

現在のプログラミング言語の機能がますます成熟し、複雑になるにつれて、メモリ管理は誰でも簡単に無視されます。この記事では、JavaScript コーディングの使用時にメモリ リークによって引き起こされる問題に誰もが適切に対処できるように、JavaScript のメモリ リークとその対処方法について説明します。この記事では、JavaScript のメモリ リークに対処する方法を共有し、理論と例を組み合わせてより深く理解できるようにします。
概要
C言語などのプログラミング言語には、malloc()やfree()などの単純なメモリ管理関数があります。開発者はこれらの関数を使用して、システム メモリを明示的に割り当てたり解放したりできます。
JavaScript は、オブジェクトや文字列などが作成されるときにメモリを割り当て、使用されなくなったときにメモリを自動的に解放します。このメカニズムはガベージ コレクションと呼ばれます。この種のリソースの解放は「自動的」に見えますが、本質は混乱を招くため、JavaScript (およびその他の高級言語) の開発者はメモリ管理を気にする必要がないという誤った印象も与えます。実はこれは大きな間違いなのです。
高級言語を使用する場合でも、開発者はメモリ管理の知識を理解する必要があります。場合によっては、自動メモリ管理に問題 (ガベージ コレクタのバグや実装の制限など) が発生することがあります。開発者は、それを正しく処理するためにそれを認識しておく必要があります。
メモリのライフサイクル
どのプログラミング言語を使用しているかに関係なく、メモリのライフサイクルはほぼ同じです:

メモリのライフサイクルの各ステップで何が起こるかの概要を次に示します:
メモリの割り当て- メモリはオペレーティング システムによって割り当てられ、プログラムが使用できるようになります。単純なプログラミング言語では、このプロセスは開発者が処理する必要がある明示的な操作です。ただし、高級プログラミング言語では、システムがこれを実行します。メモリ使用量 - これは、割り当てられた変数
を使用してコードがメモリの読み書きに使用する前に、プログラムがメモリを割り当てる期間です。
メモリの解放 - 不要になったメモリを解放して、確実に空き状態にして再度使用できるようにする操作。メモリ割り当て操作と同様に、この操作には単純なプログラミング言語での明示的な操作が必要です。 記憶とは何ですか?
ハードウェア レベルでは、コンピューターのメモリは多数のフリップフロップで構成されています。各フリップフロップには多数のトランジスタが含まれており、1 ビットのデータを保存できます。個々のトリガーは一意の識別子でアドレス指定できるため、読み取りと上書きが可能です。したがって、概念的には、コンピューターのメモリ全体を、読み書きできる大きな領域の塊として考えることができます。
多くのものがメモリに保存されます:
プログラムによって使用されるすべての変数とその他のデータ。オペレーティング システム コードを含むプログラム コード。
コンパイラーとオペレーティングシステムは連携してメモリ管理のほとんどを処理しますが、本質的に何が起こっているのかを理解する必要があります。
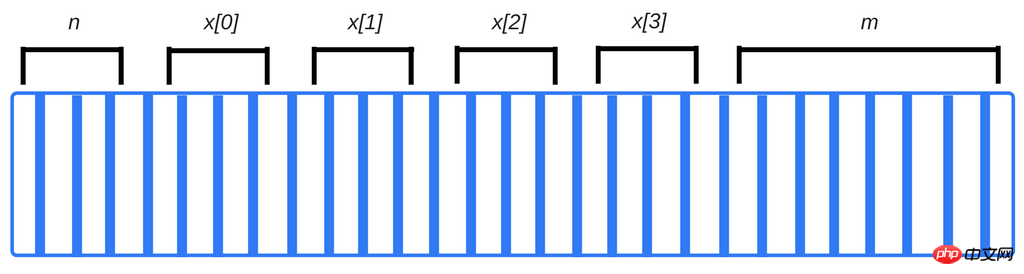
コードをコンパイルするとき、コンパイラーはプリミティブ データ型をチェックし、必要なメモリ量を事前に計算し、必要なメモリを呼び出しスタック領域内のプログラムに割り当てます。これらの変数に割り当てられたスペースはスタックスペースと呼ばれ、関数が呼び出されるにつれて、メモリが既存のメモリに追加されます。終了すると、スペースは LIFO (後入れ先出し) の順序で削除されます。たとえば、次のステートメントは次のとおりです。
int n; // 4个字节 int x [4]; // 4个元素的数组,每一个占4个字节 double m; // 8个字节
コンパイラは、オペレーティング システムと対話して、変数を格納するためにスタック上に必要なバイト数を要求するコードを挿入します。
上記の例では、コンパイラは各変数の正確なメモリ アドレスを知っています。実際、この変数 n に書き込むと、内部で「メモリ アドレス 4127963」に変換されます。
x[4] にアクセスしようとすると、m に関連付けられたデータにアクセスすることになることに注意してください。これは、配列内に存在しない要素にアクセスしているためです。実際に割り当てられた配列内の最後のデータよりも 4 バイト x[3] 多く、m ビット程度を読み取る (または上書きする) ことになる可能性があります。これは残りの部分に悪影響を及ぼします。
関数が他の関数を呼び出す場合、各関数は呼び出されたときに独自のスタック ブロックを取得します。すべてのローカル変数とプログラム カウンターを保持し、実行された場所も記録します。関数が完了すると、そのメモリ ブロックが解放され、他の目的に再び使用できるようになります。
動的割り当て
コンパイル時に変数が必要とするメモリの量がわからない場合、事態は複雑になります。次のことを実行したいとします。
int n = readInput(); //读取用户的输入 ... //用“n”个元素创建一个数组
コンパイル時に、配列に必要なメモリの量は、ユーザーが提供する入力値によって決まるため、コンパイラは知りません。
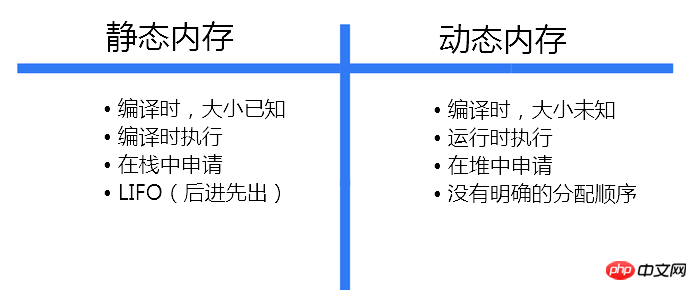
したがって、スタック上に変数用のスペースを割り当てることができません。代わりに、プログラムは実行時にオペレーティング システムに適切なスペースを明示的に要求する必要があります。このメモリはヒープ領域から割り当てられます。次の表は、静的メモリ割り当てと動的メモリ割り当ての違いをまとめたものです:
在JavaScript中分配内存
现在来解释如何在JavaScript中分配内存。
JavaScript使得开发人员免于处理内存分配的工作。
var n = 374; // allocates memory for a number
var s = 'sessionstack'; // allocates memory for a string
var o = {
a: 1,
b: null
}; // allocates memory for an object and its contained values
var a = [1, null, 'str']; // (like object) allocates memory for the
// array and its contained values
function f(a) {
return a + 3;
} // allocates a function (which is a callable object)
// function expressions also allocate an object
someElement.addEventListener('click', function() {
someElement.style.backgroundColor = 'blue';
}, false);一些函数调用也会导致对象分配:
var d = new Date(); // allocates a Date object var e = document.createElement('p'); // allocates a DOM element
方法可以分配新的值或对象:
var s1 = 'sessionstack'; var s2 = s1.substr(0, 3); // s2 is a new string // Since strings are immutable, // JavaScript may decide to not allocate memory, // but just store the [0, 3] range. var a1 = ['str1', 'str2']; var a2 = ['str3', 'str4']; var a3 = a1.concat(a2); // new array with 4 elements being // the concatenation of a1 and a2 elements
在JavaScript中使用内存
基本上在JavaScript中使用分配的内存,意味着在其中读写。
这可以通过读取或写入变量或对象属性的值,或者甚至将参数传递给函数来完成。
当内存不再需要时进行释放
大部分内存泄漏问题都是在这个阶段产生的,这个阶段最难的问题就是确定何时不再需要已分配的内存。它通常需要开发人员确定程序中的哪个部分不再需要这些内存,并将其释放。
高级语言嵌入了一个名为垃圾收集器的功能,其工作是跟踪内存分配和使用情况,以便在不再需要分配内存的情况下自动释放内存。
不幸的是,这个过程无法做到那么准确,因为像某些内存不再需要的问题是不能由算法来解决的。
大多数垃圾收集器通过收集不能被访问的内存来工作,例如指向它的变量超出范围的这种情况。然而,这种方式只能收集内存空间的近似值,因为在内存的某些位置可能仍然有指向它的变量,但它却不会被再次访问。
由于确定一些内存是否“不再需要”,是不可判定的,所以垃圾收集机制就有一定的局限性。下面将解释主要垃圾收集算法及其局限性的概念。
内存引用
垃圾收集算法所依赖的主要概念之一就是内存引用。
在内存管理情况下,如果一个对象访问变量(可以是隐含的或显式的),则称该对象引用另一个对象。例如,JavaScript对象具有对其原对象(隐式引用)及其属性值(显式引用)的引用。
在这种情况下,“对象”的概念扩展到比普通JavaScript对象更广泛的范围,并且还包含函数范围。
引用计数垃圾收集
这是最简单的垃圾收集算法。如果有零个引用指向它,则该对象会被认为是“垃圾收集” 。
看看下面的代码:
var o1 = {
o2: {
x: 1
}
};
// 2 objects are created.
// 'o2' is referenced by 'o1' object as one of its properties.
// None can be garbage-collected
var o3 = o1; // the 'o3' variable is the second thing that
// has a reference to the object pointed by 'o1'.
o1 = 1; // now, the object that was originally in 'o1' has a
// single reference, embodied by the 'o3' variable
var o4 = o3.o2; // reference to 'o2' property of the object.
// This object has now 2 references: one as
// a property.
// The other as the 'o4' variable
o3 = '374'; // The object that was originally in 'o1' has now zero
// references to it.
// It can be garbage-collected.
// However, what was its 'o2' property is still
// referenced by the 'o4' variable, so it cannot be
// freed.
o4 = null; // what was the 'o2' property of the object originally in
// 'o1' has zero references to it.
// It can be garbage collected.
周期引起问题
在周期方面有一个限制。例如下面的例子,创建两个对象并相互引用,这样会创建一个循环引用。在函数调用之后,它们将超出范围,所以它们实际上是无用的,可以被释放。然而,引用计数算法认为,由于两个对象中的每一个都被引用至少一次,所以两者都不能被垃圾收集机制收回。
function f() {
var o1 = {};
var o2 = {};
o1.p = o2; // o1 references o2
o2.p = o1; // o2 references o1. This creates a cycle.
}
f( );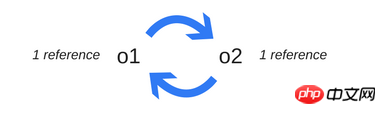
标记和扫描算法
为了决定是否需要对象,标记和扫描算法会确定对象是否是活动的。
标记和扫描算法经过以下3个步骤:
roots:通常,root是代码中引用的全局变量。例如,在JavaScript中,可以充当root的全局变量是“窗口”对象。Node.js中的相同对象称为“全局”。所有root的完整列表由垃圾收集器构建。然后算法会检查所有root和他们的子对象并且标记它们是活动的(即它们不是垃圾)。任何root不能达到的,将被标记为垃圾。最后,垃圾回收器释放所有未标记为活动的内存块,并将该内存返回给操作系统。
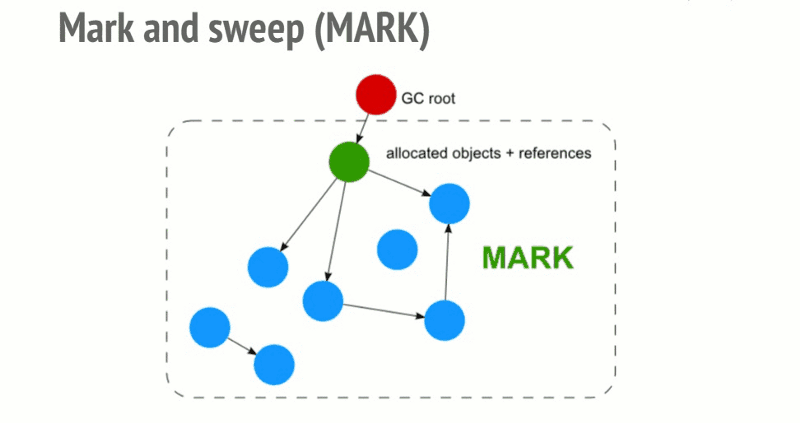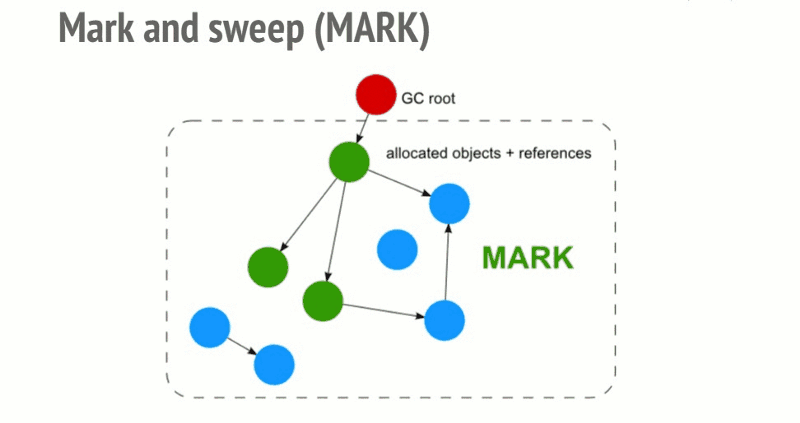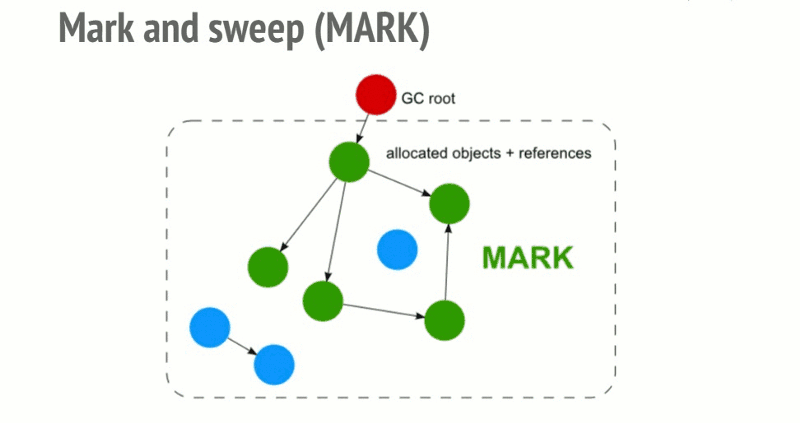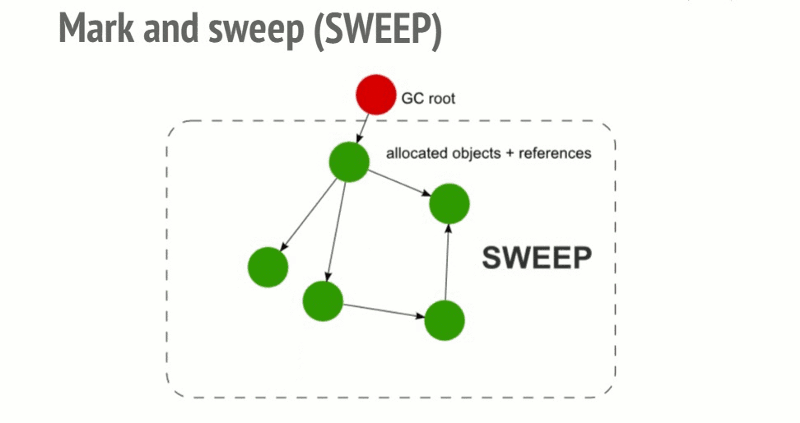
这个算法比引用计数垃圾收集算法更好。JavaScript垃圾收集(代码/增量/并发/并行垃圾收集)领域中所做的所有改进都是对这种标记和扫描算法的实现改进,但不是对垃圾收集算法本身的改进。
周期不再是问题了
在上面的相互引用例子中,在函数调用返回之后,两个对象不再被全局对象可访问的对象引用。因此,它们将被垃圾收集器发现,从而进行收回。
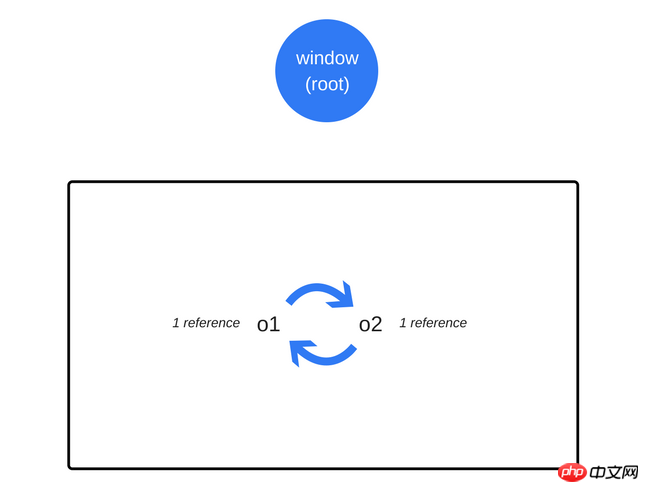
即使在对象之间有引用,它们也不能从root目录中访问,从而会被认为是垃圾而收集。
抵制垃圾收集器的直观行为
尽管垃圾收集器使用起来很方便,但它们也有自己的一套标准,其中之一是非决定论。换句话说,垃圾收集是不可预测的。你不能真正知道什么时候进行收集,这意味着在某些情况下,程序会使用更多的内存,虽然这是实际需要的。在其它情况下,在特别敏感的应用程序中,短暂暂停是很可能出现的。尽管非确定性意味着不能确定何时进行集合,但大多数垃圾收集实现了共享在分配期间进行收集的通用模式。如果没有执行分配,大多数垃圾收集会保持空闲状态。如以下情况:
大量的分配被执行。大多数这些元素(或所有这些元素)被标记为无法访问(假设我们将一个引用指向不再需要的缓存)。没有进一步的分配执行。
在这种情况下,大多数垃圾收集不会做出任何的收集工作。换句话说,即使有不可用的引用需要收集,但是收集器不会进行收集。虽然这并不是严格的泄漏,但仍会导致内存使用率高于平时。
什么是内存泄漏?
内存泄漏是应用程序使用过的内存片段,在不再需要时,不能返回到操作系统或可用内存池中的情况。
编程语言有各自不同的内存管理方式。但是是否使用某一段内存,实际上是一个不可判定的问题。换句话说,只有开发人员明确的知道是否需要将一块内存返回给操作系统。
四种常见的JavaScript内存泄漏
1:全局变量
JavaScript以一种有趣的方式来处理未声明的变量:当引用未声明的变量时,会在全局对象中创建一个新变量。在浏览器中,全局对象将是window,这意味着
function foo(arg) {
bar = "some text";
}相当于:
function foo(arg) {
window.bar = "some text";
}bar只是foo函数中引用一个变量。如果你不使用var声明,将会创建一个多余的全局变量。在上述情况下,不会造成很大的问题。但是,如若是下面的这种情况。
你也可能不小心创建一个全局变量this:
function foo() {
this.var1 = "potential accidental global";
}
// Foo called on its own, this points to the global object (window)
// rather than being undefined.
foo( );你可以通过在JavaScript文件的开始处添加‘use strict';来避免这中错误,这种方式将开启严格的解析JavaScript模式,从而防止意外创建全局变量。
意外的全局变量当然是一个问题。更多的时候,你的代码会受到显式的全局变量的影响,而这些全局变量在垃圾收集器中是无法收集的。需要特别注意用于临时存储和处理大量信息的全局变量。如果必须使用全局变量来存储数据,那么确保将其分配为空值,或者在完成后重新分配。
2:被遗忘的定时器或回调
下面列举setInterval的例子,这也是经常在JavaScript中使用。
对于提供监视的库和其它接受回调的工具,通常在确保所有回调的引用在其实例无法访问时,会变成无法访问的状态。但是下面的代码却是一个例外:
var serverData = loadData();
setInterval(function() {
var renderer = document.getElementById('renderer');
if(renderer) {
renderer.innerHTML = JSON.stringify(serverData);
}
}, 5000); //This will be executed every ~5 seconds.上面的代码片段显示了使用引用节点或不再需要的数据的定时器的结果。
该renderer对象可能会在某些时候被替换或删除,这会使interval处理程序封装的块变得冗余。如果发生这种情况,那么处理程序及其依赖项都不会被收集,因为interval需要先停止。这一切都归结为存储和处理负载数据的serverData不会被收集的原因。
当使用监视器时,你需要确保做了一个明确的调用来删除它们。
幸运的是,大多数现代浏览器都会为你做这件事:即使你忘记删除监听器,当被监测对象变得无法访问,它们就会自动收集监测处理器。这是过去的一些浏览器无法处理的情况(例如旧的IE6)。
看下面的例子:
var element = document.getElementById('launch-button');
var counter = 0;
function onClick(event) {
counter++;
element.innerHtml = 'text ' + counter;
}
element.addEventListener('click', onClick);
// Do stuff
element.removeEventListener('click', onClick);
element.parentNode.removeChild(element);
// Now when element goes out of scope,
// both element and onClick will be collected even in old browsers // that don't handle cycles well.由于现代浏览器支持垃圾回收机制,所以当某个节点变的不能访问时,你不再需要调用removeEventListener,因为垃圾回收机制会恰当的处理这些节点。
如果你正在使用jQueryAPI(其他库和框架也支持这一点),那么也可以在节点不用之前删除监听器。即使应用程序在较旧的浏览器版本下运行,库也会确保没有内存泄漏。
3:闭包
JavaScript开发的一个关键方面是闭包。闭包是一个内部函数,可以访问外部(封闭)函数的变量。由于JavaScript运行时的实现细节,可能存在以下形式泄漏内存:
var theThing = null;
var replaceThing = function(){
var originalThing = theThing;
var unused = function(){
if(originalThing)//对'originalThing'的引用
console.log(“hi”);
};
theThing = {
longStr:new Array(1000000).join('*'),
someMethod:function(){
console.log(“message”);
}
};
};
setInterval(replaceThing,1000);一旦replaceThing被调用,theThing会获取由一个大数组和一个新的闭包(someMethod)组成的新对象。然而,originalThing会被unused变量所持有的闭包所引用(这是theThing从以前的调用变量replaceThing)。需要记住的是,一旦在同一父作用域中为闭包创建了闭包的作用域,作用域就被共享了。
在这种情况下,闭包创建的范围会将someMethod共享给unused。然而,unused有一个originalThing引用。即使unused从未使用过,someMethod 也可以通过theThing在整个范围之外使用replaceThing。而且someMethod通过unused共享了闭包范围,unused必须引用originalThing以便使其它保持活跃(两封闭之间的整个共享范围)。这就阻止了它被收集。
所有这些都可能导致相当大的内存泄漏。当上面的代码片段一遍又一遍地运行时,你会看到内存使用率的不断上升。当垃圾收集器运行时,其内存大小不会缩小。这种情况会创建一个闭包的链表,并且每个闭包范围都带有对大数组的间接引用。
4:超出DOM引用
在某些情况下,开发人员会在数据结构中存储DOM节点,例如你想快速更新表格中的几行内容的情况。如果在字典或数组中存储对每个DOM行的引用,则会有两个对同一个DOM元素的引用:一个在DOM树中,另一个在字典中。如果你不再需要这些行,则需要使两个引用都无法访问。
var elements = {
button: document.getElementById('button'),
image: document.getElementById('image')
};
function doStuff() {
elements.image.src = 'http://example.com/image_name.png';
}
function removeImage() {
// The image is a direct child of the body element.
document.body.removeChild(document.getElementById('image'));
// At this point, we still have a reference to #button in the
//global elements object. In other words, the button element is
//still in memory and cannot be collected by the GC.
}在涉及DOM树内的内部节点或叶节点时,还有一个额外的因素需要考虑。如果你在代码中保留对表格单元格(标签)的引用,并决定从DOM中删除该表格,还需要保留对该特定单元格的引用,则可能会出现严重的内存泄漏。你可能会认为垃圾收集器会释放除了那个单元之外的所有东西,但情况并非如此。由于单元格是表格的一个子节点,并且子节点保留着对父节点的引用,所以对表格单元格的这种引用,会将整个表格保存在内存中。
相关推荐:
以上がJavaScript のメモリ リークに対処する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



