

私は最近 PHP を勉強していて、PHP による MySQL の同時クエリの問題に遭遇しました。この記事では主に PHP による MySQL の同時クエリのサンプルコードを紹介します。共有して参考にさせていただきます。編集者をフォローして見てみましょう。皆さんのお役に立てれば幸いです。
同期クエリ
これは最も一般的な呼び出しモードです。クライアントは Query [関数] を呼び出し、クエリ コマンドを開始し、結果が返されるのを待ってから、2 番目のクエリ コマンドを送信して待機します。返される結果を取得し、結果を取得します。所要時間の合計は、2 つのクエリの時間の合計になります。たとえば、以下に示すようにプロセスを簡略化します。
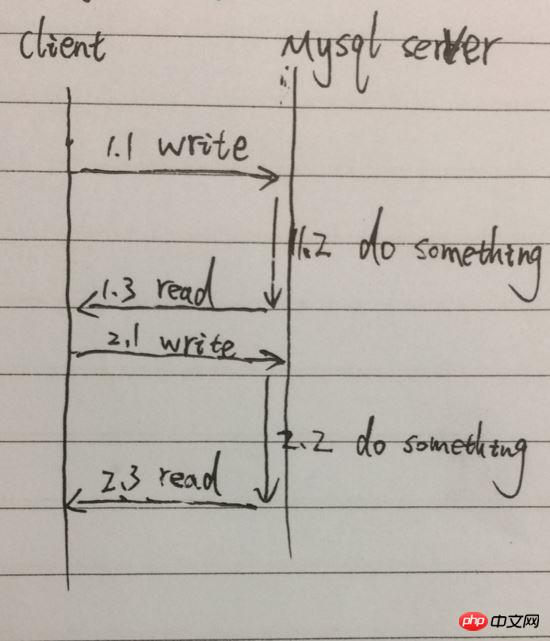
サンプル画像、1.1 から 1.3 は Query [関数] の呼び出しです。2 つのクエリは 1.1、1.2、1.3、2.1、2.2、2.3 を通過します。特に 1.2 と 2.2 では、ブロックされて待機し、プロセスは他のことを行うことができません。
同期呼び出しの利点は、私たちの直感的な考え方に準拠しており、呼び出しと処理が簡単であることです。欠点は、結果が返されるのを待ってプロセスがブロックされ、実行時間が余分にかかることです。
複数のクエリリクエストがある場合、またはプロセスが他の処理を行っている場合、待ち時間を合理的に利用してプロセスの処理能力を向上させることは可能ですか?
分割
次に、Query [関数] を分割します。クライアントは 1.1 の直後に戻り、1.2 をスキップして 1.3 にデータが到着した後にデータを読み取ります。このようにして、プロセスは元の 1.2 の段階から解放され、別の SQL クエリ [2.1] を開始するなど、より多くのことを実行できるようになります。並行クエリのプロトタイプを見たことがありますか?
同時クエリ
同期クエリと比較して、同時クエリでは、前のクエリリクエストが開始された直後に次のクエリリクエストを開始できます。以下に示すように、プロセスを簡略化します。
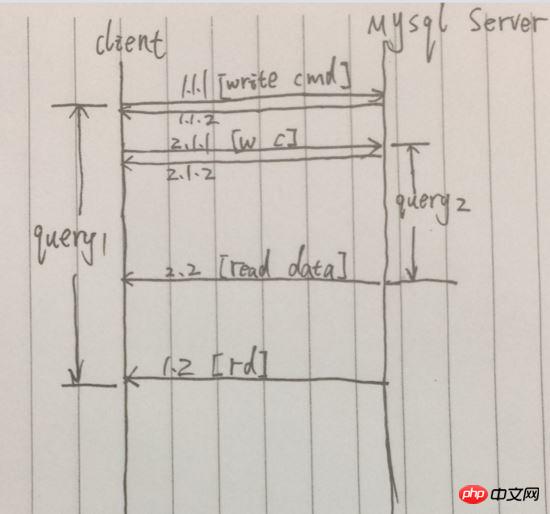
例の図では、1.1.1 でリクエストが正常に送信された後、すぐに [1.1.2] が返され、最終的なクエリ結果がリモート 1.2 で返されます。ただし、1.1.1 と 1.2 の間では、この期間中に 2 つのクエリ リクエストが同時に開始され、2.2 が 1.2 よりも前に到着したため、2 つのクエリの合計消費時間はわずかに等しくなりました。最初のクエリの。
同時クエリの利点は、プロセスの使用率を向上させ、サーバーがクエリを処理するのを待機するブロックを回避し、複数のクエリの時間を短縮できることです。ただし、欠点も明らかです。N 個の同時クエリを開始するには、データベース接続プールを備えたアプリケーションの場合、この状況を回避できます。
縮退
理想的には、N 個のクエリを同時に実行し、合計の消費時間はクエリ時間が最も長いクエリと同じになるようにする必要があります。ただし、同時クエリが [同期クエリ] に [縮退] する可能性もあります。何?例の図では、2.1.1 より前に 1.2 が返された場合、同時クエリは [同期クエリ] に [縮退] しますが、コストは同期クエリよりも高くなります。
多重化
クエリ1を開始
クエリ2を開始
クエリ3を開始
…
クエリ1を待機中、クエリ2. Query3
はquery2の結果を読み取ります
クエリ 1 の結果を読む
クエリ 3 の結果を読む
では、クエリ結果がいつ返されるか、どのクエリ結果が返されるかを知るには、どうやって待つのでしょうか?
クエリ IO ごとに read を呼び出しますか?ブロッキング IO が発生した場合、1 つの IO でブロックされ、他の IO では結果が返され、処理できなくなります。したがって、ノンブロッキング IO の場合、いずれかの IO がブロックされることを心配する必要はありません。ただし、ポーリングと判定が継続的に発生し、CPU リソースが浪費されます。
この状況では、多重化を使用して複数の IO をポーリングできます。
PHP は MySQL を実装します
PHP の mysqli (mysqlnd ドライバー) は、多重ポーリング IO (mysqli_poll) と非同期クエリ (MYSQLI_ASYNC、mysqli_reap_async_query) を提供します。サンプル コード:
。
mysqli_poll ソース コード:
<?php
$sqls = array(
'SELECT * FROM `mz_table_1` LIMIT 1000,10',
'SELECT * FROM `mz_table_1` LIMIT 1010,10',
'SELECT * FROM `mz_table_1` LIMIT 1020,10',
'SELECT * FROM `mz_table_1` LIMIT 10000,10',
'SELECT * FROM `mz_table_2` LIMIT 1',
'SELECT * FROM `mz_table_2` LIMIT 5,1'
);
$links = [];
$tvs = microtime();
$tv = explode(' ', $tvs);
$start = $tv[1] * 1000 + (int)($tv[0] * 1000);
// 链接数据库,并发起异步查询
foreach ($sqls as $sql) {
$link = mysqli_connect('127.0.0.1', 'root', 'root', 'dbname', '3306');
$link->query($sql, MYSQLI_ASYNC); // 发起异步查询,立即返回
$links[$link->thread_id] = $link;
}
$llen = count($links);
$process = 0;
do {
$r_array = $e_array = $reject = $links;
// 多路复用轮询IO
if(!($ret = mysqli_poll($r_array, $e_array, $reject, 2))) {
continue;
}
// 读取有结果返回的查询,处理结果
foreach ($r_array as $link) {
if ($result = $link->reap_async_query()) {
print_r($result->fetch_row());
if (is_object($result))
mysqli_free_result($result);
} else {
}
// 操作完后,把当前数据链接从待轮询集合中删除
unset($links[$link->thread_id]);
$link->close();
$process++;
}
foreach ($e_array as $link) {
die;
}
foreach ($reject as $link) {
die;
}
}while($process < $llen);
$tvs = microtime();
$tv = explode(' ', $tvs);
$end = $tv[1] * 1000 + (int)($tv[0] * 1000);
echo $end - $start,PHP_EOL;同時クエリ操作の結果
効果をより直観的に確認するために、操作用に最適化されていない 1 億 3,000 万のデータ量を持つテーブルを見つけました。
同時クエリの結果:
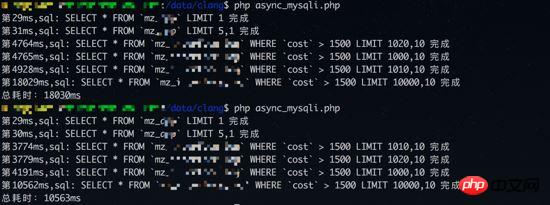
同期クエリの結果:

この結果から、同期クエリの合計消費時間は、すべてのクエリの時間の合計です。同時クエリの消費量は、実際にはこれが最も長いクエリ時間です (同期クエリの 4 番目のクエリには数秒かかりますが、これは同時クエリの合計時間と一致します)。また、同時クエリのクエリ順序は次のとおりです。結果が届く順番とは異なります。
クエリ時間が短い複数のクエリの比較
クエリ時間が短い複数の SQL クエリを使用して比較します
同時クエリのテスト 1 結果 (データベースリンク時間もカウントされます):
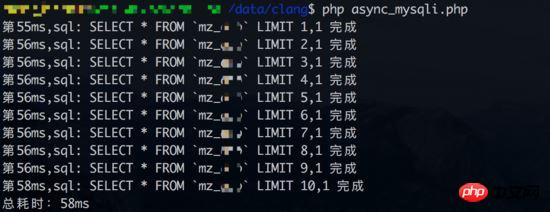
同期の結果クエリ (データベースのリンク時間もカウントされます):
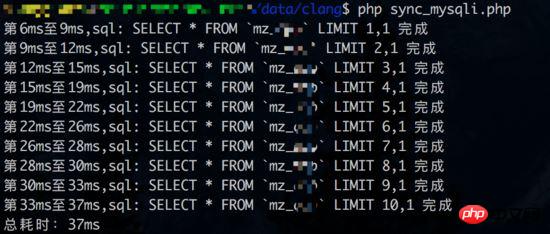
同時クエリ テスト 2 の結果 (データベース リンク時間はカウントされません):
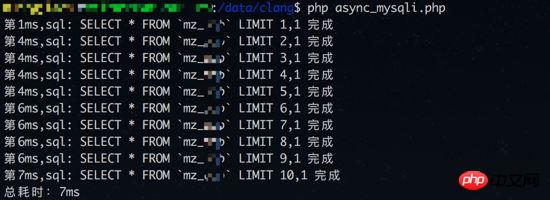
結果から判断すると、同時クエリ テスト 1利益は得られませんでした。同期クエリの観点から見ると、各クエリには約 3 ~ 4 ミリ秒かかります。ただし、データベース接続時間が統計に含まれていない場合 (同期クエリにはデータベース接続が 1 つしかありません)、同時クエリの利点が再び反映される可能性があります。
結論
ここでは、PHP での同時クエリ MySQL の実装について説明し、実験結果から同時クエリの長所と短所を直観的に理解しました。データベース接続を確立する時間が、最適化された SQL クエリの大部分を占めます。 #接続プールがないのですが、何に使えますか
関連する推奨事項:
以上がPHP と同時に MySQL にクエリを実行する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



