

1. ブロッキングキューとは何ですか?
BlockingQueue は、2 つの追加操作をサポートするキューです。これら 2 つの追加操作は次のとおりです。キューが空の場合、要素を取得するスレッドはキューが空でなくなるまで待機します。キューがいっぱいになると、要素を格納しているスレッドはキューが使用可能になるまで待機します。ブロッキング キューは、プロデューサーおよびコンシューマーのシナリオでよく使用されます。プロデューサーはキューに要素を追加するスレッドであり、コンシューマーはキューから要素を取得するスレッドです。ブロッキング キューは、プロデューサーが要素を格納するコンテナーであり、コンシューマーはコンテナーから要素のみを取得します。
ブロッキング キューには 4 つの処理方法が用意されています。
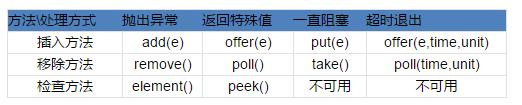
例外のスロー: ブロッキング キューがいっぱいの場合、キューに要素を挿入すると、IllegalStateException (「キューがいっぱい」) 例外がスローされます。キューが空の場合、キューから要素を取得するときに NoSuchElementException がスローされます。
特別な値を返す: 挿入メソッドは成功したかどうかを返し、成功した場合は true を返します。削除方法はキューから要素を取り出し、要素が無い場合はnull
を返す
常にブロックする: ブロッキング キューがいっぱいの場合、プロデューサー スレッドが要素をキューに入れると、キューはデータを取得するか割り込みに応答して終了するまでプロデューサー スレッドをブロックします。キューが空で、コンシューマ スレッドがキューから要素を取得しようとすると、キューが使用可能になるまで、キューはコンシューマ スレッドもブロックします。
タイムアウト終了: ブロッキング キューがいっぱいになると、キューはプロデューサー スレッドを一定時間ブロックし、一定時間を超えるとプロデューサー スレッドは終了します。
2. Java でのキューのブロック
JDK7 は 7 つのブロッキング キューを提供します。彼らは
ですArrayBlockingQueue は、配列を使用して実装された境界付きブロッキング キューです。このキューは要素を先入れ先出し (FIFO) ベースで並べ替えます。デフォルトでは、訪問者はキューへの公平なアクセスを保証されません。いわゆる公平なアクセス キューは、キューが使用可能な場合、つまりブロックされた順序でキューにアクセスできます。プロデューサ スレッドが最初にブロックされた場合、最初に要素をキューに挿入でき、最初にブロックしたコンシューマ スレッドが最初にキューから要素を取得できます。通常、公平性を確保するためにスループットは低下します。次のコードを使用して公平なブロッキング キューを作成できます:
ArrayBlockingQueue fairQueue = new ArrayBlockingQueue(1000,true);
訪問者の公平性は再入可能なロックを使用して実現されます。コードは次のとおりです:
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
LinkedBlockingQueue は、リンク リストを使用して実装された制限付きブロッキング キューです。このキューのデフォルトおよび最大長は Integer.MAX_VALUE です。このキューは要素を先入れ先出しベースで並べ替えます。
PriorityBlockingQueue は、優先順位をサポートする無制限のキューです。デフォルトでは、要素は自然な順序で配置され、要素の並べ替え規則もコンパレータを通じて指定できます。要素は昇順に並べ替えられます。
DelayQueue は、要素の遅延取得をサポートする無制限のブロッキング キューです。キューは、PriorityQueue を使用して実装されます。キュー内の要素は Delayed インターフェイスを実装する必要があります。要素を作成するときに、キューから現在の要素を取得するのにかかる時間を指定できます。要素は、遅延が期限切れになったときにのみキューからフェッチできます。 DelayQueue は次のアプリケーション シナリオで使用できます:
キャッシュ システムの設計: DelayQueue を使用してキャッシュ要素の有効期間を保存し、スレッドを使用してループ内で DelayQueue をクエリできます。要素が DelayQueue から取得できたら、キャッシュの有効期間が終了したことを意味します。期限切れ。
スケジュールされたタスク。 DelayQueueを使用して、その日に実行されるタスクと実行時間を保存します。たとえば、TimerQueueはDelayQueueを使用して実装されます。
キュー内の遅延では、要素の順序を指定するために CompareTo を実装する必要があります。たとえば、遅延が最も長いものをキューの最後に置きます。実装コードは次のとおりです:
public int compareTo(Delayed other) {
if (other == this) // compare zero ONLY if same object
return 0;
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask x = (ScheduledFutureTask)other;
long diff = time - x.time;
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long d = (getDelay(TimeUnit.NANOSECONDS) -
other.getDelay(TimeUnit.NANOSECONDS));
return (d == 0) ? 0 : ((d < 0) ? -1 : 1);
}
3. 遅延インターフェースの実装方法
ScheduledThreadPoolExecutor で ScheduledFutureTask クラスを参照できます。このクラスは Delayed インターフェイスを実装します。まず、オブジェクトが作成されたときに、前のオブジェクトがいつ使用できるかを記録するために時間を使用します。コードは次のとおりです:
ScheduledFutureTask(Runnable r, V result, long ns, long period) {
super(r, result);
this.time = ns;
this.period = period;
this.sequenceNumber = sequencer.getAndIncrement();
}
次に、getDelay を使用して、現在の要素をどれだけ遅延させる必要があるかをクエリします。コードは次のとおりです。
public long getDelay(TimeUnit unit) {
return unit.convert(time - now(), TimeUnit.NANOSECONDS);
}
通过构造函数可以看出延迟时间参数ns的单位是纳秒,自己设计的时候最好使用纳秒,因为getDelay时可以指定任意单位,一旦以纳秒作为单位,而延时的时间又精确不到纳秒就麻烦了。使用时请注意当time小于当前时间时,getDelay会返回负数。
4.如何实现延时队列
延时队列的实现很简单,当消费者从队列里获取元素时,如果元素没有达到延时时间,就阻塞当前线程。
long delay = first.getDelay(TimeUnit.NANOSECONDS);
if (delay <= 0)
return q.poll();
else if (leader != null)
available.await();
SynchronousQueue是一个不存储元素的阻塞队列。每一个put操作必须等待一个take操作,否则不能继续添加元素。SynchronousQueue可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合于传递性场景,比如在一个线程中使用的数据,传递给另外一个线程使用,SynchronousQueue的吞吐量高于LinkedBlockingQueue 和 ArrayBlockingQueue。
LinkedTransferQueue是一个由链表结构组成的无界阻塞TransferQueue队列。相对于其他阻塞队列,LinkedTransferQueue多了tryTransfer和transfer方法。
transfer方法。如果当前有消费者正在等待接收元素(消费者使用take()方法或带时间限制的poll()方法时),transfer方法可以把生产者传入的元素立刻transfer(传输)给消费者。如果没有消费者在等待接收元素,transfer方法会将元素存放在队列的tail节点,并等到该元素被消费者消费了才返回。transfer方法的关键代码如下:
Node pred = tryAppend(s, haveData); return awaitMatch(s, pred, e, (how == TIMED), nanos);
第一行代码是试图把存放当前元素的s节点作为tail节点。第二行代码是让CPU自旋等待消费者消费元素。因为自旋会消耗CPU,所以自旋一定的次数后使用Thread.yield()方法来暂停当前正在执行的线程,并执行其他线程。
tryTransfer方法。则是用来试探下生产者传入的元素是否能直接传给消费者。如果没有消费者等待接收元素,则返回false。和transfer方法的区别是tryTransfer方法无论消费者是否接收,方法立即返回。而transfer方法是必须等到消费者消费了才返回。
对于带有时间限制的tryTransfer(E e, long timeout, TimeUnit unit)方法,则是试图把生产者传入的元素直接传给消费者,但是如果没有消费者消费该元素则等待指定的时间再返回,如果超时还没消费元素,则返回false,如果在超时时间内消费了元素,则返回true。
LinkedBlockingDeque是一个由链表结构组成的双向阻塞队列。所谓双向队列指的你可以从队列的两端插入和移出元素。双端队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。相比其他的阻塞队列,LinkedBlockingDeque多了addFirst,addLast,offerFirst,offerLast,peekFirst,peekLast等方法,以First单词结尾的方法,表示插入,获取(peek)或移除双端队列的第一个元素。以Last单词结尾的方法,表示插入,获取或移除双端队列的最后一个元素。另外插入方法add等同于addLast,移除方法remove等效于removeFirst。但是take方法却等同于takeFirst,不知道是不是Jdk的bug,使用时还是用带有First和Last后缀的方法更清楚。
在初始化LinkedBlockingDeque时可以设置容量防止其过渡膨胀。另外双向阻塞队列可以运用在“工作窃取”模式中。
5.阻塞队列的实现原理
本文以ArrayBlockingQueue为例,其他阻塞队列实现原理可能和ArrayBlockingQueue有一些差别,但是大体思路应该类似,有兴趣的朋友可自行查看其他阻塞队列的实现源码。
首先看一下ArrayBlockingQueue类中的几个成员变量:
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
private static final long serialVersionUID = -817911632652898426L;
/** The queued items */
private final E[] items;
/** items index for next take, poll or remove */
private int takeIndex;
/** items index for next put, offer, or add. */
private int putIndex;
/** Number of items in the queue */
private int count;
/*
* Concurrency control uses the classic two-condition algorithm
* found in any textbook.
*/
/** Main lock guarding all access */
private final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
}
可以看出,ArrayBlockingQueue中用来存储元素的实际上是一个数组,takeIndex和putIndex分别表示队首元素和队尾元素的下标,count表示队列中元素的个数。
lock是一个可重入锁,notEmpty和notFull是等待条件。
下面看一下ArrayBlockingQueue的构造器,构造器有三个重载版本:
public ArrayBlockingQueue(int capacity) {
}
public ArrayBlockingQueue(int capacity, boolean fair) {
}
public ArrayBlockingQueue(int capacity, boolean fair,
Collection<? extends E> c) {
}
第一个构造器只有一个参数用来指定容量,第二个构造器可以指定容量和公平性,第三个构造器可以指定容量、公平性以及用另外一个集合进行初始化。
然后看它的两个关键方法的实现:put()和take():
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
final E[] items = this.items;
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
try {
while (count == items.length)
notFull.await();
} catch (InterruptedException ie) {
notFull.signal(); // propagate to non-interrupted thread
throw ie;
}
insert(e);
} finally {
lock.unlock();
}
}
从put方法的实现可以看出,它先获取了锁,并且获取的是可中断锁,然后判断当前元素个数是否等于数组的长度,如果相等,则调用notFull.await()进行等待,如果捕获到中断异常,则唤醒线程并抛出异常。
当被其他线程唤醒时,通过insert(e)方法插入元素,最后解锁。
我们看一下insert方法的实现:
private void insert(E x) {
items[putIndex] = x;
putIndex = inc(putIndex);
++count;
notEmpty.signal();
}
它是一个private方法,插入成功后,通过notEmpty唤醒正在等待取元素的线程。
下面是take()方法的实现:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
try {
while (count == 0)
notEmpty.await();
} catch (InterruptedException ie) {
notEmpty.signal(); // propagate to non-interrupted thread
throw ie;
}
E x = extract();
return x;
} finally {
lock.unlock();
}
}
跟put方法实现很类似,只不过put方法等待的是notFull信号,而take方法等待的是notEmpty信号。在take方法中,如果可以取元素,则通过extract方法取得元素,下面是extract方法的实现:
private E extract() {
final E[] items = this.items;
E x = items[takeIndex];
items[takeIndex] = null;
takeIndex = inc(takeIndex);
--count;
notFull.signal();
return x;
}
跟insert方法也很类似。
其实从这里大家应该明白了阻塞队列的实现原理,事实它和我们用Object.wait()、Object.notify()和非阻塞队列实现生产者-消费者的思路类似,只不过它把这些工作一起集成到了阻塞队列中实现。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



