

この記事では、主に Linux オペレーティング システムの原理について説明します。これは、Linux システムに関する非常に優れた基本的なチュートリアルです。関連する内容をすべてまとめています。一緒に勉強しましょう。皆さんのお役に立てれば幸いです。
1. コンピューターの 4 つの時代
1. 第一世代:
真空管コンピューター、入力と出力: コンピューターの操作は非常に不便ですが、一つのことを成し遂げるには十数人が必要であり、その年はおそらく 1945 年から 1955 年です。当時、家にコンピューターがあった場合、コンピューターの電源を入れるとすぐに電球の明るさが暗くなる可能性があります (笑)。第 2 世代:
トランジスタ コンピューター。バッチ処理(シリアルモード動作)システムが登場。最初のものよりもはるかに電力を節約します。その代表格がメインフレームです。おおよその年: 1955 ~ 1965 年。その時代に: 非常に古いコンピューター言語である Fortran 言語が誕生しました。
3. 第 3 世代:
集積回路の出現とマルチチャネル処理プログラムの設計 (並列モードで実行) 代表的なものは、タイムシェアリング システム (CPU の動作をタイム スライスに分割する) です。年代はおそらく1965年から1980年頃だと思われます。
4. 第 4 世代:
PC が登場、おそらく 1980 年頃。この時代の典型的な代表者は、ビル・ゲイツ、スティーブ・ジョブズだと思います。
2. コンピュータの動作システム
コンピュータは 4 つの時代を経て進化してきましたが、今日現在、コンピュータの動作システムはまだ比較的単純です。一般に、私たちのコンピュータには 5 つの基本コンポーネントがあります。
1.MMU(メモリ制御ユニット、メモリページング[メモリページ]を実装)
演算機構はCPUから独立しています(演算制御ユニット)CPUにはMMUと呼ばれる独自のチップがあります。スレッドアドレスとプロセスの物理アドレスの対応を計算するために使用されます。これはアクセス保護にも使用されます。つまり、プロセスが自分自身以外のメモリ アドレスに初めてアクセスすると、そのアクセスは拒否されます。
2. メモリ (メモリ)
3. 表示デバイス (VGA インターフェース、モニターなど) [IO デバイスに属する]
4. 入力デバイス (キーボード、キーボード デバイス) [IO デバイスに属する]
5. . ハードディスク装置 (ハードディスク制御、ハードディスクコントローラまたはアダプタ) [IO 装置に属する]
拡張知識:
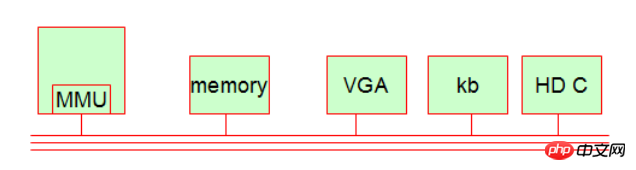 これらのハードウェアデバイスはバス上に接続されており、この回線を介してデータを交換します。内部は CPU が最高のコマンド権限を持っています。では、どのように機能するのでしょうか?
これらのハードウェアデバイスはバス上に接続されており、この回線を介してデータを交換します。内部は CPU が最高のコマンド権限を持っています。では、どのように機能するのでしょうか?
A. 命令ユニット (メモリから命令をフェッチ);
B. デコードユニット (メモリからフェッチされたデータを実際に実行できる命令に変換する);
C.命令の要件に従って動作するように別のハードウェアを呼び出します);
上記のことから、MMU が CPU の一部であることがわかりましたが、CPU には他のコンポーネントが必要ですか?もちろん、命令レジスタチップ、命令カウンタチップ、スタックポインタなどもあります。
命令レジスタチップ: CPUがメモリ内のデータを取り出して保存する場所です。
命令カウンターチップ: CPUがメモリからデータをフェッチした最後の場所を記録する場所です。次回簡単に取得できます。
スタック ポインタ: CPU は命令をフェッチするたびに、スタック ポインタをメモリ内の次の命令の位置に指します。
その動作サイクルはCPUと同じくらい速く、CPUの動作周波数は同じクロックサイクルであるため、そのパフォーマンスは非常に優れており、データ通信はCPUの内部バス上で完了します。命令レジスタチップ、命令カウンタチップ、スタックポインタ。これらのデバイスは通常、CPU レジスタと呼ばれます。
レジスタは実際にシーンを保存するために使用されます。これは、時間多重化で特に顕著です。たとえば、CPU を複数のプログラムで共有する場合、CPU はプロセスを終了または一時停止することが多く、オペレーティング システムは現在の実行ステータスを保存する必要があります (後で CPU が戻ってきたときに処理を続行できるようにするため)。 . ) を実行し、他のプロセスを実行し続けます (これをコンピュータのコンテキスト スイッチと呼びます)。
3. コンピューターストレージシステム。
1. 対称型マルチプロセッサ SMP
MMU やレジスタ (CPU の動作サイクルに近い) などに加えて、CPU にはデータの処理に特化した複数のコアがあります。コードを並列実行するために使用されます。業界の多くの企業は複数の CPU を使用しています。この構造は対称型マルチプロセッサと呼ばれます。
2. プログラム局所性の原則
空間的局所性:
プログラムは命令とデータで構成されます。空間的局所性とは、1 つのデータにアクセスした後、そのデータに非常に近い他のデータにも引き続きアクセスできることを意味します。
時間的局所性:
一般的に言えば、プログラムの実行が完了すると、すぐにアクセスされる可能性があります。同じ原則がデータにも当てはまります。データに一度アクセスすると、再度アクセスされる可能性があります。
空間的局所性の観点から見ても、時間的局所性の観点から見ても、一般的にデータをキャッシュする必要があるのは、まさにプログラムの局所性が存在するためです。
知識の拡充:
CPU内部のレジスタ記憶空間は限られているため、データの保存にはメモリが使用されますが、CPUの速度とメモリの速度は全く同じレベルではないため、データを処理する際には、 data、return to それらのほとんどは待機中です (CPU はメモリからデータをフェッチする必要があり、CPU の 1 回転で処理できますが、メモリは 20 回転する必要がある場合があります)。効率を向上させるために、キャッシュの概念が登場しました。
プログラムの局所性の原則がわかったので、より多くのスペースを取得するために、CPU は実際にはスペースの交換に時間を費やしますが、キャッシュを使用すると CPU に直接データを取得させることができ、時間を節約できることもわかりました。キャッシュは使用されます スペースは時間と交換されます
たとえそれがストレージシステムに含まれていても
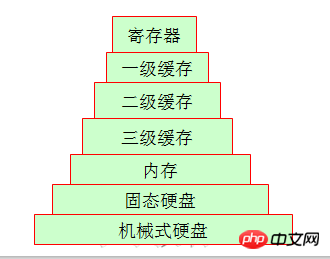
長年働いている友人はテープドライブを見たことがあるかもしれませんが、今では基本的に多くのものです。企業はテープ ドライブの代わりにハードディスクを使用しているため、私たちが最もよく知っている家庭用コンピューターの構造を見てみましょう。そこに保存されているデータは、前回保存されていたものとは異なります。簡単な例を挙げると、週ごとの保管サイクルには大きな差があります。特に明らかなのは、機械式ハードドライブとメモリのアクセスに関する差です。
知識の拡大:
自宅のデスクトップやラップトップと比較して、自分で分解して、機械式ハードドライブ、ソリッドステートドライブ、メモリなどについて話したことがあるかもしれません。しかし、キャッシュ物理デバイスを見たことがないかもしれませんが、実際には CPU 上にあります。したがって、私たちの理解には盲点があるかもしれません。
まず、一次キャッシュとヘッドセット キャッシュについて説明します。一次キャッシュと二次キャッシュはどちらも内部リソースであるため、CPU がここでデータをフェッチする時間は、基本的にそれほど長くはありません。 CPUコア。 (同じハードウェア条件では、128k L1 キャッシュの市場価格は約 300 元、256k L1 キャッシュの市場価格は約 600 元、512k L1 キャッシュの市場価格は 4 桁を超える可能性があります。参照できます。具体的な価格については、JD.com にお問い合わせください。これだけでも、キャッシュのコストが非常に高いことがわかります。) ここで、3 次キャッシュはどうなるのでしょうか?と疑問に思うかもしれません。実際、3 次キャッシュは複数の CPU によって共有されるスペースです。もちろん、複数の CPU はメモリも共有します。
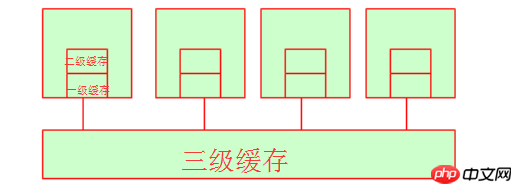
4. Non-Uniform Memory Access (NUMA)
複数の CPU が L3 キャッシュやメモリを共有すると、リソースの収用という問題が発生することがわかっています。変数または文字列は、メモリに保存されるときにメモリ アドレスを持つことがわかっています。彼らはどうやってメモリアドレスを取得するのでしょうか?以下の図を参照してください:
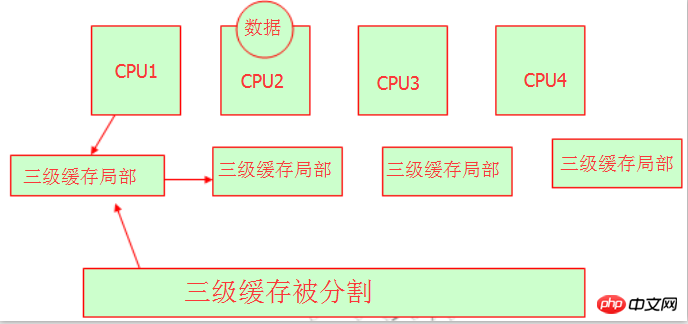
はい、これらのハードウェア専門家は、レベル 3 キャッシュを分割し、異なる CPU が異なるメモリ アドレスを占有できるようにしました。そのため、それらはすべて独自のレベル 3 キャッシュ領域を持っていることがわかります。リソースの取得に問題はありませんが、依然として同じ 3 次キャッシュであることに注意してください。北京に朝陽区、豊台区、大興区、海淀区などがあるのと同じように、それらはすべて北京の一部です。ここで理解できます。これは NUMA であり、その特徴は次のとおりです。不均一なメモリ アクセスであり、それぞれが独自のメモリ空間を持ちます。
拡張知識:
そこで問題は、リロードの結果に基づいて、cpu1 によって実行されているプロセスが一時停止された場合、そのアドレスは自身のキャッシュ アドレスに記録されますが、cpu2 がプログラムを再度実行するときに、どのように処理されるかということです。 CPU2によって取得されますか?
CPU1の3段目の粗化領域からアドレスをコピーするか、CPU2に移動して処理するしかありませんが、これにはある程度の時間がかかります。したがって、再バランスを行うと CPU パフォーマンスが低下します。現時点では、プロセス バインディングを使用してこれを実現できます。これにより、プロセスが再度処理されるときに、プロセスの処理に使用された CPU が引き続き使用されます。つまり、プロセスの CPU アフィニティです。
5. キャッシュ内のライトスルーおよびライトバックのメカニズム。
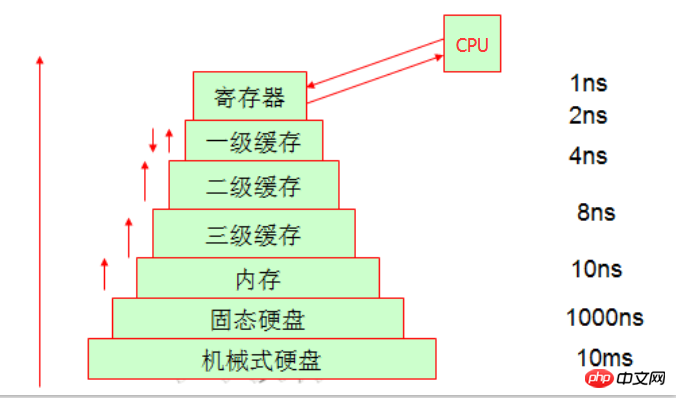
CPUがデータを処理する場所は、レジスタ内でデータを変更することであり、レジスタに探しているデータがない場合は、それを見つけるために1次キャッシュに移動します。 1 次キャッシュ内のデータは、ディスクから見つかるまで順番に 2 次キャッシュに移動し、その後レジスタにロードされます。 3 次キャッシュがメモリからデータをフェッチし、3 次キャッシュが不十分であることが判明すると、3 次キャッシュ内の領域が自動的にクリアされます。
データが保存される最終的な場所はハードディスクであり、このアクセスプロセスはオペレーティングシステムによって完了することがわかっています。 CPU がデータを処理するとき、ライトスルー (メモリへの書き込み) とライトバック (1 次キャッシュへの書き込み) という 2 つの書き込み方法を通じて、データをさまざまな場所に書き込みます。もちろんライトバック性能は良いのですが、一次キャッシュに直接書き込むため、電源が切れるとデータが消えてしまい大変なことになりますが、他のCPUは一次キャッシュにアクセスできません。 , なので、信頼性の観点から見ると、一般的な書き方の方が信頼性が高くなります。使用する具体的な方法は、ユーザー自身のニーズによって異なります。
IV. IOデバイス
1. IOデバイスはデバイスコントローラーとデバイス自体で構成されます。
デバイスコントローラー: マザーボードに統合されたチップまたはチップのセット。オペレーティング システムからコマンドを受信し、コマンドの実行を完了する責任を負います。たとえば、オペレーティング システムからデータを読み取る役割を果たします。
デバイス自体: 独自のインターフェイスがありますが、デバイス自体のインターフェイスは利用できず、単なる物理インターフェイスです。 IDEインターフェースなど。
拡張知識:
各コントローラーには、通信用の少数のレジスタがあります (数から数十の範囲)。このレジスタはデバイス コントローラに直接統合されています。たとえば、最小限のディスク コントローラーは、ディスク アドレス、セクター カウント、読み取りおよび書き込み方向、その他の関連する操作要求のレジスターを指定するためにも使用されます。したがって、コントローラを起動したいときはいつでも、デバイスドライバはオペレーティングシステムから動作命令を受け取り、それを対応するデバイスの基本動作に変換し、動作要求をレジスタに入れて動作を完了します。各レジスタは IO ポートとして動作します。すべてのレジスタの組み合わせはデバイスの I/O アドレス空間と呼ばれ、I/O ポート空間とも呼ばれます
2. ドライバー
実際のハードウェア操作はドライバーの操作によって完了します。通常、ドライバーはデバイスの製造元によって完成される必要があります。通常、ドライバーはカーネルの外で実行できますが、あまりにも非効率であるため、これを実行する人はほとんどいません。
3. 入出力を実装する
各マザーボードのモデルが一致していないため、デバイスの I/O ポートを事前に割り当てることができないため、動的に割り当てる必要があります。コンピュータの電源がオンになると、各 IO デバイスはバスの I/O ポート空間内の I/O ポートを使用するように登録する必要があります。このダイナミック ポートは、デバイスの I/O アドレス空間に結合されたすべてのレジスタで構成されます。ポートは 2^16、つまり 65535 個あります。
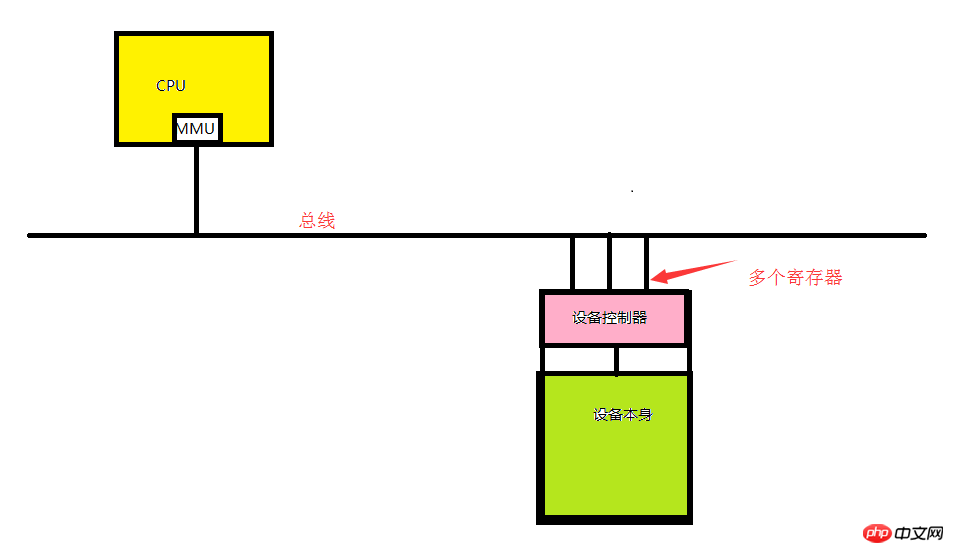
上の図に示すように、CPU が指定されたデバイスを処理したい場合は、その命令をドライバーに渡す必要があります。その後、ドライバーは CPU 命令をデバイスが理解できる信号に変換して送信します。したがって、レジスタ (I/O ポート) は、CPU がバスを介してデバイスと対話するアドレス (I/O ポート) です。
拡張知識:
I/O デバイスの入出力を実装する 3 つの方法:
A.. ポーリング:
通常、システム コールを開始するユーザー プログラムを指し、カーネルはそれを対応するカーネルに変換します。ドライバーのプロシージャが呼び出されると、デバイス ドライバーは I/O を開始し、連続ループでデバイスをチェックして、デバイスが作業を完了したかどうかを確認します。これはビジー待機に似ています (つまり、CPU は固定期間を使用してトラバーサルを通じて各 I/O デバイスを継続的にチェックし、データがあるかどうかを確認します。明らかに、この効率は理想的ではありません。)、
B.. 割り込み:
CPU が処理中のプログラムを中断し、CPU が実行中の演算を中断して、カーネルに割り込み要求を取得するように通知します。通常、マザーボードにはプログラマブル割り込みコントローラーと呼ばれる独自のデバイスがあります。この割り込みコントローラーは、特定のピンを介して CPU と直接通信でき、CPU をトリガーして特定の位置で偏向させることができ、それによって CPU に特定の信号が到着したことを知らせることができます。割り込みコントローラには割り込みベクトルがあります (各 I/O デバイスが起動するときに、割り込みコントローラに割り込み番号を登録してもらいます。この番号は通常一意です。通常、割り込みベクトルの各ピンは複数の割り込みを識別できます)番号)、割り込み番号とも呼ばれます。
そのため、このデバイスで実際に割り込みが発生した場合、このデバイスはデータをバスに直接送信しません。割り込みコントローラーは、割り込みベクトルを使用してその要求がどのデバイスであるかを識別します。から。その後、何らかの方法で CPU に通知して、どのデバイスの割り込み要求が到着したかを CPU に知らせます。このとき、CPU はデバイス登録に応じた I/O ポート番号を使用してデバイスデータを取得することができます。 (CPU は割り込み信号を受信するだけなので、データを直接フェッチできないことに注意してください。CPU はカーネルに通知し、カーネルを CPU 自体で実行させ、カーネルが割り込み要求を取得することしかできません。) たとえば、ネットワーク カードは次のメッセージを受け取ります。外部 IP からのリクエストについては、ネットワーク カードにも独自のキャッシュ領域があり、CPU はネットワーク カード内のキャッシュをメモリに読み込み、それが独自の IP であるかどうかを判断し、そうであればアンパックを開始します。次に、CPIU が自身の割り込みコントローラでこのポートを見つけ、それに応じて処理します。
カーネル割り込み処理は、前半の割り込み (すぐに処理される) と後半の割り込み (必ずしも処理されるわけではない) の 2 つのステップに分かれています。ネットワーク カードからデータを受信する例を考えてみましょう。ユーザーのリクエストがネットワーク カードに到達すると、CPU はネットワーク カードのキャッシュ領域内のデータをメモリに直接フェッチするように命令します。受信後すぐに処理されます(ここでの処理は、ネットワークカードからメモリにデータを転送することです)。これは、後の処理を容易にするために、それ以上の処理を行わずにメモリに読み込まれるだけです。これは、割り込みの上部と呼ばれます。実際にリクエストを処理する後半は
C.DMA と呼ばれます:
ダイレクト メモリ アクセス。データ送信がバス上で実装されることは、CPU がどの I/O デバイスを使用するかを制御するユーザーであることは誰もが知っています。特定の時点でのバスは、CPU コントローラーによって決定されます。バスには、アドレス バス (デバイスのアドレッシング機能を完了する)、コントロール バス (バスを使用して各デバイス アドレスの機能を制御する)、およびデータ バス (データ転送を実現する) の 3 つの機能があります。
通常、これは I/O デバイスに付属するインテリジェントな制御チップです (これをダイレクト メモリ アクセス コントローラーと呼びます)。割り込みの前半を処理する必要がある場合、CPU は DMA デバイスに通知します。バスは DMA に戻ります。デバイスは、I/O デバイスのデータをメモリ空間に読み取るために使用できるメモリ空間を使用し、DMA に通知します。 DMA I/O デバイスは、データの読み取りが完了すると、CPU に読み取り操作が完了したことを通知するメッセージを送信します。この時点で、CPU はデータがロードされたことをカーネルに通知します。割り込みの後半はカーネルに渡されて処理されます。現在、ネットワーク カード、ハード ドライブなどのほとんどのデバイスは DMA コントローラを使用しています。
5. オペレーティング システムの概念
上記の研究を通じて、コンピューターには 5 つの基本コンポーネントがあることがわかりました。オペレーティング システムは主に、これら 5 つのコンポーネントを比較的直感的なインターフェイスに抽象化し、上位レベルのプログラマまたはユーザーが直接使用します。では、オペレーティング システムで実際に抽象化されているものは何でしょうか?
1.CPU(タイムスライス)
オペレーティングシステムでは、CPUをタイムスライスに抽象化し、さらにプログラムをプロセスに抽象化し、タイムスライスを割り当ててプログラムを実行します。 CPU には、変数がメモリに格納されている集合メモリ アドレスを識別するアドレス指定ユニットがあります。
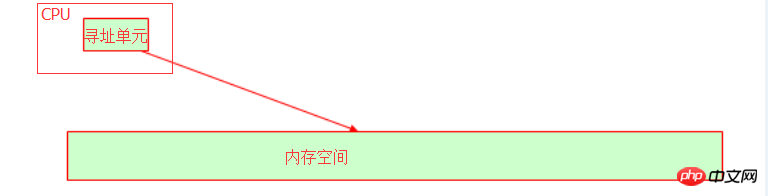
ホストの内部バスは、CPU のビット幅 (ワード長とも呼ばれます) に依存します。たとえば、32 ビットのアドレス バスは、10 進表記に変換すると、2 の 32 乗のメモリ アドレスを表すことができます。 、それは 4G メモリ空間です。この時点で、32 ビット オペレーティング システムが 4G メモリしか認識できない理由を理解できるはずですよね?物理メモリが 16G であっても、使用可能なメモリは 4G であるため、オペレーティング システムが 4G を超えるメモリ アドレスを認識できる場合、オペレーティング システムは 32 ビットであってはなりません。
2. メモリ
オペレーティング システムでは、メモリは仮想アドレス空間を通じて実装されます。
3. I/O デバイス
オペレーティング システムでは、コア I/O デバイスはディスクであり、ディスクはカーネル内のファイルに抽象化されます。
4. プロセス
率直に言えば、コンピューターの存在の主な目的はプログラムを実行することだけではないでしょうか?プログラムが実行されるとき、それをプロセスと呼びます (当面はスレッドについて心配する必要はありません)。複数のプロセスが同時に実行される場合、これらの限られた抽象リソース (CPU、メモリなど) が複数のプロセスに割り当てられることを意味します。これらの抽象リソースを総称してリソース セットと呼びます。
リソース セットには以下が含まれます:
1>.cpu 時間;
2>.メモリ アドレス: 仮想アドレス空間に抽象化されます (4G 空間をサポートする 32 ビット オペレーティング システムなど、カーネルは 1G 空間を占有し、プロセスにはデフォルトで 3G も含まれます。実際には、コンピューターのメモリが 4G 未満である可能性があるため、3G スペースがない可能性があります)
3>.I/O: すべては fd (ファイル記述子) を通じて開かれた複数のファイルです。 、ファイル記述子) 指定されたファイルを開きます。ファイルは、通常ファイル、デバイス ファイル、パイプライン ファイルの 3 つのカテゴリに分類されます。
各プロセスには独自のタスク アドレス構造、つまりタスク構造体があります。これは、プロセスごとにカーネルによって維持されるデータ構造です (データ構造はデータを保存するために使用されます。率直に言うと、プロセスとその親プロセスが所有するリソース セットを記録するメモリ空間です)。シーンを保存します [プロセスの切り替えに使用されます]、メモリ マッピングの待機)。タスク構造体はリニア アドレスをシミュレートし、プロセスがこれらのリニア アドレスを使用できるようにしますが、リニア アドレスと物理メモリ アドレス間のマッピング関係を記録します。
5. メモリ マッピング ページ フレーム
カーネルによって使用される物理メモリ空間でない限り、それをユーザー空間と呼びます。カーネルは、ユーザー空間の物理メモリを固定サイズのページ フレーム (ページ フレーム) に分割します。これは、デフォルトの単一ストレージ ユニット (デフォルトは 1 つ) よりも小さい、固定サイズのストレージ ユニットです。バイト、つまり 8bit ) は、通常 4K ごとに 1 つのストレージ ユニットとして大きくする必要があります。各ページ フレームは独立した単位として外部に割り当てられ、各ページ フレームにも番号が付けられます。 [例: 4G スペースが利用可能で、各ページ フレームが 4K で、合計 1M のページ フレームがあると仮定します。 】これらのページフレームは別のプロセスに割り当てられます。
4G のメモリがあり、オペレーティング システムが 1G を占有し、残りの 3G の物理メモリがユーザー領域に割り当てられていると仮定します。各プロセスが開始されると、利用可能な 3G スペースがあると認識しますが、実際には 3G をまったく使い切ることができません。プロセスによって書き込まれたメモリは個別に保存されます。空きメモリがあるところならどこにでもアクセスしてください。特定のアクセス アルゴリズムについては聞かないでください。私はまだ勉強していません。
プロセス空間の構造:
2>。スタック (変数の保存場所)
4>。ファイル内のデータ ストリームが保存されているファイルを開きます。 ) )
5>. データ セグメント (グローバル静的変数ストレージ)
6>. コード セグメント
プロセスとメモリの間のストレージ関係は次のとおりです:
特定のプロセスは、開いたデータではもう十分ではないことに気づき、新しいファイルを開く必要があります (新しいファイルを開くには、プロセスのアドレス空間にデータを保存する必要があります) 明らかに、上の図のプロセスのアドレス空間は線形です。本当の意味ではありません。プロセスが実際にメモリを申請するときは、カーネルへのシステム コールを開始する必要があります。カーネルは物理メモリ内の物理スペースを見つけ、使用できるメモリ アドレスをプロセスに通知します。たとえば、プロセスがヒープ上のファイルを開きたい場合、物理メモリによって許可される範囲内で、オペレーティング システム (カーネル) からメモリ領域を申請する必要があります (つまり、要求されたメモリは次の値よりも小さい必要があります)。空き物理メモリ)、カーネルはそれをプロセス メモリ アドレスに割り当てます。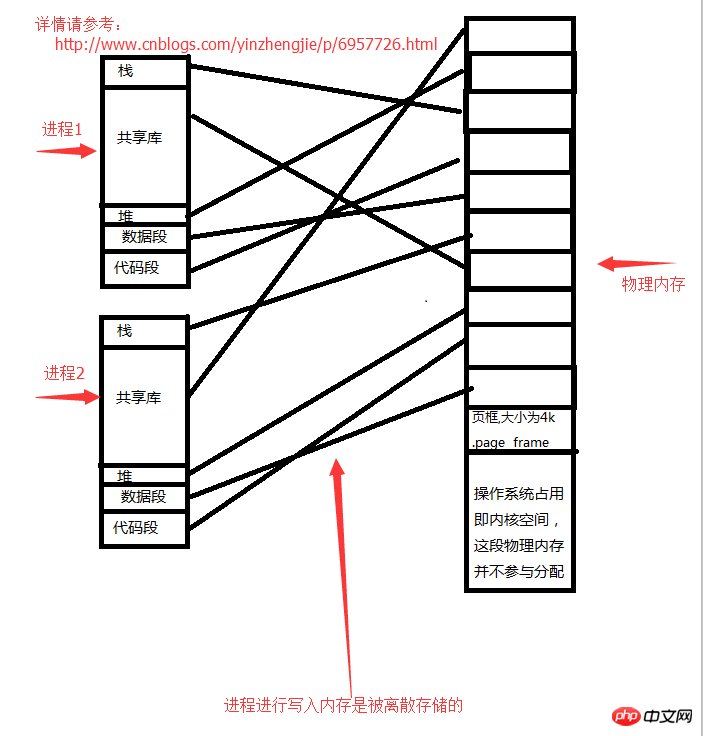 各プロセスには独自のリニア アドレスがあります。このアドレスはオペレーティング システムによって仮想化されており、実際には存在しません。図「プロセスとメモリのストレージ」に示すように、この仮想アドレスを実際の物理メモリにマップする必要があります。関係」では、プロセス データの最終的な保存場所は依然としてメモリにマップされています。これは、プロセスが実行のために CPU に実行されるときに、CPU に自身のリニア アドレスを伝えることを意味します。この時点では、CPU はリニア アドレスを直接見つけません (リニア アドレスは仮想であり、実際には存在しないため)。プロセスは物理メモリ アドレスを格納します)、最初にプロセスの「タスク構造体」を見つけて、ページ テーブルをロードします (リニア アドレスと物理メモリの間のマッピング関係を記録します。それぞれの対応関係はページ テーブル エントリと呼ばれます)。 ]を使用して、プロセスが所有するリニアアドレスに対応する実際の物理メモリアドレスを読み取ります。
各プロセスには独自のリニア アドレスがあります。このアドレスはオペレーティング システムによって仮想化されており、実際には存在しません。図「プロセスとメモリのストレージ」に示すように、この仮想アドレスを実際の物理メモリにマップする必要があります。関係」では、プロセス データの最終的な保存場所は依然としてメモリにマップされています。これは、プロセスが実行のために CPU に実行されるときに、CPU に自身のリニア アドレスを伝えることを意味します。この時点では、CPU はリニア アドレスを直接見つけません (リニア アドレスは仮想であり、実際には存在しないため)。プロセスは物理メモリ アドレスを格納します)、最初にプロセスの「タスク構造体」を見つけて、ページ テーブルをロードします (リニア アドレスと物理メモリの間のマッピング関係を記録します。それぞれの対応関係はページ テーブル エントリと呼ばれます)。 ]を使用して、プロセスが所有するリニアアドレスに対応する実際の物理メモリアドレスを読み取ります。
拡張知識:
CPU がプロセスのアドレスにアクセスするとき、CPU は最初にプロセスのリニア アドレスを取得し、実際の物理メモリ アドレスを取得するための計算のためにこのリニア アドレスを自身のチップ MMU に渡します。 process メモリアドレスの目的。つまり、プロセスのメモリ アドレスにアクセスする限り、MMU 操作を実行する必要があり、効率が非常に低いため、頻繁にアクセスされるデータを格納するキャッシュを導入して効率を向上させました。 MMU は計算を実行し、処理のためにデータを直接取得します。TLB: 変換バックアップ バッファ (ページ テーブルのクエリ結果をキャッシュ) と呼びます。
注: 32 ビット オペレーティング システムでは、ライン アドレスは物理メモリのマッピング。 64 ビット オペレーティング システムでは、まったく逆になります。
6. ユーザー状態とカーネル状態
オペレーティング システムの実行中に調整されたマルチタスクを実現するために、オペレーティング システムは 2 つのセグメントに分割され、そのうちの 1 つはハードウェアに近く、カーネルと呼ばれる特権権限を持っています。プロセスはスペース内のユーザーで実行されます。したがって、アプリケーションが特権命令を使用したり、ハードウェア リソースにアクセスしたりする必要がある場合は、システム コールが必要になります。
それがアプリケーションとして開発され、オペレーティング システム自体の一部として存在しない限り、私たちはそれをユーザー空間プログラムと呼びます。それらの実行状態はユーザーモードと呼ばれます。
カーネル (オペレーティング システムと考えることができます) 空間で実行する必要があるプログラムは、カーネル空間で実行されていると呼ばれ、それらが実行される状態はユーザー モード (コア モードとも呼ばれます) です。注: カーネルは特定の作業を完了する責任を負いません。カーネル空間で使用して、特権操作を実行できます。
すべてのプログラムを実際に実行するには、最終的にカーネルへのシステムコールを開始する必要があります。または、一部のプログラムはカーネルの参加を必要とせず、アプリケーションで完了できます。たとえてみましょう。2 の 32 乗の結果を計算したい場合、カーネル状態で実行する必要がありますか?答えは「いいえ」です。カーネルは特定の作業を完了する責任を負わないことを知っています。したがって、必要なのは値の計算に関するコードを記述するだけであり、特権モードを呼び出す必要はありません。このコードは CPU に渡されて実行されます。
アプリケーションがユーザー プログラムの関数ではなくカーネルの関数を呼び出す必要がある場合、アプリケーションは特権操作を実行する必要があることがわかり、アプリケーション自体にはこの機能が適用されません。カーネルにアクセスし、特権操作の完了を支援するようにカーネルに依頼します。カーネルは、アプリケーションが特権命令を使用する権限を持っていることを検出し、これらの特権命令を実行し、実行結果をアプリケーションに返します。その後、アプリケーションは、特権命令の実行結果を取得した後、後続のコードを続行します。これはパラダイムシフトです。
そのため、プログラマーがプログラムの生産性を高めたい場合は、コードをユーザー空間で実行できるようにする必要があります。コードのほとんどがカーネル空間で実行される場合、アプリケーションはあまり高い生産性をもたらさないと推定されます。 。それは、カーネルスペースが生産性に影響を与えないことを知っているからです。
知識の拡大:
コンピューターの動作は操作によって指定されることを知っています。命令も特権命令レベルと非特権命令レベルに分けられます。コンピュータに詳しい方はご存知かと思いますが、X86 の CPU アーキテクチャは大きく 4 つのレベルに分かれており、内側からリング 0、リング 1、リング 2、リング 3 と呼ばれます。リング 0 の命令は特権命令であり、リング 3 の命令はユーザー命令であることがわかります。一般に、特権命令レベルとは、ハードウェアの操作、バスの制御などを指します。
プログラムの実行にはカーネルの調整が必要であり、ユーザーモードとカーネルモードを切り替えることができるため、プログラムの実行はカーネルによって実行のためにCPUにスケジュールされる必要があります。一部のアプリケーションは、オペレーティング システムの動作中に実行され、基本的な機能をバックグラウンドで自動的に実行します。これはデーモン プロセスと呼ばれます。しかし、一部のプログラムはユーザーが必要とする場合にのみ実行されます。では、必要なアプリケーションを実行するようにカーネルに通知するにはどうすればよいでしょうか。現時点では、オペレーティング システムを処理して命令の実行を開始できるインタープリタが必要です。率直に言うと、これはユーザーの実行リクエストをカーネルに送信できることを意味し、カーネルはその動作に必要な基本条件を開くことができます。その後、プログラムが実行されます。
関連する推奨事項:
Linux オペレーティング システムでの CPU 割り込み
Linux オペレーティング システムのセキュリティ強化に関するチュートリアルの例
以上がLinux オペレーティング システムの基本原理の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



