

以下のエディターでは、Python の高階関数と関数デコレーター (推奨) について詳しく説明します。編集者はこれがとても良いものだと思ったので、皆さんの参考として今から共有します。エディターをフォローして見てみましょう
1. 前のセクションの復習
Python 2 と Python 3 の間の文字エンコーディングの問題。初心者であっても、すでに Python プロジェクトに精通していても、コーディングを行います。間違い。ここでPython3とPython2の違いを簡単にまとめておきます。
まず、Python3-->コードファイルはすべてutf-8で解釈されます。コードとファイルがメモリに読み込まれると、Unicode になります。これが、Python がエンコードするだけでデコードしない理由です。メモリ内の文字エンコーディングは Unicode に変更され、Unicode は「変換」できるユニバーサル コードであるためです。形式エンコーディング形式。 Python3 では、str と bytes の 2 つの形式があり、bytes をバイナリ表現として使用できます。
Python2 はシステムのデフォルトの文字エンコーディングを使用してコードを解釈するため、コードを解釈するために utf-8 を使用したい場合はヘッダーでそれを宣言する必要があり、Python2 にはデコードとエンコードがありますが、デコード アクションは次のとおりです。 Python コードがメモリにロードされるとき、それは Python3 と同じ Unicode であるため、エンコード アクションは無視できます。Python2 では str と bytes が同じ意味を持つことに注意する必要があります。 Python2 の str は Python3 のバイト形式であり、Python3 の str は実際には Unicode です。
関数ベース (ここでは再帰関数で二分探索を使用しています)
関数を使用する理由: プログラムはmodule
定義された関数には 3 つの形式があります:
- パラメーターのない関数
- パラメーター化された関数
- 空の関数
PS: 関数に複数の戻り値がある場合、返されるデータ形式はタプルです
- 関数がパラメータを渡すときにパラメータのデータ形式を制限する方法。
def leon(x:int,y:int)->int:
pass
ここで、x と y はここで指定され、int 型である必要があります。 " -> " は、関数の戻り値も int である必要があることを意味しますType
print(yan.__annotations__): 仮パラメータの限定されたデータ形式と戻り値の形式を表示
a = [1,2,3,4,5,7,9,10,11,12,14,15,16,17,19,21] #形参中的num
def calc(num,find_num):
print(num)
mid = int(len(num) / 2) #中间数的下标
if mid == 0: #递归函数非常重要的判断条件
if num[mid] == find_num:
print("find it %s"%find_num)
else:
print("cannt find num")
if num[mid] == find_num: #直接找到不用递归,结束函数
print("find_num %s"%find_num)
elif num[mid] > find_num: #find_num应该在左边,向下递归
calc(num[0:mid],find_num)
elif num[mid] < find_num: #find_num应该在右边,向下递归
calc(num[mid+1:],find_num)
calc(a,12)匿名関数
c = lambda x:x+1 #x就是形参,c就是这个匿名函数的对象 print(c(22))
高階関数 - 特徴
1.関数のメモリを置く アドレスをパラメータとして別の関数に渡す
2. 関数は戻り値として別の関数を返す
関数は最初のClassオブジェクトです 関数を割り当てることができます
はパラメータとして使用できます は戻り値として使用できます はコンテナ型の要素として使用できますdef calc(a,b,c): print(c(a) + c(b)) calc(-5,10,abs) #引用上一节的实例,将-5和10绝对值相加
3 . クロージャー機能
1.クロージャーバッグとは何ですか?公式 Web サイトのコンセプトを見て比較してみましょう (これは私が公式 Web サイトで見つけたものではありませんが、それは問題ではありません。どうせ理解できないでしょう): Closure は Lexical Closure の略語です。 . 自由変数を参照する関数。参照された自由変数は、関数が作成された環境を離れた後も関数とともに残ります。したがって、クロージャは、関数とそれに関連する参照環境で構成されるエンティティです。
混乱していますか?存在しない。以下で簡単に説明しますが、クロージャがデコレータの焦点であることが 1 つあります。クロージャをよく理解していないと、デコレータを学習してもすぐに忘れてしまいます。例を通して説明しましょう#函数可以被赋值
def leon():
print("in the leon")
l = leon
l()
#函数可以被当做参数
def yan(x): #这里x形参,其实就是我们调用实参的函数名
x() #运行函数
y = yan(leon)
#函数当做返回值
def jian(x): 和上面一样这这也必须传入一个函数
return x
j = jian(leon) #这里需要注意一点就是这里的意思是运行jian这个函数而这个函数返回的是x 也就是leon这个函数的内存地址,也就是说这时候leon这个函数并没有被执行
j() #运行 leon函数
#可以做为容器类型的元素
leon_dict = {"leon":leon}
leon_dict["leon"]() #这样也可以运行leon这个函数
追記: ここでは、コードが上から下に実行されるとき、関数が呼び出されない場合、関数内のコードは特別な変数として扱うことができます。実行されません。上記の例では、get 関数を実行すると、wapper 関数のメモリアドレスが返されますが、この時点では wapper 関数は実行されていません。つまり、この時点では g() によって返されたステータスが返されます。は実際には wapper です。つまり、 g を実行するだけで済みます。これは、wapper でコードを実行するのと同じです。
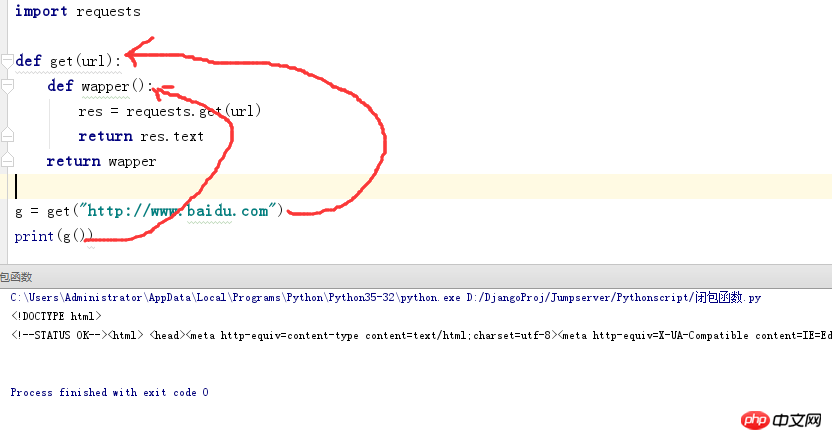
入れ子呼び出しは、実際には、1 つの関数内で別の関数を呼び出した結果であり、非常に単純なコードを見てみましょう。そして見てください。
import requests #首先导入一个模块,这个可以不用记
def get(url): #定义一个get函数里面需要传一个url的位置参数
def wapper(): #在定义一个wapper函数
res = requests.get(url) #这一步就是打开一个网页
return res.text #将网页以文字的形式返回
return wapper #返回最里层的wapper函数
g = get("http://www.baidu.com") #调用:首先因为作用域的原因,我们无法访问到里层的wapper函数,所以我们直接调用get函数这里返回了一个wapper函数
print(g()) # 然后我在调用g(get函数)的对象,这样是不是就访问到里层的wapper函数呢上記のコードを使用して、思い出を作ります。ネストされた呼び出しはどのような場合に使用されますか?明らかに、別の関数の実行結果 (return の y または x) を必要とするのは関数 (calc4) です。
以下のコードを例に挙げます。ソースコードを変更せずにコードの実行時間を計算する方法
#嵌套调用,在一个函数中调用另一个函数的功能 #calc这个函数就是在对比两个数字的大小 def calc2(x,y): if x >y : return x else: return y #我靠老板非常变态,然你直接计算四个数字的大小,擦。 def calc4(a,b,c,d): res1 = calc2(a,b) #res1的值,这里不就是calc2这个函数比较时最大的哪一个吗。 res2 = calc2(res1,c) res3 = calc2(res2,d) return res3
def geturl(url): response = requests.get(url) print(response.status_code) geturl(http://www.baidu.com)
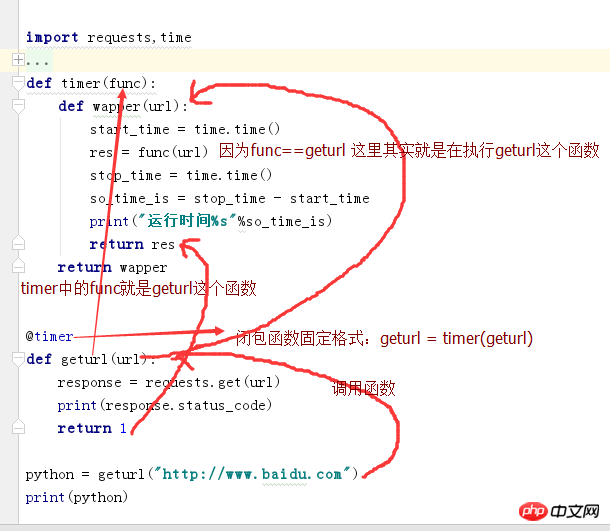
装饰器必备:
@timer就是装饰器,意思是装饰它下面的函数,而装饰器和被装饰的都是一个函数。
timer(装饰器函数),首先它会有一个位置参数(func)名字随意,但是必须并且只能是一个位置参数
func参数就是被装饰的geturl这个函数
为什么func是geturl这个函数呢-->上面写了一个装饰器功能:geturl=timer(geturl),我们看到这里的timer中传入的其实就是func函数所以func = geturl(被装饰的函数)
分析geturl=timer(geturl),首先我们可以得知timer这是一个闭包函数,当我们执行这个闭包函数,会把里层的函数(wapper)返回,也就是说timer(geturl)其实就是返回的wapper,所以就可以这样理解了geturl==wapper,所以当我们运行geturl的时候就相当于在执行wapper()这样的一个操作;如果这里实在记不住,就这样。咱上面不是有一个闭包函数吗?你就把geturl=timer(geturl)中的geturl(执行函数的返回结果)当做上面g(函数调用的返回结果),然后在分别再执行了下"g"或者"geturl”这个对象。
如果被装饰者有位置参数的话,我们需要在wapper函数中加上对应的位置参数用来接收,如果长度是不固定的话还可以用*args和**kwargs
六、有参装饰器
听着名字顾名思义,就是在装饰器中还有位置参数。
#一个low得不能再low得验证脚本,如果是显示环境中所有数据必须是由数据库或者一个静态文件提供,并且登录成功时,需要保存用户的一个状态
def auth(auth_type): #有参装饰器名称
def auth_deco(func): #定义第二层函数名称
def wrapper(*args,**kwargs): #最里层函数,主要实现认证功能
if auth_type == "file":
username = input("username>>:").strip()
password = input("username>>").strip()
if username == "leon" and password == "loveleon":
res = func(*args,**kwargs)
return res
elif auth_type == "mysql_auth":
print("mysql_auth...")
return func(*args,**kwargs)
return wrapper #第二层返回的是wrapper函数,其实就是home
return auth_deco #第一层返回的结果等于第二层函数的名称
@auth('file')
def home():
print("welcome")
home() #执行home-->wrapper有参函数必备知识:
套路,通过上面无参装饰器,我们得出了geturl=timer(geturl)这个等式。回到有参装饰器,我们又会有什么样子的等式呢?首先@auth("file")是一个装饰器也就是一个函数,所以我们定义了一个auth(auth_type)这个函数,而这个函数返回的是什么呢?没有错就是第二层函数;到了这里我们就会发现@auth("file")其实就是@auth_deco,现在我们知道了现在装饰器其实就是auth_deco,那剩下的还不知道怎么写吗?
整理公式,auth('file')-----------(return)> auth_deco----->@auth_deco ->home=auth_deco(home)
如果记不住?如果实在是记不住,其实就可以这样理解,有参装饰器无非就是在无参装饰器上面加了一层(三层),然后在第一层返回了第二层的函数,而到了第二层就和我们普通用的装饰器是一毛一样了
七、模块导入
import ,创建一个leonyan.py的模块文件,等待被导入
a = 10
b = 20
c = 30
def read1():
print("in the read1")
def read2():
print("in the read2")导入leonyan.py文件(调用模块文件和模块文件在同一目录下)
import leonyan #Python IDE这行会爆红,但是不用管 leonyan.read1() #执行leonyan这个包中的read1函数 leonyan.read2() #执行leonyan这个包中read2函数 print(leonyan.a + leonyan.b + leonyan.c ) #输出60
总结:在Python中包的导入(import ***)会干三个事情:1:创建新的作用域;2:执行该作用域的顶级代码,比如你导入的那个包中有print执行后就会直接在屏幕中输出print的内容;3:得到一个模块名,绑定到该模块内的代码
在模块导入的时候给模块起别名
import leonyan as ly import pandas as pd #这是一个第三方模块,以后的博客中会写到,这是一个用于做统计的
给模块起别名还是挺多的,在有些模块的官方文档中,还是比较推荐这种方法的,比如pandas的官方文档中就是起了一个pd别名,总之as就是一个模块起别名
from *** import *** from leonyan import read1 #引入直接调用 read1()
如果在调用模块的函数作用域中有相同的同名的,会将调用过来的覆盖。
在form ** import ** 中控制需要引用的变量(函数其实在未被执行的时候也是一个存放在内存中的变量)
from leonyan import read1,read2 在同一行中可以引用多个,只需要用逗号隔开就行了 print(read1) print(read2) #这里打印的就是read1和read2的内存地址 #需求我现在只需要导入read2 这时候我们就可以在leonyan这个函数中加上这么一行: __all__ = ["read2"] #这里的意思就是别的文件调用为的时候用from ** import ** 只能拿到read2 这个函数的内存地址,也就是只有read2可以被调用
把模块当做一个脚本执行
我们可以通过模块的全局变量__name__来查看模块名:
当做脚本运行:
__name__ 等于'__main__'
作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
if __name__ == '__main__':
#fib.py def fib(n): # write Fibonacci series up to n a, b = 0, 1 while b < n: print(b, end=' ') a, b = b, a+b print() def fib2(n): # return Fibonacci series up to n result = [] a, b = 0, 1 while b < n: result.append(b) a, b = b, a+b return result if __name__ == "__main__": import sys fib(int(sys.argv[1]))
代码执行 Python flb.py 100
只需要简单了解的Python模块导入搜索路径
内建(build-in) --> sys.path(sys.path是一个列表,而且第一个位置就是当前文件夹)
模块导入的重点-->包的导入
実際の開発環境では、ファイルのコードを最後まで書くことはできません。もちろん、同じフォルダー内の他のモジュールを参照することもできますが、このプロジェクトは自分だけでは書けないと思ったことはありませんか?多くの人たちの協力によって開発されました。これにより問題が発生します。異なる人が同じコンピュータを使用することは不可能であり、同じフォルダに関数を記述することもできません。また、独自のコード フォルダーもあり、全員がインターフェイスを通じて関数を呼び出します。現時点では、これらの異なるフォルダーを呼び出すという問題に直面しています。この種の問題も ** import ** から呼び出す必要があります。
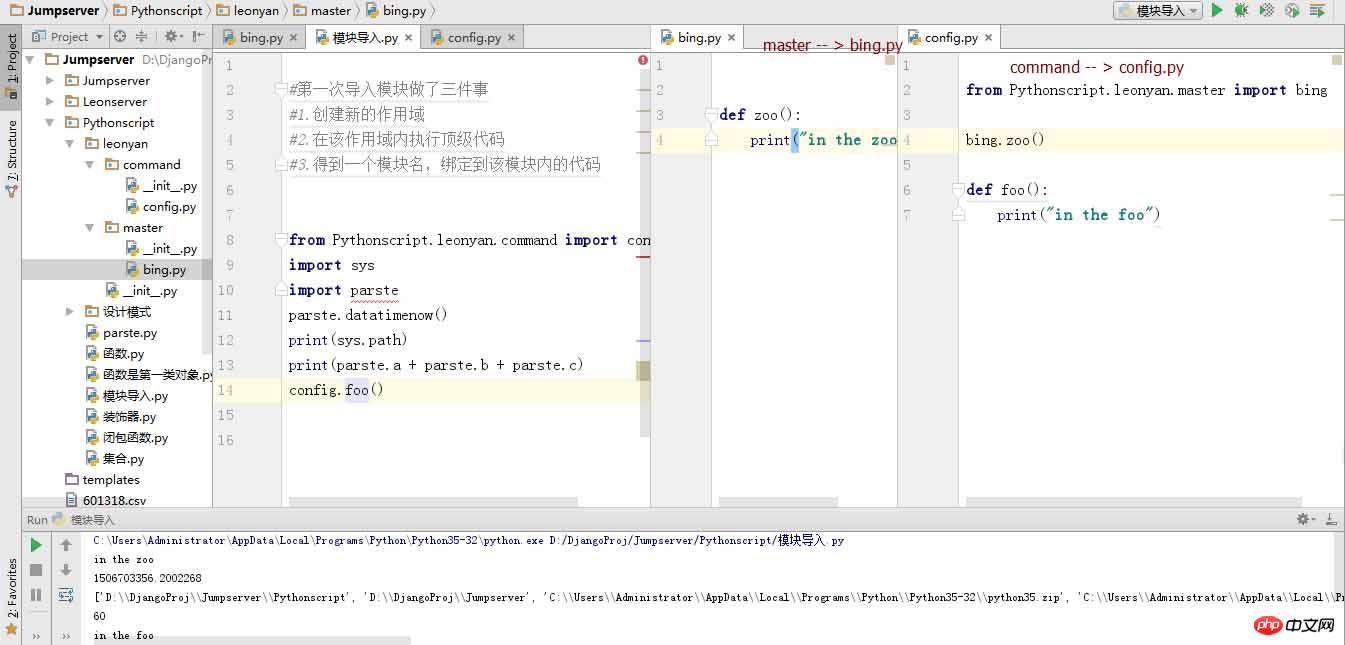
上の図では、スクリプトを実行する必要があり、インポートする必要があるパッケージがすべて揃っているため、「module import.py」フォルダーを実行します。 Pythonscript ディレクトリの下にあるので、絶対パスを使用して直接インポートし、最後に設定ファイルがインポートされるまでレイヤーごとに移動します。ここで 1 つの点に注意する必要があります。最も外側のレイヤー、sys.path リストの最初のパラメーターが実行されます。これは何を意味しますか? たとえば、私の config.py は bing.py ファイルを呼び出します。このとき、絶対パスを記述する必要があります。これは、sys.path フォルダーに見つからない、つまりインポートできないためです。
概要: パッケージのインポートは実際には非常に簡単です。覚えておく必要があるのは、Python の組み込みモジュールまたはダウンロードしたサードパーティ モジュールをインポートする場合、自分で作成した場合は import を直接使用することです。 * * import ** インポートには絶対ディレクトリを使用します。つまり、呼び出し元のスクリプトの上位ディレクトリからインポートします。これにより、モジュールのインポート エラーが報告されなくなります。
以上がPython の高階関数と関数デコレータの分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



