

この記事では主に、Java 仮想マシンの内部ロックに関する 4 つの最適化方法を紹介します。これが非常に優れていると思いますので、参考にしてください。エディターで見てみましょう
Java 6/Java 7 以降、Java 仮想マシンは内部ロックの実装にいくつかの最適化を行っています。これらの最適化には主に、ロックの省略、ロックの粗密化、バイアス ロック、および適応ロックが含まれます。これらの最適化は、Java 仮想マシン サーバー モードでのみ機能します (つまり、Java プログラムを実行する場合、これらの最適化を有効にするには、コマンド ラインで Java 仮想マシン パラメータ「-server」を指定する必要がある場合があります)。
1 ロックの削除
ロックの削除は、内部ロックの特定の実装に対して JIT コンパイラーによって行われる最適化です。
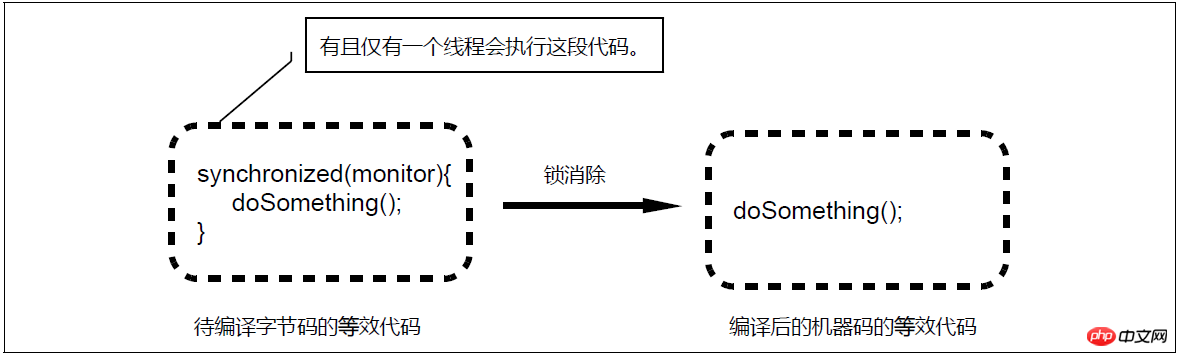
ロック省略の概略図
同期ブロックを動的にコンパイルする場合、JIT コンパイラーはエスケープ分析と呼ばれるテクノロジーを使用して、同期ブロックによって使用されるロック オブジェクトが 1 つのスレッドによってのみアクセス可能であるかどうかを判断できます。他のスレッドには公開されません。この分析により、同期ブロックで使用されるロック オブジェクトが 1 つのスレッドによってのみアクセス可能であることが確認された場合、JIT コンパイラは、同期ブロックのコンパイル時に、synchronized で表されるロックの適用と解放に対応するマシン コードを生成しません。元のクリティカル セクション コードに対応するマシン コードが生成され、動的にコンパイルされたバイトコードには、monitorenter (ロックの適用) とmonitorexit (ロックの解放) の 2 つのバイトコード命令が含まれていないように見えます。つまり、ロックの使用が排除されます。 。このコンパイラの最適化はロックの削除 (Lock Elision) と呼ばれ、特定の状況下でロックのオーバーヘッドを完全に削除できます。
Java 標準ライブラリの一部のクラス (StringBuffer など) はスレッドセーフですが、実際の使用では、これらのクラスのインスタンスを複数のスレッド間で共有しないことがよくあります。これらのクラスは、スレッド セーフを実装するときに内部ロックに依存することがよくあります。したがって、これらのクラスは、ロック除去の最適化の一般的なターゲットになります。
リスト 12-1 ロック除去用に最適化できるサンプル コード
public class LockElisionExample {
public static String toJSON(ProductInfo productInfo) {
StringBuffer sbf = new StringBuffer();
sbf.append("{\"productID\":\"").append(productInfo.productID);
sbf.append("\",\"categoryID\":\"").append(productInfo.categoryID);
sbf.append("\",\"rank\":").append(productInfo.rank);
sbf.append(",\"inventory\":").append(productInfo.inventory);
sbf.append('}');
return sbf.toString();
}
}上記の例では、JIT コンパイラーは、 toJSON メソッドをコンパイルするときに呼び出す StringBuffer.append/toString メソッドを this にインライン化します。これは、StringBuffer.append/toString メソッドのメソッド本体の命令を toJSON メソッド本体にコピーすることと同じです。ここでの StringBuffer インスタンス sbf はローカル変数であり、この変数によって参照されるオブジェクトは他のスレッドには公開されません。したがって、sbf によって参照されるオブジェクトには、sbf が存在するメソッドの現在の実行スレッド (1 つのスレッド) によってのみアクセスできます。 (toJSON メソッド) が見つかりました。したがって、JIT コンパイラは、StringBuffer.append/toString メソッドのメソッド本体からコピーされた toJSON メソッド内の命令によって使用される内部ロックを削除できるようになりました。この例では、StringBuffer.append/toString メソッド自体によって使用されるロックは解放されません。これは、システム内に StringBuffer を使用する他の場所が存在する可能性があり、これらのコードが StringBuffer インスタンスを共有する可能性があるためです。
ロック除去の最適化が依存するエスケープ解析テクノロジーは、Java SE 6u23 以降デフォルトで有効になっていますが、ロック除去の最適化は Java 7 で導入されました。
上記の例からわかるように、ロック除去の最適化には JIT コンパイラーのインライン最適化も必要になる場合があります。メソッドが JIT コンパイラによってインライン化されるかどうかは、メソッドの人気と、メソッドに対応するバイトコードのサイズ (バイトコード サイズ) によって決まります。したがって、ロック削除の最適化が実装できるかどうかは、呼び出される同期メソッド (または同期ブロックを含むメソッド) がインライン化できるかどうかにも依存します。
ロック除去の最適化は、ロックのオーバーヘッドにあまり注意を払わずに、ロックを使用すべきときにロックを使用する必要があることを示します。開発者は、コードの論理レベルでロックが必要かどうかを検討する必要があります。コードの実行レベルでロックが本当に必要かどうかは、JIT コンパイラによって決定されます。ロック除去の最適化は、開発者がコードを記述するときに内部ロックを自由に使用できる (ロックが必要でない場合はロックする) ことを意味するものではありません。これは、ロック除去は javac ではなく JIT コンパイラーによって行われる最適化であり、段落コードは次の方法でのみ最適化できるためです。 JIT コンパイラーが十分な頻度で実行される場合は、JIT コンパイラーを使用します。つまり、JIT コンパイラの最適化が介入する前は、ソース コードで内部ロックが使用されている限り、このロックのオーバーヘッドが存在します。さらに、JIT コンパイラーによって実行されるインライン最適化、エスケープ分析、およびロック除去の最適化には、すべて独自のオーバーヘッドがあります。
ロックの削除の効果により、ThreadLocal を使用してスレッドセーフ オブジェクト (Random など) をスレッド固有のオブジェクトとして使用すると、ロックの競合を回避できるだけでなく、これらのオブジェクト内で使用されるロックのオーバーヘッドを完全に削除することもできます。
2 ロック粗密化
ロック粗密化 (ロック粗密化/ロック マージ) は、内部ロックの特定の実装に対して JIT コンパイラーによって行われる最適化です。
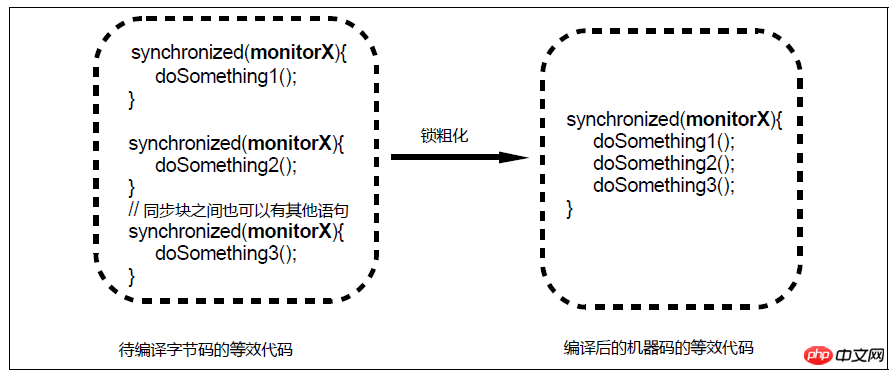
ロック粗密化の図
对于相邻的几个同步块,如果这些同步块使用的是同一个锁实例,那么JIT编译器会将这些同步块合并为一个大同步块,从而避免了一个线程反复申请、释放同一个锁所导致的开销。然而,锁粗化可能导致一个线程持续持有一个锁的时间变长,从而使得同步在该锁之上的其他线程在申请锁时的等待时间变长。例如上图中,第1个同步块结束和第2个同步块开始之间的时间间隙中,其他线程本来是有机会获得monitorX的,但是经过锁粗化之后由于临界区的长度变长,这些线程在申请monitorX时所需的等待时间也相应变长了。因此,锁粗化不会被应用到循环体内的相邻同步块。
相邻的两个同步块之间如果存在其他语句,也不一定就会阻碍JIT编译器执行锁粗化优化,这是因为JIT编译器可能在执行锁粗化优化前将这些语句挪到(即指令重排序)后一个同步块的临界区之中(当然,JIT编译器并不会将临界区内的代码挪到临界区之外)。
实际上,我们写的代码中可能很少会出现上图中那种连续的同步块。这种同一个锁实例引导的相邻同步块往往是JIT编译器编译之后形成的。
例如,在下面的例子中
清单12-2 可进行锁粗化优化的示例代码
public class LockCoarseningExample {
private final Random rnd = new Random();
public void simulate() {
int iq1 = randomIQ();
int iq2 = randomIQ();
int iq3 = randomIQ();
act(iq1, iq2, iq3);
}
private void act(int... n) {
// ...
}
// 返回随机的智商值
public int randomIQ() {
// 人类智商的标准差是15,平均值是100
return (int) Math.round(rnd.nextGaussian() * 15 + 100);
}
// ...
}simulate方法连续调用randomIQ方法来生成3个符合正态分布(高斯分布)的随机智商(IQ)。在simulate方法被执行得足够频繁的情况下,JIT编译器可能对该方法执行一系优化:首先,JIT编译器可能将randomIQ方法内联(inline)到simulate方法中,这相当于把randomIQ方法体中的指令复制到simulate方法之中。在此基础上,randomIQ方法中的rnd.nextGaussian()调用也可能被内联,这相当于把Random.nextGaussian()方法体中的指令复制到simulate方法之中。Random.nextGaussian()是一个同步方法,由于Random实例rnd可能被多个线程共享(因为simulate方法可能被多个线程执行),因此JIT编译器无法对Random.nextGaussian()方法本身执行锁消除优化,这使得被内联到simulate方法中的Random.nextGaussian()方法体相当于一个由rnd引导的同步块。经过上述优化之后,JIT编译器便会发现simulate方法中存在3个相邻的由rnd(Random实例)引导的同步块,于是锁粗化优化便“粉墨登场”了。
锁粗化默认是开启的。如果要关闭这个特性,我们可以在Java程序的启动命令行中添加虚拟机参数“-XX:-EliminateLocks”(开启则可以使用虚拟机参数“-XX:+EliminateLocks”)。
3 偏向锁
偏向锁(Biased Locking)是Java虚拟机对锁的实现所做的一种优化。这种优化基于这样的观测结果(Observation):大多数锁并没有被争用(Contented),并且这些锁在其整个生命周期内至多只会被一个线程持有。然而,Java虚拟机在实现monitorenter字节码(申请锁)和monitorexit字节码(释放锁)时需要借助一个原子操作(CAS操作),这个操作代价相对来说比较昂贵。因此,Java虚拟机会为每个对象维护一个偏好(Bias),即一个对象对应的内部锁第1次被一个线程获得,那么这个线程就会被记录为该对象的偏好线程(Biased Thread)。这个线程后续无论是再次申请该锁还是释放该锁,都无须借助原先(指未实施偏向锁优化前)昂贵的原子操作,从而减少了锁的申请与释放的开销。
然而,一个锁没有被争用并不代表仅仅只有一个线程访问该锁,当一个对象的偏好线程以外的其他线程申请该对象的内部锁时,Java虚拟机需要收回(Revoke)该对象对原偏好线程的“偏好”并重新设置该对象的偏好线程。这个偏好收回和重新分配过程的代价也是比较昂贵的,因此如果程序运行过程中存在比较多的锁争用的情况,那么这种偏好收回和重新分配的代价便会被放大。有鉴于此,偏向锁优化只适合于存在相当大一部分锁并没有被争用的系统之中。如果系统中存在大量被争用的锁而没有被争用的锁仅占极小的部分,那么我们可以考虑关闭偏向锁优化。
偏向锁优化默认是开启的。要关闭偏向锁优化,我们可以在Java程序的启动命令行中添加虚拟机参数“-XX:-UseBiasedLocking”(开启偏向锁优化可以使用虚拟机参数“-XX:+UseBiasedLocking”)。
4 适应性锁
适应性锁(Adaptive Locking,也被称为 Adaptive Spinning )是JIT编译器对内部锁实现所做的一种优化。
存在锁争用的情况下,一个线程申请一个锁的时候如果这个锁恰好被其他线程持有,那么这个线程就需要等待该锁被其持有线程释放。实现这种等待的一种保守方法——将这个线程暂停(线程的生命周期状态变为非Runnable状态)。由于暂停线程会导致上下文切换,因此对于一个具体锁实例来说,这种实现策略比较适合于系统中绝大多数线程对该锁的持有时间较长的场景,这样才能够抵消上下文切换的开销。另外一种实现方法就是采用忙等(Busy Wait)。所谓忙等相当于如下代码所示的一个循环体为空的循环语句:
// 当锁被其他线程持有时一直循环
while (lockIsHeldByOtherThread){}可见,忙等是通过反复执行空操作(什么也不做)直到所需的条件成立为止而实现等待的。这种策略的好处是不会导致上下文切换,缺点是比较耗费处理器资源——如果所需的条件在相当长时间内未能成立,那么忙等的循环就会一直被执行。因此,对于一个具体的锁实例来说,忙等策略比较适合于绝大多数线程对该锁的持有时间较短的场景,这样能够避免过多的处理器时间开销。
事实上,Java虚拟机也不是非要在上述两种实现策略之中择其一 ——它可以综合使用上述两种策略。对于一个具体的锁实例,Java虚拟机会根据其运行过程中收集到的信息来判断这个锁是属于被线程持有时间“较长”的还是“较短”的。对于被线程持有时间“较长”的锁,Java虚拟机会选用暂停等待策略;而对于被线程持有时间“较短”的锁,Java虚拟机会选用忙等等待策略。Java虚拟机也可能先采用忙等等待策略,在忙等失败的情况下再采用暂停等待策略。Java虚拟机的这种优化就被称为适应性锁(Adaptive Locking),这种优化同样也需要JIT编译器介入。
适应性锁优化可以是以具体的一个锁实例为基础的。也就是说,Java虚拟机可能对一个锁实例采用忙等等待策略,而对另外一个锁实例采用暂停等待策略。
从适应性锁优化可以看出,内部锁的使用并不一定会导致上下文切换,这就是我们说锁与上下文切换时均说锁“可能”导致上下文切换的原因。

以上がJava 仮想マシンの内部ロックを最適化する 4 つの方法の分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



