

この記事では、主に MySQL のデッドロックとログについて説明します。オンラインでの MySQL の問題を素早く特定し、実際のビジネスで例外を修正する方法について説明します。この記事では、2 つの実際のケースに基づいた関連する経験と方法を紹介します。興味のある友人が参考になれば幸いです。
最近、オンライン MySQL でいくつかのデータ異常が発生しましたが、これらはすべて早朝に発生したため、ビジネス シナリオは典型的なデータ ウェアハウス アプリケーションであるため、日中の負荷は低く、再現できません。異常の中には奇妙なものもあり、最終的な根本原因の分析は非常に困難です。では、オンラインで MySQL の問題を迅速に特定し、実際のビジネスで例外を修正するにはどうすればよいでしょうか?以下では、実際の 2 つのケースに基づいて、関連する経験と方法を紹介します。
ケース 1: 一部のデータ更新に失敗しました
ある日、チャネルのクラスメイトが、特定のレポートで 0 のチャネル データはほとんどなく、ほとんどのチャネル データは正常であると報告しました。このデータは統計プログラムによって毎朝早朝に定期的に更新されますが、すべてが正常であるか、すべてが失敗しているかのどちらかになります。では、いくつかの個別のデータの異常の原因は何でしょうか。
まず、統計タスクのログを見ることが考えられますが、統計プログラムが出力したログを見てもSQL更新失敗などの異常な記述は見当たりませんでした。そのときデータベース内で何が起こったのでしょうか? MySQL サーバーのログをチェックする前に、私は習慣的にデータベースのステータスを確認しました:

早朝にたまたまこの更新でデッドロックを発見しました:
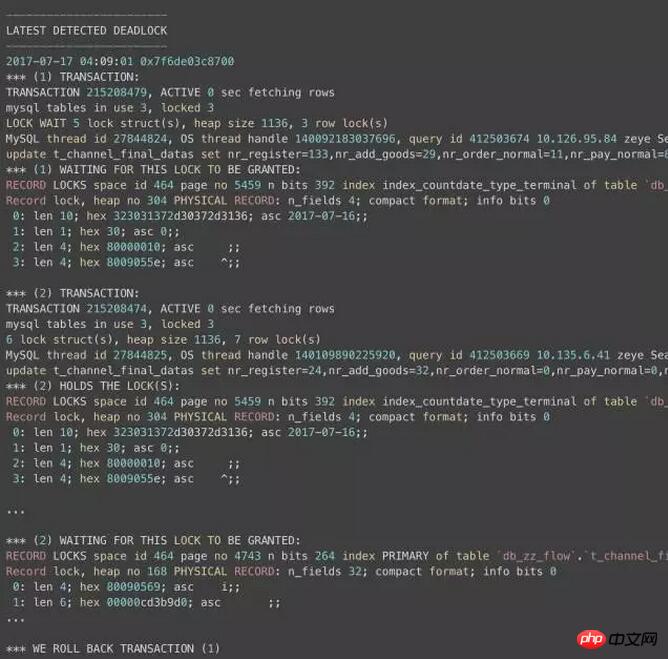
スペースの制限により、多くの部分を省略しましたこのログでわかるように、TRANSACTION 1 と TRANSACTION 2 はそれぞれ一定数の行ロックを保持し、相手のロックを待ちます。最後に、MySQL はデッドロックを検出し、TRANSACTION 1 のロールバックを選択します。 : Innodb の現在のデッドロック処理方法は、最も少ない行レベルの排他ロックを保持しているトランザクションをロールバックすることです。
ここで 3 つの質問があります:
1. innodb の行ロックは 1 つの行のみをロックするのではありませんか?
このテーブルは innodb エンジンからのものであるため、InnoDB は行ロックとテーブル ロックをサポートしています。 InnoDB の行ロックは、インデックスのインデックス エントリをロックすることによって実装されます。これは、データ ブロック内の対応するデータ行をロックすることによって実装される MySQL や Oracle とは異なります。 InnoDB の行ロック実装機能は、InnoDB がインデックス条件を通じてデータを取得する場合にのみ行レベルのロックを使用することを意味します。それ以外の場合、InnoDB はテーブル ロックを使用し、スキャンされたすべての行をロックします。実際のアプリケーションでは、InnoDB 行ロックのこの機能に特別な注意を払う必要があります。そうしないと、多数のロック競合が発生し、同時実行パフォーマンスに影響を与える可能性があります。 MySQL の行ロックはレコードではなくインデックスに対するロックであるため、異なる行のレコードにアクセスしても同じインデックスキーを使用するとロックの競合が発生します。等価条件の代わりに範囲条件を使用してデータを取得し、共有ロックまたは排他ロックを要求すると、InnoDB は条件を満たす既存のデータ レコードのインデックス エントリをロックします。また、ギャップ ロックは複数の行を渡すだけでなく、ロックも行います。ロック時にギャップ ロックを使用するだけでなく、複数の行をロックするだけでなく、等しい条件を使用して存在しないレコードのロックを要求すると、InnoDB はギャップ ロックも使用します。
これを述べたところで、ビジネス テーブルのインデックスの状況を見てみましょう:
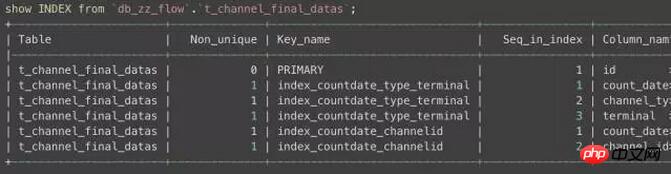
このテーブルのインデックスは非常に不合理であることがわかります。インデックスは 3 つありますが、更新が完全には行われていません。インデックスが使用されているため、インデックスを正確に使用せずに更新が行われ、複数行の範囲データをロックする必要があるため、デッドロックが発生します。
原理を理解した後、更新で innodb インデックスを正確に使用できるように、4 つのフィールドを組み合わせたインデックスを慎重に構築できます。実際、インデックスを更新すると、このデッドロックの問題は解決されます。
注: innodb は、トランザクションと、トランザクションによって保持および待機されているロックだけでなく、レコード自体も出力します。残念ながら、出力結果用に innodb によって予約された長さを超える可能性があります (1M のみが出力可能)完全な出力を表示できない場合は、この時点で任意のライブラリの下に innodb_monitor または innodb_lock_monitor テーブルを作成すると、innodb ステータス情報が完全になり、エラーが表示されます。 15秒ごとにログに記録されます。例: create table innodb_monitor(a int)engine=innodb; エラー ログに記録する必要がない場合は、テーブルを削除するだけです。
2. ロールバック時に一部の更新ステートメントのみが失敗するのはなぜですか?
ロールバックの場合、トランザクション全体のすべての更新ではなく、一部の更新ステートメントのみが失敗するのはなぜですか?
これは、innodb がデフォルトで自動的に送信されるためです:
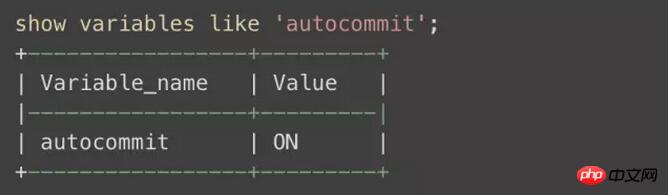
複数の update または insert ステートメントの場合、各 SQL が実行された後、innodb は変更を永続化すると同時にロックを解放するために 1 回コミットします。これが、このデッドロック ロールバック トランザクション後に失敗したステートメントがわずか数個だけである理由です。例。
通常、一部のステートメントがロールバックされる可能性のある別の状況があり、特別な注意が必要であることに注意してください。 innodb には、innodb_rollback_on_timeout
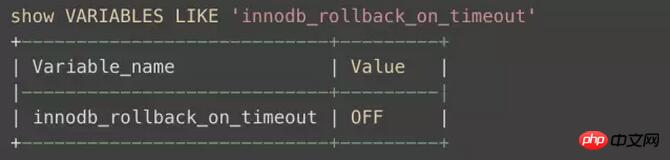
というパラメータがあります。公式マニュアルでは次のように説明されています:
MySQL 5.1 では、InnoDB はデフォルトでトランザクション タイムアウト時に最後のステートメントのみをロールバックします。 –innodb_rollback_on_timeout が指定されている場合、トランザクション タイムアウトにより、InnoDB はトランザクション全体を中止し、ロールバックします (MySQL 4.1 と同じ動作)。この変数は MySQL 5.1.15 で追加されました。
説明: このパラメータがオフになっているか、存在しない場合、タイムアウトが発生した場合、最後のトランザクションがロールバックされます。クエリが開かれている場合、トランザクションがタイムアウトになった場合、トランザクション全体がロールバックされます。
3. innodb デッドロックの可能性を減らすにはどうすればよいですか?
行ロックとトランザクションのシナリオでデッドロックを完全に排除することは困難ですが、ロックの競合とデッドロックは、テーブル設計と次のような SQL 調整によって軽減できます。
デッドロックが発生した場合は、たとえば、より低い分離レベルを使用してみてください。ギャップ ロックを回避するには、セッションまたはトランザクションのトランザクション分離レベルを RC (コミットされた読み取り) レベルに変更できますが、現時点では、binlog_format を行または混合形式に設定する必要があります
インデックスを慎重に設計し、次のことを試してください。インデックスを使用してデータにアクセスすることで、ロックがより正確になり、ロック競合の可能性が低くなります。
適切なトランザクション サイズを選択すると、小規模なトランザクションでロックが競合する可能性も小さくなります。レコード セットを使用するには、一度に十分なレベルのロックを要求するのが最善です。たとえば、データを変更する場合は、最初に共有ロックを適用するのではなく、排他ロックを直接適用し、変更するときに排他ロックを要求することをお勧めします。これにより、異なるプログラムがアクセスする場合にデッドロックが発生しやすくなります。テーブルのグループでは、同じことに同意するように努める必要があります。各テーブルに順番にアクセスします。テーブルの場合は、テーブル内の行にできる限り固定された順序でアクセスします。これにより、デッドロックの可能性が大幅に減少します。
同時挿入に対するギャップ ロックの影響を避けるために、同じ条件を使用するようにしてください。
必要な場合を除き、ロック レベルを適用しないでください。 、クエリ時にロックを表示しません。
一部の特定のトランザクションでは、テーブル ロックを使用して処理速度を向上させたり、デッドロックの可能性を軽減したりできます。
ケース 2:奇妙なロック待機タイムアウト 数日間連続して午前 6 時と午前 8 時にタスクが失敗し、データ ローカル infile をロードするときに、トランザクション innodb の再起動を試行してロック待機タイムアウトを超えたと報告されました。プラットフォーム上でクラスメートとコミュニケーションを取った後、これは自分のビジネス データベースのロック時間が短すぎるか、ロックの競合が発生しているという問題であることがわかりました。しかし、振り返ってみると、そうすべきではないでしょうか?いつもこれでいいんじゃないの?また、基本的に単一形式のタスクであり、複数人での衝突はありません。 それが誰の問題であるかに関係なく、まずデータベースに問題があるかどうかを確認しましょう:
デフォルトのロックタイムアウトは50秒ですが、実際には、これを調整するのはおそらく無駄です。本当に死んでいます。馬医のように試しましたが、うまくいきませんでした。 。 。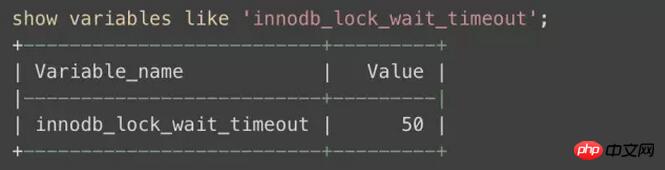 そして今回は、SHOW ENGINE INNODB STATUSG にはデッドロック情報が表示されませんでした。次に、その瞬間の前後にデータがどのような操作を行ったかをログから確認したいと考えて、MySQL サーバーのログに注目しました。 MySQL ログ ファイル システムの構成を簡単に紹介します。
そして今回は、SHOW ENGINE INNODB STATUSG にはデッドロック情報が表示されませんでした。次に、その瞬間の前後にデータがどのような操作を行ったかをログから確認したいと考えて、MySQL サーバーのログに注目しました。 MySQL ログ ファイル システムの構成を簡単に紹介します。
(a) エラー ログ: mysqld の起動、実行、停止時に発生した問題を記録します。デフォルトで有効になっています。
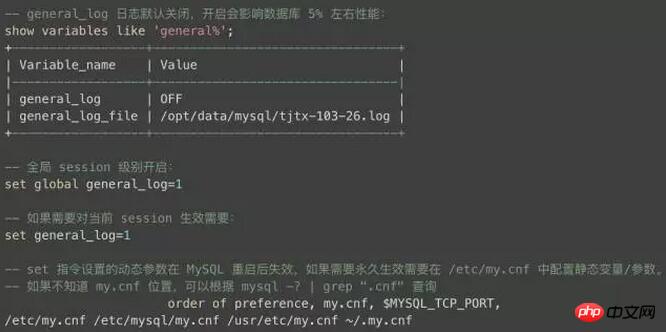
(b) 一般ログ: すべてのステートメントと命令を記録する一般的なクエリ ログ。データベースを開くと、約 5% のパフォーマンスが低下します。(c) binlog ログ: バイナリ形式で、データを変更するすべてのステートメントを記録し、主にスレーブ レプリケーションとデータ リカバリに使用されます。
(d) スロー ログ: 実行に long_query_time 秒以上かかるすべてのクエリ、またはインデックスを使用しないクエリ (デフォルトで閉じられている) を記録します。 (e) Innodb ログ: innodb REDO ログ、UNDO ログ。データの復元と操作の取り消しに使用されます。
上記の紹介からわかるように、この問題の現在のログは d と b にある可能性があります。d にログインがない場合は、b を有効にすることしかできませんが、b のパフォーマンスはある程度低下します。データベースがいっぱいなので、ログの量が非常に膨大なので、開くときは注意が必要です:
上記の例外は、クライアントのリクエストが私たちの側に届く前にスローされたことが確認されています。プラットフォームとの通信と確認を繰り返した結果、プラットフォームは最終的に、実行前に SQL タスク テーブルからフェッチする必要があることが原因であることを確認しました。その結果、このテーブルでは 1 時間あたりに多数の挿入と更新が行われ、ロックの待機中に一部の SQL がタイムアウトになります。 。 。
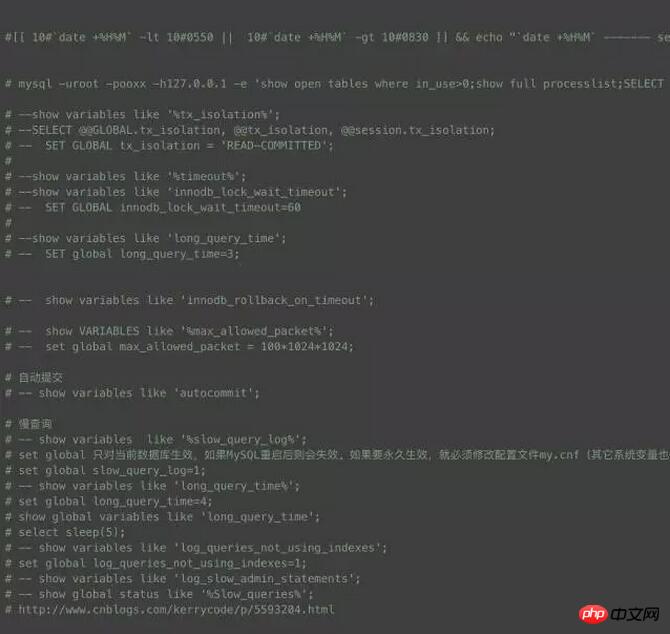
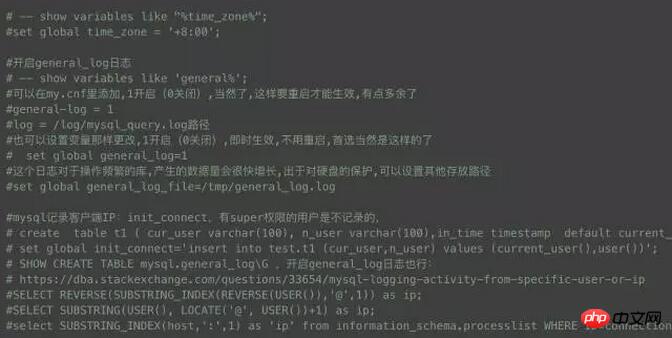
MySQL ログ分析スクリプト
早朝はデータ ウェアハウスのビジネスのピークであるため、この時間帯に多くの問題が発生し、この村を過ぎるといくつかの奇妙な問題が発生し、日中はストアが再現できなくなることがよくあります。問題を迅速に特定できるように、重要なログを取得する方法が最優先事項です。ここでは、開く時間範囲を選択して、必要なものをサンプリングできる小さなスクリプトを作成しました。一般的なログについて説明します。簡単にオンにしないでください。オンにしないと、データベースのパフォーマンスに大きな損害が発生します。
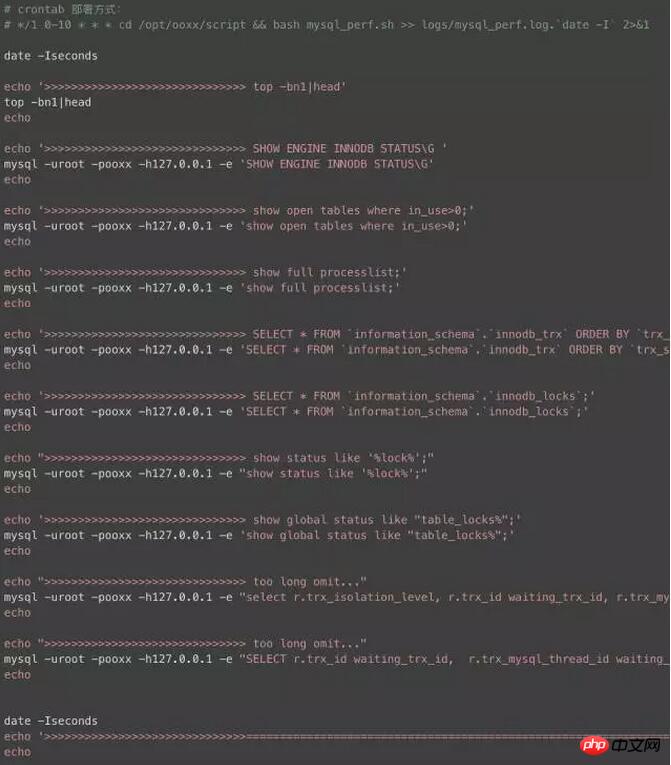
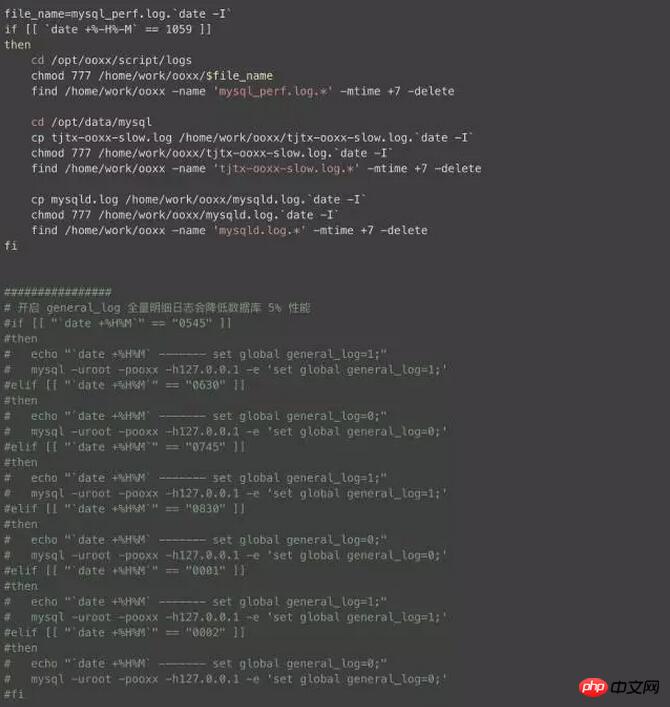
関連する推奨事項:
Mysql のデッドロック問題を解決するための kill コマンドの使用の詳細な説明
以上がMySQL のデッドロックとログの分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



