

JavaScriptトライプレフィックスツリーコードの詳しい説明

この記事では主に JavaScript のトライワード検索ツリーの概念と実装について詳しく紹介します。興味のある方はぜひ参考にしてください。
はじめに
トライ ツリー (単語検索に由来) は、プレフィックス ワード、単語検索ツリー、辞書ツリーとも呼ばれ、ハッシュ ツリーの変形であるツリー構造であり、高速検索のマルチツリー構造に使用されます。 。
その利点は、不必要な文字列比較を最小限に抑え、ハッシュ テーブルよりもクエリ効率が高いことです。
Trie の核となるアイデアは、空間を時間と交換することです。文字列の共通プレフィックスを使用してクエリ時間のオーバーヘッドを削減し、効率を向上させます。
Trie ツリーにも欠点があります。文字と数字のみを処理すると仮定すると、各ノードには少なくとも 52+10 の子ノードがあります。メモリを節約するには、リンクされたリストまたは配列を使用できます。 JS 配列は動的であり、最適化が組み込まれているため、JS では配列を直接使用します。
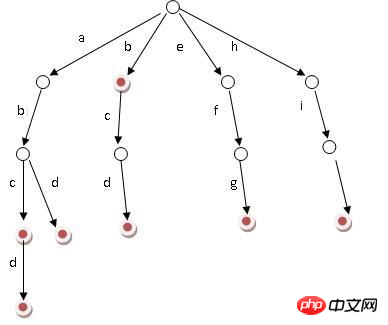
基本プロパティ
ルートノードには文字が含まれず、ルートノードを除くすべての子ノードには文字が含まれます
ルートノードから特定のノードまで。パスを通過する文字は接続されており、これはノードに対応する文字列です
各ノードのすべてのサブノードには異なる文字が含まれています
プログラムの実装
// by 司徒正美
class Trie {
constructor() {
this.root = new TrieNode();
}
isValid(str) {
return /^[a-z1-9]+$/i.test(str);
}
insert(word) {
// addWord
if (this.isValid(word)) {
var cur = this.root;
for (var i = 0; i < word.length; i++) {
var c = word.charCodeAt(i);
c -= 48; //减少”0“的charCode
var node = cur.son[c];
if (node == null) {
var node = (cur.son[c] = new TrieNode());
node.value = word.charAt(i);
node.numPass = 1; //有N个字符串经过它
} else {
node.numPass++;
}
cur = node;
}
cur.isEnd = true; //樯记有字符串到此节点已经结束
cur.numEnd++; //这个字符串重复次数
return true;
} else {
return false;
}
}
remove(word){
if (this.isValid(word)) {
var cur = this.root;
var array = [], n = word.length
for (var i = 0; i < n; i++) {
var c = word.charCodeAt(i);
c = this.getIndex(c)
var node = cur.son[c];
if(node){
array.push(node)
cur = node
}else{
return false
}
}
if(array.length === n){
array.forEach(function(){
el.numPass--
})
cur.numEnd --
if( cur.numEnd == 0){
cur.isEnd = false
}
}
}else{
return false
}
}
preTraversal(cb){//先序遍历
function preTraversalImpl(root, str, cb){
cb(root, str);
for(let i = 0,n = root.son.length; i < n; i ++){
let node = root.son[i];
if(node){
preTraversalImpl(node, str + node.value, cb);
}
}
}
preTraversalImpl(this.root, "", cb);
}
// 在字典树中查找是否存在某字符串为前缀开头的字符串(包括前缀字符串本身)
isContainPrefix(word) {
if (this.isValid(word)) {
var cur = this.root;
for (var i = 0; i < word.length; i++) {
var c = word.charCodeAt(i);
c -= 48; //减少”0“的charCode
if (cur.son[c]) {
cur = cur.son[c];
} else {
return false;
}
}
return true;
} else {
return false;
}
}
isContainWord(str) {
// 在字典树中查找是否存在某字符串(不为前缀)
if (this.isValid(word)) {
var cur = this.root;
for (var i = 0; i < word.length; i++) {
var c = word.charCodeAt(i);
c -= 48; //减少”0“的charCode
if (cur.son[c]) {
cur = cur.son[c];
} else {
return false;
}
}
return cur.isEnd;
} else {
return false;
}
}
countPrefix(word) {
// 统计以指定字符串为前缀的字符串数量
if (this.isValid(word)) {
var cur = this.root;
for (var i = 0; i < word.length; i++) {
var c = word.charCodeAt(i);
c -= 48; //减少”0“的charCode
if (cur.son[c]) {
cur = cur.son[c];
} else {
return 0;
}
}
return cur.numPass;
} else {
return 0;
}
}
countWord(word) {
// 统计某字符串出现的次数方法
if (this.isValid(word)) {
var cur = this.root;
for (var i = 0; i < word.length; i++) {
var c = word.charCodeAt(i);
c -= 48; //减少”0“的charCode
if (cur.son[c]) {
cur = cur.son[c];
} else {
return 0;
}
}
return cur.numEnd;
} else {
return 0;
}
}
}
class TrieNode {
constructor() {
this.numPass = 0;//有多少个单词经过这节点
this.numEnd = 0; //有多少个单词就此结束
this.son = [];
this.value = ""; //value为单个字符
this.isEnd = false;
}
}それに焦点を当てましょうTrieNodeとTrieのinsertメソッド。 辞書ツリーは主に単語頻度統計に使用されるため、numPass、numEnd を含む多くのノード属性がありますが、非常に重要な属性です。
insert メソッドは、重い単語を挿入するために使用されます。開始する前に、その単語が正当であるかどうか、特殊文字と空白を使用できないかどうかを判断する必要があります。挿入時、文字は分割されて各ノードに配置されます。 numPass は、ノードが渡されるたびに変更する必要があります。
最適化
現在、各メソッドには c=-48 の演算が含まれており、実際には、数字、大文字、小文字の間に他の文字があり、不必要なスペースの無駄が発生します
// by 司徒正美
getIndex(c){
if(c < 58){//48-57
return c - 48
}else if(c < 91){//65-90
return c - 65 + 11
}else {//> 97
return c - 97 + 26+ 11
}
}。次に、関連するメソッドは、 c-= 48 を c = this.getIndex(c) に変更することです
Test
var trie = new Trie();
trie.insert("I");
trie.insert("Love");
trie.insert("China");
trie.insert("China");
trie.insert("China");
trie.insert("China");
trie.insert("China");
trie.insert("xiaoliang");
trie.insert("xiaoliang");
trie.insert("man");
trie.insert("handsome");
trie.insert("love");
trie.insert("Chinaha");
trie.insert("her");
trie.insert("know");
var map = {}
trie.preTraversal(function(node, str){
if(node.isEnd){
map[str] = node.numEnd
}
})
for(var i in map){
console.log(i+" 出现了"+ map[i]+" 次")
}
console.log("包含Chin(包括本身)前缀的单词及出现次数:");
//console.log("China")
var map = {}
trie.preTraversal(function(node, str){
if(str.indexOf("Chin") === 0 && node.isEnd){
map[str] = node.numEnd
}
})
for(var i in map){
console.log(i+" 出现了"+ map[i]+" 次")
}
トライ木と他のデータ構造の比較
トライ木と二分探索ツリー
二分探索ツリーは、私たちが最初に接触するツリー構造であるはずです。データ サイズが n の場合、二分探索ツリーの挿入、検索、および削除操作の時間計算量は、通常、わずか O( log n) の場合、最悪の場合、ツリー全体のすべてのノードには子ノードが 1 つだけあり、このとき、挿入、検索、および削除の操作の時間計算量は O(n) になります。
通常、トライ木の高さ n は検索文字列の長さ m よりもはるかに大きいため、検索操作の時間計算量は通常 O(m) であり、最悪の場合の時間計算量は O(n )。トライ ツリーでの最悪の場合の検索が二分探索ツリーよりも高速であることが簡単にわかります。
この記事のトライ ツリーは例として文字列を使用しています。実際、キーが浮動小数点数の場合、トライ ツリー全体が非常に長くなり、ノードが長くなる可能性があります。可読性が低いため、この場合、データを保存するためにトライ ツリーを使用するのは適切ではありません。二分探索ツリーではこの問題は発生しません。
トライツリーとハッシュテーブル
ハッシュ競合の問題を考えてみましょう。通常、ハッシュ テーブルの複雑さは O(1) であると言われますが、実際、これは完全に近いハッシュ テーブルの複雑さです。さらに、ハッシュ関数自体が必要とすることも考慮する必要があります。検索文字列を走査するための計算量は O(m ) です。異なるキーが「同じ位置」にマッピングされている場合 (クローズド ハッシュを考慮すると、この「同じ位置」は通常のリンク リストで置き換えることができます)、検索の複雑さは「同じ位置」番号の下のノードの数に依存します。したがって、最悪の場合、ハッシュ テーブルが一方向のリンク リストになる可能性もあります。
トライ ツリーは、キーのアルファベット順に従って簡単にソートできます (ツリー全体が順番に一度走査されます)。これは、ほとんどのハッシュ テーブルとは異なります (通常、ハッシュ テーブルには異なるキーのシーケンスに対する機能がありません)。
理想的な状況では、ハッシュ テーブルは O(1) の速度でターゲットに迅速にヒットします。テーブルが非常に大きく、ディスク上に配置する必要がある場合、ハッシュ テーブルの検索アクセスは 1 回だけ行う必要があります。理想的な状況ではありますが、トライ ツリーによってアクセスされるディスクの数はノードの深さと同じである必要があります。
多くの場合、トライ ツリーはハッシュ テーブルよりも多くのスペースを必要とします。1 つのノードが 1 つの文字を保存する状況を考慮すると、文字列を保存するときにそれを別のブロックとして保存する方法はありません。トライ ツリーのノード圧縮により、この問題を大幅に軽減できます。これについては後で説明します。
トライ木の改良
ビットごとのトライ木(Bitwise Trie)
原理は通常のトライ木と似ていますが、通常のトライ木に格納される最小単位は文字ですが、ビットごとのトライ木は文字のみを格納します。ビット。ビットデータのアクセスは、CPU 命令によって 1 回直接実装されます。バイナリデータの場合、理論的には通常のトライ木よりも高速です。
ノード圧縮。
ブランチ圧縮: 安定したトライツリーでは、基本的に検索と読み取り操作が実行され、一部のブランチは圧縮できます。たとえば、前の図の右端のブランチの inn は、通常のサブツリーとして存在せずに、ノード「inn」に直接圧縮できます。基数ツリーは、トライ ツリーが深すぎるという問題を解決するために、この原理に基づいています。
ノード マッピング テーブル: この方法は、トライ ツリー内のノードの各状態について、状態の総数が多数の繰り返しによってほぼ完全に決定されている可能性がある場合にも使用されます。要素が数値である多次元配列。配列 (Triple Array Trie など) で表現されるため、追加のマッピング テーブルが導入されますが、Trie ツリー自体を格納するスペースのオーバーヘッドは小さくなります。
プレフィックスツリーの応用
プレフィックスツリーはやはり理解しやすく、その応用範囲も非常に広いです。
(1) 文字列の高速検索
辞書ツリーのクエリ時間計算量はO(logL)、Lは文字列の長さです。したがって、効率は依然として比較的高いです。ディクショナリ ツリーはハッシュ テーブルよりも効率的です。
(2) 文字列の並べ替え
上の図から、単語が並べ替えられ、最初にアルファベット順にたどられていることが簡単にわかります。不要な共通部分文字列を減らします。
(3) 最長の共通接頭辞
inn と int の最長の共通接頭辞は in です。辞書ツリーを文字 n までたどると、この時点でこれらの単語の共通接頭辞は in になります。
(4) 接頭辞を自動的に照合して接尾辞を表示します
辞書や検索エンジンを使用する場合、「appl」と入力すると、接頭辞が「appl」のものが自動的に表示されます。前述したように、辞書ツリーは残りの接尾辞をたどって表示するだけで済みます。
関連おすすめ:
ztrIeeのバックエンドページ開発チュートリアルと組み合わせたuery EasyUIについて
以上がJavaScriptトライプレフィックスツリーコードの詳しい説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7504
7504
 15
1378
52
78
11
19
54
15
1378
52
78
11
19
54

 WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法
Dec 17, 2023 pm 02:54 PM
WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法
Dec 17, 2023 pm 02:54 PM
WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法 はじめに: 技術の継続的な発展により、音声認識技術は人工知能の分野の重要な部分になりました。 WebSocket と JavaScript をベースとしたオンライン音声認識システムは、低遅延、リアルタイム、クロスプラットフォームという特徴があり、広く使用されるソリューションとなっています。この記事では、WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法を紹介します。
 推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
顔の検出および認識テクノロジーは、すでに比較的成熟しており、広く使用されているテクノロジーです。現在、最も広く使用されているインターネット アプリケーション言語は JS ですが、Web フロントエンドでの顔検出と認識の実装には、バックエンドの顔認識と比較して利点と欠点があります。利点としては、ネットワーク インタラクションの削減とリアルタイム認識により、ユーザーの待ち時間が大幅に短縮され、ユーザー エクスペリエンスが向上することが挙げられます。欠点としては、モデル サイズによって制限されるため、精度も制限されることが挙げられます。 js を使用して Web 上に顔検出を実装するにはどうすればよいですか? Web 上で顔認識を実装するには、JavaScript、HTML、CSS、WebRTC など、関連するプログラミング言語とテクノロジに精通している必要があります。同時に、関連するコンピューター ビジョンと人工知能テクノロジーを習得する必要もあります。 Web 側の設計により、次の点に注意してください。
 株価分析に必須のツール: PHP と JS を使用してローソク足チャートを描画する手順を学びます
Dec 17, 2023 pm 06:55 PM
株価分析に必須のツール: PHP と JS を使用してローソク足チャートを描画する手順を学びます
Dec 17, 2023 pm 06:55 PM
株式分析に必須のツール: PHP および JS でローソク足チャートを描画する手順を学びます。特定のコード例が必要です。インターネットとテクノロジーの急速な発展に伴い、株式取引は多くの投資家にとって重要な方法の 1 つになりました。株価分析は投資家の意思決定の重要な部分であり、ローソク足チャートはテクニカル分析で広く使用されています。 PHP と JS を使用してローソク足チャートを描画する方法を学ぶと、投資家がより適切な意思決定を行うのに役立つ、より直感的な情報が得られます。ローソク足チャートとは、株価をローソク足の形で表示するテクニカルチャートです。株価を示しています
 WebSocket と JavaScript: リアルタイム監視システムを実装するための主要テクノロジー
Dec 17, 2023 pm 05:30 PM
WebSocket と JavaScript: リアルタイム監視システムを実装するための主要テクノロジー
Dec 17, 2023 pm 05:30 PM
WebSocketとJavaScript:リアルタイム監視システムを実現するためのキーテクノロジー はじめに: インターネット技術の急速な発展に伴い、リアルタイム監視システムは様々な分野で広く利用されています。リアルタイム監視を実現するための重要なテクノロジーの 1 つは、WebSocket と JavaScript の組み合わせです。この記事では、リアルタイム監視システムにおける WebSocket と JavaScript のアプリケーションを紹介し、コード例を示し、その実装原理を詳しく説明します。 1.WebSocketテクノロジー
 JavaScript と WebSocket を使用してリアルタイムのオンライン注文システムを実装する方法
Dec 17, 2023 pm 12:09 PM
JavaScript と WebSocket を使用してリアルタイムのオンライン注文システムを実装する方法
Dec 17, 2023 pm 12:09 PM
JavaScript と WebSocket を使用してリアルタイム オンライン注文システムを実装する方法の紹介: インターネットの普及とテクノロジーの進歩に伴い、ますます多くのレストランがオンライン注文サービスを提供し始めています。リアルタイムのオンライン注文システムを実装するには、JavaScript と WebSocket テクノロジを使用できます。 WebSocket は、TCP プロトコルをベースとした全二重通信プロトコルで、クライアントとサーバー間のリアルタイム双方向通信を実現します。リアルタイムオンラインオーダーシステムにおいて、ユーザーが料理を選択して注文するとき
 WebSocketとJavaScriptを使ったオンライン予約システムの実装方法
Dec 17, 2023 am 09:39 AM
WebSocketとJavaScriptを使ったオンライン予約システムの実装方法
Dec 17, 2023 am 09:39 AM
WebSocket と JavaScript を使用してオンライン予約システムを実装する方法 今日のデジタル時代では、ますます多くの企業やサービスがオンライン予約機能を提供する必要があります。効率的かつリアルタイムのオンライン予約システムを実装することが重要です。この記事では、WebSocket と JavaScript を使用してオンライン予約システムを実装する方法と、具体的なコード例を紹介します。 1. WebSocket とは何ですか? WebSocket は、単一の TCP 接続における全二重方式です。
 PHP および JS 開発のヒント: 株価ローソク足チャートの描画方法をマスターする
Dec 18, 2023 pm 03:39 PM
PHP および JS 開発のヒント: 株価ローソク足チャートの描画方法をマスターする
Dec 18, 2023 pm 03:39 PM
インターネット金融の急速な発展に伴い、株式投資を選択する人がますます増えています。株式取引では、ローソク足チャートは一般的に使用されるテクニカル分析手法であり、株価の変化傾向を示し、投資家がより正確な意思決定を行うのに役立ちます。この記事では、PHP と JS の開発スキルを紹介し、株価ローソク足チャートの描画方法を読者に理解してもらい、具体的なコード例を示します。 1. 株のローソク足チャートを理解する 株のローソク足チャートの描き方を紹介する前に、まずローソク足チャートとは何かを理解する必要があります。ローソク足チャートは日本人が開発した
 JavaScript と WebSocket: 効率的なリアルタイム天気予報システムの構築
Dec 17, 2023 pm 05:13 PM
JavaScript と WebSocket: 効率的なリアルタイム天気予報システムの構築
Dec 17, 2023 pm 05:13 PM
JavaScript と WebSocket: 効率的なリアルタイム天気予報システムの構築 はじめに: 今日、天気予報の精度は日常生活と意思決定にとって非常に重要です。テクノロジーの発展に伴い、リアルタイムで気象データを取得することで、より正確で信頼性の高い天気予報を提供できるようになりました。この記事では、JavaScript と WebSocket テクノロジを使用して効率的なリアルタイム天気予報システムを構築する方法を学びます。この記事では、具体的なコード例を通じて実装プロセスを説明します。私たちは
