

Oracle と MySQL の高可用性ソリューションの比較分析

Oracle と MySQL の高可用性ソリューションについては、実はまとめておきたいと思っていたので、数回に分けて簡単にお話します。この比較を通じて、2 つのデータベース アーキテクチャの設計における詳細な違いについて基本的に理解できるようになります。オラクルには非常に成熟したソリューションがあります。 OOW の私の ppt から判断すると、MAA の計画は今年で 16 周年になります。この記事では主に Oracle と MySQL の高可用性ソリューションの比較分析を紹介しています。必要な方は参考にしてください。

MySQL のオープン ソースの性質により、コミュニティではさらに多くのソリューションが導入されており、私の個人的な意見では、InnoDB Cluster が将来 MySQL の標準的な高可用性ソリューションになるでしょう。
現時点では、MGR が優れていますが、MySQL Cluster ソリューション、PXC、Galera などのソリューションもあります。個人的には、やはり MHA を好みます。
そこで、この記事では、RAC と MHA について説明します。 . 基本的な比較。
オラクルのソリューションは、アリババの急速な発展期に中核となるビジネスのニーズをサポートしました。巨大に見えるのはおそらくこのようなアーキテクチャシステムです。 RAC 内部は貴族とみなされており、高価な商用ストレージ、非常に高いネットワーク帯域幅要件、多数のフロントエンド小型コンピュータ サービスと高額なライセンス料金を使用しています。非常に典型的な IOE クラシック アーキテクチャ。

リモート災害復旧を検討したい場合は、リソースの割り当てを 2 倍にし、予算を 2 倍にする必要があります。
MySQL のアーキテクチャ ソリューションは、通常の PC で十分ですが、ビジネス分割を行う場合、多くの大手インターネット企業の MySQL クラスター サイズはさらに大きくなります。いずれも数百、数千の規模になることも珍しくありません。サービス リソースが非常に多いため、ビジネス サービスへの持続可能なアクセスを確保することが技術的ソリューションの鍵となります。 MHA アーキテクチャに従う場合、MHA マネージャー ノードは基本的にクラスター全体のステータスを担当します。これは、住民に関する大小のすべてを知っている近所委員会のおばさんのようなものです。

もちろん、上記の説明は一般的すぎるため、いくつかの詳細から始めましょう。たとえば、最初にインターネットについて話しましょう。
Oracle にはネットワークに対する非常に厳しい要件があり、通常、各サーバーには少なくとも 3 つの IP、パブリック IP、プライベート IP、VIP が必要であり、少なくとも 2 つのコンピューティング ノードが必要です。
プライベート IP はノード間の相互信頼です。簡単に言えば、VIP は外部にあり、パブリック IP が配置されているネットワークのドリフト IP です。10g では、VIP は負荷に使用されます。 11g ではスキャン IP が使用され始めましたが、元の VIP はまだ保持されているため、Oracle のネットワーク構成要件は依然として非常に高いです。共有ストレージに関わらず、構築の核となるのはネットワーク構成であり、ネットワークは一般的です。
scan-IP は引き続き拡張可能で、以下の図に示すように、最大 3 つの scan-ip をサポートします

もちろん、この面でのハイライトは Oracle です。 TAF を理解する必要があります。私の著書「Oracle DBA Work Notes」では、次のように書きました。
TAF (透過的アプリケーション フェイルオーバー) は、Oracle で特に広く使用されています。 RAC のロード バランスは、10g バージョンから始まった複数の VIP アドレスのロード バランスから 11g バージョンの SCAN まで、大幅に改善されました。
フェイルオーバーの実装には、依然として特定の使用上の制限があります。たとえば、11g のデフォルトの SCAN-IP 実装には、実際にはデフォルトでフェイルオーバー オプションがありません。クエリを続行すると、セッションが切断されたため再接続する必要があるというメッセージが表示されます。クライアント TAF では、主にフェイルオーバー方法とフェイルオーバー タイプに関するいくつかの簡単な内容について説明します。
(1)フェイルオーバー方式
フェイルオーバー方式の主な考え方は、フェイルオーバー時間を交換するか、それを実現するためにリソースを交換することです。
2 つのノードがあると仮定します。セッションがノード 2 に接続されているが、ノード 2 が突然ハングアップした場合、フェイルオーバー状況をより速く処理するために、フェイルオーバー方法には事前接続と基本の 2 つのタイプがあります。 。
— 事前接続の方法は依然として多くのリソースを占有しますが、切り替えは比較的スムーズかつ高速になります。
- 基本 この方法では、フェイルオーバーが発生すると、対応するリソースが切り替わります。プロセスに多少の遅れが生じますが、リソースの消費は比較的少なくなります。
簡単に言うと、基本的な方法は障害が発生した場合にのみ判断しますが、事前接続は実際のアプリケーションから雨の日に備えるためのものであり、基本的な方法はより汎用性が高く、デフォルトのフェイルオーバー方法でもあります。
(2)フェイルオーバータイプ
フェイルオーバー タイプの実装は、より豊富で、より柔軟で、非常に強力です。このとき、制御の粒度はユーザー SQL の実行に基づいて制御できます。select と session の 2 つのタイプがあります。簡単な例で説明します。
たとえば、ノード 2 で大規模なクエリが実行されているとします。その結果、たとえば、実行中のクエリには 10,000 個のデータがありましたが、障害が発生したときに 8,000 個が見つかりました。が発生した場合、残りの 2,000 をどうするか。
最初の方法は、フェイルオーバーを完了し、残りの 2,000 レコードを返し続ける select を使用することです。これは、ユーザーには意識されません。
2 番目の方法はセッションです。つまり、直接切断して再度クエリを実行します。
10g バージョンでは、VIP 構成を使用したロードバランス + フェイルオーバーの構成は次のとおりです:
racdb= (DESCRIPTION = (ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.101)(PORT= 1521)) (ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.201)(PORT= 1521)) (LOAD_BALANCE = yes) (FAILOVER = ON) (CONNECT_DATA = (SERVER= DEDICATED) (SERVICE_NAME = racdb) (FAILOVER_MODE = (TYPE= SELECT) (METHOD= BASIC) (RETRIES = 30) (DELAY = 5)))) 如果11g的SCAN-IP也想进一步扩展Failover,同样也需要设置failover_mode和对应的类型。 RACDB = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = rac-scan)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = RACDB) ) )
この観点から見ると、Oracle のソリューションは非常に洗練されています。 MySQL のソリューションを見てみましょう。
分散ソリューションにより、MySQL はスイスナイフのように見えます。ネットワーク レベルの要件に関しては、1 つのマスターと 1 つのスレーブを適用する場合、MySQL には 4 つの IP (マスター、スレーブ) のみが必要であると言えます。 VIP、MHA_Manager (マネージャー ノードを考慮))、1 つのマスターと 2 つのスレーブは 5 です。

現時点では、MySQL はいわゆるロード バランシングをネイティブにサポートしていません。これは、ミドルウェア プロキシの使用や、一定の粒度に達した後、フロントエンド ビジネスを通じて転用できます。建築設計を通じてニーズに応えます。ロジックベースのレプリケーションは拡張が容易であるため、1 つのマスターと複数のスレーブが非常に一般的であり、遅延がゼロとは言えませんが、コストは非常に低く、ほとんどのインターネット ビジネスのニーズに適応できます。
MHA 切り替えを引き起こす条件について言えば、ネットワークの観点から見ると、次の赤い点は潜在的なリスクです。障害が発生した場合、データを保護するため、または安定したパフォーマンスを確保するためです。独自のニーズに基づいてカスタマイズできます。この観点からすると、データが失われる可能性があります。それは決して、強い整合性を備えた可逆コピーではありません。
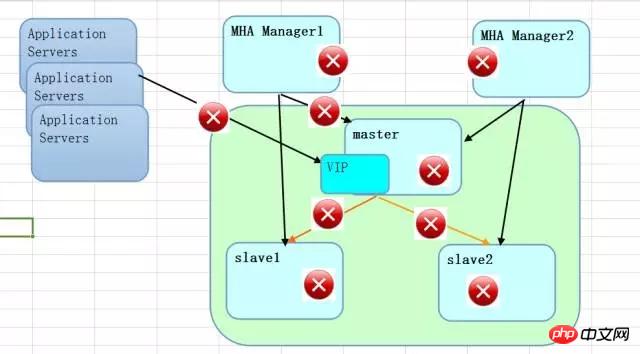
2 つのソリューション全体を見ると、RAC はストレージ レベルでの共有に加えて、ネットワーク レベルでのマルチキャストにより実際にノード間の通信コストが増加するため、ネットワークに対する大きな需要があります。がある場合、遅延は危険であり、スプリットブレインは恥ずかしいことになる可能性があります。 MySQL MHAのソリューションが配布されています。大容量環境をサポートするため、ノード間の通信コストは比較的低くなります。ただし、データ アーキテクチャの観点から見ると、複製されたデータ分散方法であるため、ストレージは共有ストレージではありませんが、ストレージのコストは RAC よりも依然として高くなります (ストレージの価格ではなく、保存されるデータの量です)。
関連する推奨事項:
OracleとMysqlはそれぞれシーケンスシーケンスを生成します
OracleとMySQLのいくつかの簡単なコマンドの比較_MySQL
Oracleとmysqlのいくつかの簡単なコマンドの比較については、[写真]_MySQLを参照してください。
以上がOracle と MySQL の高可用性ソリューションの比較分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29

 Oracleデータベースをインポートする方法
Apr 11, 2025 pm 08:06 PM
Oracleデータベースをインポートする方法
Apr 11, 2025 pm 08:06 PM
データインポート方法:1。SQLLOADERユーティリティを使用します。データファイルを準備し、制御ファイルを作成し、SQLLoaderを実行します。 2。IMP/EXPツールを使用します。データをエクスポートし、データをインポートします。ヒント:1。ビッグデータセットに推奨されるSQL*ローダー。 2。ターゲットテーブルが存在する必要があり、列定義が一致します。 3。インポート後、データの整合性を検証する必要があります。
 Oracleの表空間サイズを確認する方法
Apr 11, 2025 pm 08:15 PM
Oracleの表空間サイズを確認する方法
Apr 11, 2025 pm 08:15 PM
Oracle Tablespaceサイズを照会するには、次の手順に従ってください。クエリを実行して、TableSpace名を決定します。DBA_TABLESPACesからTableSpace_Nameを選択します。クエリを実行してテーブルスペースのサイズをクエリします:sum(bytes)をtotal_size、sum(bytes_free)asavail_space、sum(bytes) - sum(bytes_free)as sum(bytes_free)as dba_data_files from tablespace_
 Oracleでテーブルを作成する方法
Apr 11, 2025 pm 08:00 PM
Oracleでテーブルを作成する方法
Apr 11, 2025 pm 08:00 PM
Oracleテーブルの作成には、次の手順が含まれます。作成テーブルの構文を使用して、テーブル名、列名、データ型、制約、およびデフォルト値を指定します。テーブル名は簡潔で説明的である必要があり、30文字を超えてはなりません。列名は説明的でなければならず、データ型は列に保存されているデータ型を指定します。 NOT NULL制約により、列でnull値が許可されていないことが保証され、デフォルト句は列のデフォルト値を指定します。テーブルの一意の記録を識別する主要なキーの制約。外部キーの制約は、表の列が別のテーブルの主キーを指していることを指定します。主要なキー、一意の制約、デフォルト値を含むサンプルテーブル学生の作成を参照してください。
 オラクルを開けない場合はどうすればよいですか
Apr 11, 2025 pm 10:06 PM
オラクルを開けない場合はどうすればよいですか
Apr 11, 2025 pm 10:06 PM
Oracleのソリューションを開くことはできません。1。データベースサービスを開始します。 2。リスナーを開始します。 3.ポートの競合を確認します。 4.環境変数を正しく設定します。 5.ファイアウォールまたはウイルス対策ソフトウェアが接続をブロックしないことを確認してください。 6.サーバーが閉じているかどうかを確認します。 7. RMANを使用して破損したファイルを回復します。 8。TNSサービス名が正しいかどうかを確認します。 9.ネットワーク接続を確認します。 10。Oracleソフトウェアを再インストールします。
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 Oracleで文字化けのコードを解決する方法
Apr 11, 2025 pm 10:09 PM
Oracleで文字化けのコードを解決する方法
Apr 11, 2025 pm 10:09 PM
Oracle Garbledの問題は、データベース文字セットをチェックしてデータと一致するようにすることで解決できます。データベースに一致するようにクライアント文字を設定します。データを変換するか、列文字セットを変更してデータベース文字セットに一致させます。 Unicode文字セットを使用して、マルチバイト文字セットを避けます。データベースとクライアントの言語設定が正しいことを確認してください。
 Oracleのインストールをアンインストールする方法は失敗しました
Apr 11, 2025 pm 08:24 PM
Oracleのインストールをアンインストールする方法は失敗しました
Apr 11, 2025 pm 08:24 PM
Oracleインストール障害のためのアンインストールメソッド:Oracleサービスを閉じ、Oracleプログラムファイルとレジストリキーを削除し、Oracle環境変数をアンインストールし、コンピューターを再起動します。アンインストールが失敗した場合、Oracle Universal Uninstallツールを使用して手動でアンインストールできます。
 Oracleビューを暗号化する方法
Apr 11, 2025 pm 08:30 PM
Oracleビューを暗号化する方法
Apr 11, 2025 pm 08:30 PM
Oracle View暗号化により、ビュー内のデータを暗号化でき、それにより機密情報のセキュリティが強化されます。手順には以下が含まれます。1)マスター暗号化キー(MEK)の作成。 2)暗号化されたビューを作成し、暗号化されるビューとMEKを指定します。 3)暗号化されたビューにアクセスすることをユーザーに許可します。暗号化されたビューがどのように機能するか:ユーザーが暗号化されたビューを求めてクエリをするとき、OracleはMEKを使用してデータを復号化し、認定ユーザーのみが読み取り可能なデータにアクセスできるようにします。
