythonの使いやすさと豊富なライブラリサポートにより、これらの分野で優先ツールになります。
 Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
VSコードはWindows 8で実行できますが、エクスペリエンスは大きくない場合があります。まず、システムが最新のパッチに更新されていることを確認してから、システムアーキテクチャに一致するVSコードインストールパッケージをダウンロードして、プロンプトとしてインストールします。インストール後、一部の拡張機能はWindows 8と互換性があり、代替拡張機能を探すか、仮想マシンで新しいWindowsシステムを使用する必要があることに注意してください。必要な拡張機能をインストールして、適切に動作するかどうかを確認します。 Windows 8ではVSコードは実行可能ですが、開発エクスペリエンスとセキュリティを向上させるために、新しいWindowsシステムにアップグレードすることをお勧めします。
