

知っておくべき機械学習アルゴリズム トップ 10

機械学習と人工知能の分野が近年ますます注目を集めていることは疑いの余地がありません。ビッグデータが業界で最もホットなテクノロジートレンドになるにつれ、機械学習もビッグデータの助けを借りて予測と推奨において驚くべき結果を達成しました。より有名な機械学習の事例としては、Netflix がユーザーの過去の閲覧行動に基づいて映画を推奨したり、Amazon がユーザーの過去の購入行動に基づいて書籍を推奨したりすることが挙げられます。この記事では、機械学習を簡単に説明する際に理解する必要のあるトップ 10 のアルゴリズムを主に紹介します。これは一定の参考価値があり、必要な友人が参照することができます。
では、機械学習アルゴリズムを学びたい場合は、どうやって始めればよいのでしょうか?私の場合、入門コースはコペンハーゲン留学中に受講した人工知能コースでした。先生はデンマーク工科大学の応用数学とコンピューターサイエンスの常勤教授で、主に論理手法を使用したモデリングを中心とした論理と人工知能を研究しています。このコースには、理論/中心概念のディスカッションと実践的な実践の 2 つの部分が含まれています。私たちが使用する教科書は、人工知能に関する古典的な本の 1 つです。Peter Norvig 教授の「Artificial Intelligence - A Modern Approach」です。このコースには、インテリジェント エージェント、検索ベースの解決、敵対的検索、確率理論、マルチエージェント システムなどが含まれます。人工知能の社会化、および人工知能の倫理や未来などのトピック。コースの後半では、私たち 3 人がチームを組んでプログラミング プロジェクトを実行し、仮想環境で輸送タスクを解決するための単純な検索ベースのアルゴリズムを実装しました。
このコースから多くのことを学びましたので、このテーマについてさらに深く勉強し続けるつもりです。ここ数週間、私はサンフランシスコ地域でディープラーニング、ニューラル ネットワーク、データ アーキテクチャに関するいくつかの講演に参加しました。また、多くの著名な教授が出席する機械学習カンファレンスにも参加しました。最も重要なことは、6 月初旬に Udacity の「機械学習入門」オンライン コースに登録し、数日前にコースの内容を完了したことです。この記事では、このコースで学んだ一般的な機械学習アルゴリズムをいくつか紹介したいと思います。
機械学習アルゴリズムは、通常、教師あり学習、教師なし学習、強化学習の 3 つの主要なカテゴリに分類できます。教師あり学習は主に、データセット (トレーニング データ) の一部には取得可能な類似性 (ラベル) があるが、残りのサンプルが欠落しているため予測する必要があるシナリオで使用されます。教師なし学習は主に、ラベルのないデータセット間の暗黙的な関係をマイニングするために使用されます。強化学習はその中間にあり、予測や行動の各ステップには多かれ少なかれフィードバック情報がありますが、正確なラベルやエラー プロンプトはありません。これは入門コースなので強化学習については触れていませんが、教師あり学習と教師なし学習の 10 個のアルゴリズムを理解していただければ十分だと思います。
教師あり学習
1. 意思決定ツリー:
意思決定ツリーは、確率事象の結果などを含む、意思決定プロセスとその後の結果を表す樹形図またはツリー モデルを使用する意思決定支援ツールです。デシジョン ツリーの構造を理解するには、以下の図を参照してください。
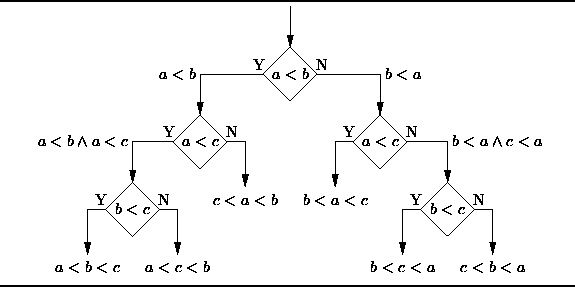
ビジネス上の意思決定の観点から見ると、デシジョン ツリーは、できるだけ少ない正誤判断の質問を通じて正しい決定の確率を予測するものです。このアプローチは、構造化された系統的なアプローチを使用して合理的な結論を引き出すのに役立ちます。
2. 単純ベイズ分類器:
単純ベイズ分類器は、特徴が事前に互いに独立していることを前提とする、ベイズ理論に基づく単純な確率的分類器です。以下の図は次の式を示しています。P(A|B) は事後確率、P(B|A) は尤度値、P(A) はカテゴリの事前確率、P(B) は予測子を表します。先験的確率。

実際のシナリオの例は次のとおりです:
スパムメールを検出する
ニュースをテクノロジー、政治、スポーツなどのカテゴリに分類する
テキストの一部がポジティブな感情を表現しているかネガティブな感情を表現しているかを判断する
人物に使用される顔検出ソフトウェア
3. 最小二乗回帰:
統計学のコースを受講したことがある方は、線形回帰の概念について聞いたことがあるかもしれません。最小二乗回帰は線形回帰の方法です。線形回帰は、直線を多数の点に当てはめることと考えることができます。 「最小二乗法」手法は、直線を引いて各点から直線までの垂直距離を計算し、最終的にその距離を合計することに相当します。距離の最小の合計。
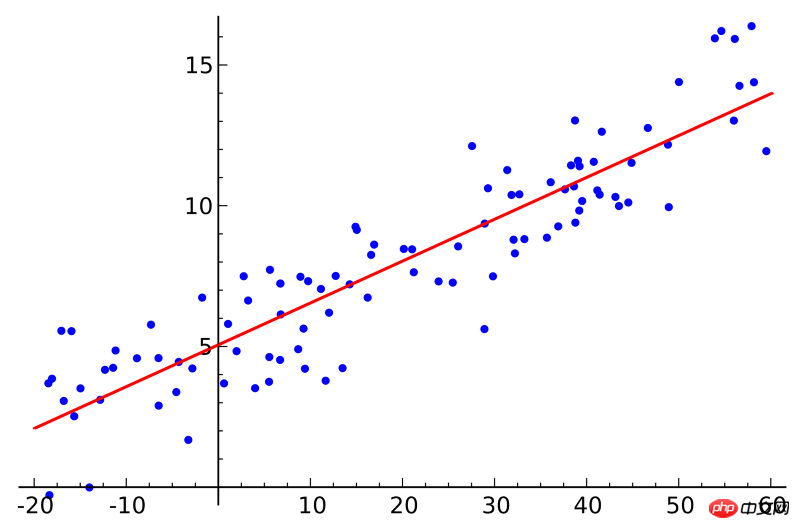
線形はデータの適合に使用されるモデルを指し、最小二乗は最適化される損失関数を指します。
4. ロジスティック回帰:
ロジスティック回帰モデルは、1 つ以上の説明変数を使用してバイナリ出力結果をモデル化する強力な統計モデリング手法です。ロジスティック関数を使用して確率値を推定し、累積ロジスティック分布に属するカテゴリカル従属変数と 1 つ以上の独立変数の間の関係を測定します。

一般的に、現実のシナリオにおけるロジスティック回帰モデルの応用例は次のとおりです:
信用スコア
事業活動の成功確率の予測
特定の製品の収益の予測
地震の確率の予測ある日の
5. サポートベクターマシン:
サポートベクターマシンはバイナリ分類アルゴリズムです。 N 次元空間に 2 種類の点があると、サポート ベクター マシンは (N-1) 次元の超平面を生成して、これらの点を 2 つのカテゴリに分類します。たとえば、紙上には直線的に分離可能な点が 2 種類あります。サポート ベクター マシンは、これら 2 種類の点を分離し、それぞれの点から可能な限り離れた直線を見つけます。
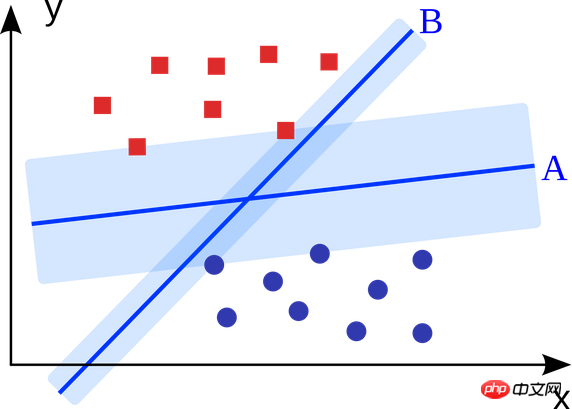
サポートベクターマシン(特定のアプリケーションシナリオに基づいて改良)を使用して、ディスプレイ広告、人体の関節部分認識、画像ベースの性別チェック、大規模な画像分類などを含む大規模な問題を解決します...
6. アンサンブル手法:
アンサンブル手法は、最初に分類子のセットを構築し、次に各分類子の加重投票を使用して新しいデータを予測するアルゴリズムです。元のアンサンブル手法はベイジアン平均化でしたが、より最近のアルゴリズムには、エラー訂正された出力エンコーディングとブースティング アルゴリズムが含まれています。

それでは、統合モデルの原理は何ですか?また、なぜ独立モデルよりパフォーマンスが優れているのでしょうか?
それらはバイアスの影響を排除します。たとえば、民主党のアンケートと共和党のアンケートを混ぜると、特徴のない中立的な情報が得られます。
予測の分散を減らすことができます。複数のモデルを集約した予測結果は、単一モデルの予測結果よりも安定しています。金融の世界では、これを分散化と呼びます。複数の銘柄を組み合わせた場合、単一の銘柄よりも常に値動きが小さくなります。これは、トレーニング データが増えるにつれてモデルがより良くなる理由も説明します。
それらは過適合する傾向がありません: 単一のモデルが過適合しない場合は、各モデルの予測結果 (平均、加重平均、ロジスティック回帰) を単純に組み合わせるだけで、過適合する理由はありません。
教師なし学習
7. クラスタリング アルゴリズム: クラスタリング アルゴリズムのタスクは、オブジェクトのグループを複数のグループにクラスタリングすることです。同じグループ (クラスター) 内のオブジェクトは、他のグループのオブジェクトよりも類似しています。
クラスタリング アルゴリズムはそれぞれ異なりますが、ここではいくつか挙げます: 
8. 主成分分析:
主成分分析は、相関する可能性のある一連の変数を 1 つの線形非相関変数のグループに変換します。主成分といいます。
主成分分析の実際的な応用例には、データ圧縮、単純化されたデータ表現、データの視覚化などが含まれます。主成分分析アルゴリズムの使用が適切かどうかを判断するには、ドメインの知識が必要であることに注意してください。データにノイズが多すぎる (つまり、各成分の分散が大きい) 場合、主成分分析アルゴリズムの使用は適していません。 
9. 特異値分解:
特異値分解は、線形代数における重要な行列分解であり、行列解析における通常の行列ユニタリ対角化の拡張です。与えられた m*n 行列 M については、M=UΣV に分解できます。ここで、U と V は次数 m×m のユニタリ行列、Σ は次数 m×n の半正定値対角行列です。
主成分分析は、実際には単純な特異値分解アルゴリズムです。コンピューター ビジョンの分野では、最初の顔認識アルゴリズムでは、主成分分析と特異値分解を使用して、次元削減後に顔を一連の「固有顔」の線形結合として表現し、その後、単純な方法を使用して候補の顔を照合しました。現代の手法はより洗練されていますが、多くの手法は似ています。 
10. 独立成分分析:
独立成分分析は、統計原理を使用して計算を実行し、確率変数、測定値、または信号の背後にある隠れた要因を明らかにする方法です。独立成分分析アルゴリズムは、観察された多変量データ (通常はサンプルの大きなバッチ) の生成モデルを定義します。このモデルでは、データ変数はいくつかの未知の潜在変数の線形混合であると仮定され、混合系も不明です。潜在変数は非ガウスで独立していると想定され、観測データの独立成分と呼ばれます。
独立成分分析は主成分分析に関連していますが、より強力な手法です。これらの従来の方法が失敗した場合でも、データ ソースの根本的な要因を見つけることができます。そのアプリケーションには、デジタル画像、文書データベース、経済指標、心理測定などが含まれます。
さて、理解したアルゴリズムを使用して機械学習アプリケーションを作成し、世界中の人々の生活の質を向上させてください。
関連する推奨事項:

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7649
7649
 15
1392
52
91
11
36
110
15
1392
52
91
11
36
110

 pip を完全にアンインストールし、Python をより効率的に使用する方法を学びます
Jan 16, 2024 am 09:01 AM
pip を完全にアンインストールし、Python をより効率的に使用する方法を学びます
Jan 16, 2024 am 09:01 AM
もうpipは必要ありませんか? pip を効果的にアンインストールする方法を学びましょう!はじめに: pip は Python のパッケージ管理ツールの 1 つで、Python パッケージを簡単にインストール、アップグレード、アンインストールできます。ただし、別のパッケージ管理ツールを使用したい場合や、Python 環境を完全にクリアする必要がある場合など、pip をアンインストールする必要がある場合があります。この記事では、pip を効率的にアンインストールする方法を説明し、具体的なコード例を示します。 1. pip をアンインストールする方法 以下では、pip をアンインストールする 2 つの一般的な方法を紹介します。
 matplotlib のカラーマップの詳細
Jan 09, 2024 pm 03:51 PM
matplotlib のカラーマップの詳細
Jan 09, 2024 pm 03:51 PM
matplotlib カラー テーブルの詳細については、特定のコード サンプルが必要です 1. はじめに matplotlib は強力な Python 描画ライブラリであり、さまざまな種類のチャートの作成に使用できる豊富な描画関数とツールのセットを提供します。カラーマップ (カラーマップ) は matplotlib の重要な概念であり、チャートの配色を決定します。 matplotlib カラー テーブルを詳しく学ぶことは、matplotlib の描画機能をよりよく習得し、描画をより便利にするのに役立ちます。
 C言語の魅力に迫る ~プログラマーの可能性を引き出す~
Feb 24, 2024 pm 11:21 PM
C言語の魅力に迫る ~プログラマーの可能性を引き出す~
Feb 24, 2024 pm 11:21 PM
C言語学習の魅力:プログラマーの可能性を引き出す テクノロジーの発展に伴い、コンピュータプログラミングは大きな注目を集めている分野です。数あるプログラミング言語の中でもC言語は常にプログラマーに愛されています。そのシンプルさ、効率性、幅広い用途により、C 言語の学習は、多くの人にとってプログラミングの分野に入る最初のステップとなっています。この記事では、C言語を学ぶ魅力と、C言語を学ぶことでプログラマーの可能性を引き出す方法について解説します。 C言語学習の魅力は、まずその簡単さにあります。他のプログラミング言語と比較すると、C言語は
 Pygame 入門: 包括的なインストールと構成のチュートリアル
Feb 19, 2024 pm 10:10 PM
Pygame 入門: 包括的なインストールと構成のチュートリアル
Feb 19, 2024 pm 10:10 PM
Pygame をゼロから学ぶ: 完全なインストールと構成チュートリアル、特定のコード例が必要 はじめに: Pygame は、Python プログラミング言語を使用して開発されたオープン ソースのゲーム開発ライブラリであり、豊富な機能とツールを提供し、開発者はさまざまなタイプのゲームを簡単に作成できますゲームの。この記事は、Pygame をゼロから学習するのに役立ち、完全なインストールと構成のチュートリアルと、すぐに始めるための具体的なコード例を提供します。パート1:最初にPythonとPygameをインストールして、確認してください
 Wordでルート番号を入力する方法を一緒に学びましょう
Mar 19, 2024 pm 08:52 PM
Wordでルート番号を入力する方法を一緒に学びましょう
Mar 19, 2024 pm 08:52 PM
Word でテキスト コンテンツを編集するときに、数式記号の入力が必要になる場合があります。 Word でルート番号を入力する方法を知らない人もいるので、Xiaomian は私に、Word でルート番号を入力する方法のチュートリアルを友達と共有するように頼みました。それが私の友達に役立つことを願っています。まず、コンピュータで Word ソフトウェアを開き、編集するファイルを開き、ルート記号を挿入する必要がある場所にカーソルを移動します。下の図の例を参照してください。 2. [挿入]を選択し、記号内の[数式]を選択します。下の図の赤丸で示すように: 3. 次に、下の[新しい数式を挿入]を選択します。以下の図の赤丸で示すように: 4. [根号式]を選択し、適切な根号を選択します。下の図の赤丸で示したように、
 CAD をスムーズに実行するにはどのような構成が必要ですか?
Jan 01, 2024 pm 07:17 PM
CAD をスムーズに実行するにはどのような構成が必要ですか?
Jan 01, 2024 pm 07:17 PM
CAD をスムーズに使用するにはどのような構成が必要ですか? CAD ソフトウェアをスムーズに使用するには、次の構成要件を満たす必要があります: プロセッサ要件: 「Word Play Flowers」をスムーズに実行するには、少なくとも 1 つの Intel Corei5 または Intel Corei5 を搭載している必要があります。 AMD Ryzen5 以降のプロセッサ。もちろん、より高性能のプロセッサを選択すると、処理速度が向上し、パフォーマンスが向上します。メモリはコンピュータの非常に重要なコンポーネントであり、コンピュータのパフォーマンスとユーザー エクスペリエンスに直接影響します。一般的に、日常使用のほとんどのニーズを満たすことができる少なくとも 8GB のメモリをお勧めします。ただし、パフォーマンスを向上させ、よりスムーズな使用体験を得るには、16GB 以上のメモリ構成を選択することをお勧めします。これにより、
 Go言語のmain関数をゼロから学ぶ
Mar 27, 2024 pm 05:03 PM
Go言語のmain関数をゼロから学ぶ
Mar 27, 2024 pm 05:03 PM
タイトル: Go言語のmain関数をゼロから学ぶ Go言語はシンプルで効率的なプログラミング言語として開発者に好まれています。 Go 言語では、main 関数はエントリ関数であり、すべての Go プログラムにはプログラムのエントリ ポイントとして main 関数が含まれている必要があります。この記事ではGo言語のmain関数をゼロから学ぶ方法と具体的なコード例を紹介します。 1. まず、Go 言語開発環境をインストールする必要があります。公式ウェブサイト (https://golang.org) にアクセスできます。
 pip のインストールをすぐに学び、スキルを一からマスターしましょう
Jan 16, 2024 am 10:30 AM
pip のインストールをすぐに学び、スキルを一からマスターしましょう
Jan 16, 2024 am 10:30 AM
pip のインストールを最初から学び、すぐにスキルをマスターしてください。特定のコード例が必要です。 概要: pip は、Python パッケージを簡単にインストール、アップグレード、管理できる Python パッケージ管理ツールです。 Python 開発者にとって、pip の使用スキルを習得することは非常に重要です。この記事では、pip のインストール方法を最初から紹介し、読者が pip の使用法をすぐにマスターできるように、いくつかの実践的なヒントと具体的なコード例を示します。 1. pip のインストール pip を使用する前に、まず pip をインストールする必要があります。ピップ