

K 平均法は、機械学習でよく使用される教師なし学習アルゴリズムです。クラスターの数を指定するだけで、データが自動的に複数のカテゴリに集約されます。クラスター内のデータの類似性は高く、異なるクラスター内のデータの類似性は低くなります。
K-MEANSアルゴリズムは、クラスター数kとn個のデータオブジェクトを含むデータベースを入力し、最小分散基準を満たすk個のクラスターを出力するアルゴリズムです。 k-means アルゴリズムは、入力量 k を受け取り、取得されたクラスターが次の条件を満たすように、n 個のデータ オブジェクトを k クラスターに分割します。同じクラスター内のオブジェクトの類似性はより高く、異なるクラスター内のオブジェクトの類似性はより小さくなります。この記事では、Python での K 平均法アルゴリズムの実装について紹介します。
中心となるアイデア
は、k 個のクラスターの分割スキームを繰り返し見つけます。これにより、これらの k 個のクラスターの平均を使用して、対応する種類のサンプルを表すときに得られる全体的な誤差が最小限に抑えられます。
k クラスターには次の特徴があります。各クラスター自体は可能な限りコンパクトであり、各クラスターは可能な限り分離されています。
k-meansアルゴリズムは最小誤差二乗和基準に基づいていますK-menasの長所と短所:
長所:
原理が簡単
速度が速い
大規模なデータセットに対して比較的優れたスケーラビリティを持っています
短所:
クラスターKの数を指定する必要がある
外れ値に敏感
初期値に敏感
K-meansのクラスタリングプロセス
クラスタリングプロセスは勾配降下法アルゴリズムに似ていますコスト関数を確立し、反復を通じてコスト関数値をどんどん小さくします
c クラスの初期中心を適切に選択します。
k 回目の反復で、任意のサンプルについて、c 中心までの距離を見つけて分類します。最短距離の中心が位置するクラスへのサンプル
mean などのメソッドを使用してクラスの中心値を更新します
すべての c クラスターの中心について、( 2) (3)、反復は終了します。それ以外の場合は反復が継続します。
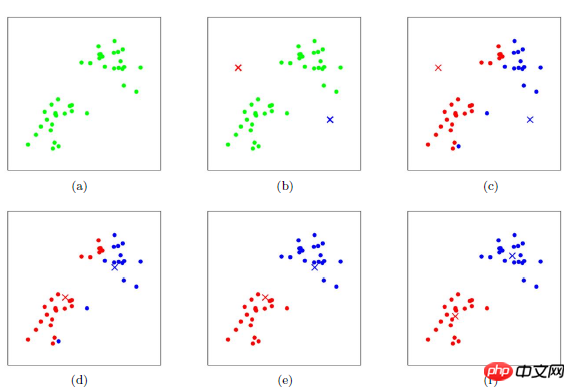
このアルゴリズムの最大の利点は、そのシンプルさと速度です。このアルゴリズムの鍵は、初期中心と距離の式の選択にあります。
K-means の例は、Python で km のパラメーターをいくつか示しています:
sklearn.cluster.KMeans( n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm='auto' ) n_clusters: 簇的个数,即你想聚成几类 init: 初始簇中心的获取方法 n_init: 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始10个质心,实现算法,然后返回最好的结果。 max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代) tol: 容忍度,即kmeans运行准则收敛的条件 precompute_distances:是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是True 会把整个距离矩阵都放到内存中,auto 会默认在数据样本大于featurs*samples 的数量大于12e6 的时候False,False 时核心实现的方法是利用Cpython 来实现的 verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值) random_state: 随机生成簇中心的状态条件。 copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。bool 在scikit-learn 很多接口中都会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python 的内存机制才会比较清楚。 n_jobs: 并行设置 algorithm: kmeans的实现算法,有:'auto', ‘full', ‘elkan', 其中 ‘full'表示用EM方式实现 虽然有很多参数,但是都已经给出了默认值。所以我们一般不需要去传入这些参数,参数的。可以根据实际需要来调用。
from sklearn.cluster import KMeans from sklearn.externals import joblib from sklearn import cluster import numpy as np # 生成10*3的矩阵 data = np.random.rand(10,3) print data # 聚类为4类 estimator=KMeans(n_clusters=4) # fit_predict表示拟合+预测,也可以分开写 res=estimator.fit_predict(data) # 预测类别标签结果 lable_pred=estimator.labels_ # 各个类别的聚类中心值 centroids=estimator.cluster_centers_ # 聚类中心均值向量的总和 inertia=estimator.inertia_ print lable_pred print centroids print inertia 代码执行结果 [0 2 1 0 2 2 0 3 2 0] [[ 0.3028348 0.25183096 0.62493622] [ 0.88481287 0.70891813 0.79463764] [ 0.66821961 0.54817207 0.30197415] [ 0.11629904 0.85684903 0.7088385 ]] 0.570794546829
50 次元
30 次元に拡張しました。

1000000 アイテム
4'13s
| 数百万のデータでは、フィッティング時間はまだ許容範囲内であり、保存効率も依然として良好であることがわかります。モデルは他の機械学習アルゴリズム モデルの保存と似ています | ||
|---|---|---|
| K 平均法クラスタリング アルゴリズムを使用して画像の主要な色を特定する | K 平均法クラスタリング アルゴリズムを使用して画像の主要な色を特定する_PHP チュートリアル | |
| K 平均法を理解する画像によるアルゴリズム |
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



