

CSS セレクター フィールドの解析を実装する方法

上で学んだ基本的な CSS 構文の知識に基づいて、フィールド解析を実装しましょう。まず、タイトルを解析します。 Web 開発者ツールを開き、タイトルに対応するソース コードを見つけます。この記事では、フィールド解析を実装するための CSS セレクターに関する情報を主に紹介します。必要な方は参考にしていただければ幸いです
ので、デバッグ用に Scrapy シェルを開いてみました。 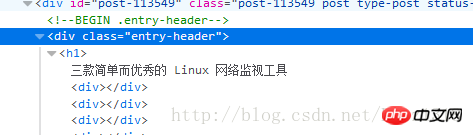
のようなタグが不要な場合はどうすればよいでしょうか? この場合、CSS セレクターで疑似クラス メソッドを使用する必要があります。次のように。
p class="entry-header"
 2 つのコロンに注意してください。 CSSセレクターを使うと本当に便利です。同様に、CSS を使用してフィールド解析を実装します。コードは次のとおりです
2 つのコロンに注意してください。 CSSセレクターを使うと本当に便利です。同様に、CSS を使用してフィールド解析を実装します。コードは次のとおりです
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/113549/']
def parse(self, response):
# title = response.xpath('//p[@class = "entry-header"]/h1/text()').extract()[0]
# create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# praise_numbers = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
# fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# match_re = re.match(".*?(\d+).*",fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath("//a[@href='#article-comment']/span").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# content = response.xpath("//p[@class='entry']").extract()[0]
#通过CSS选择器提取字段
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
praise_numbers = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css("span.bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.css("p.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()[0]
pass 関連する推奨事項:
関連する推奨事項:OpenERP従業員(従業員)テーブルとユーザーテーブル関連フィールド分析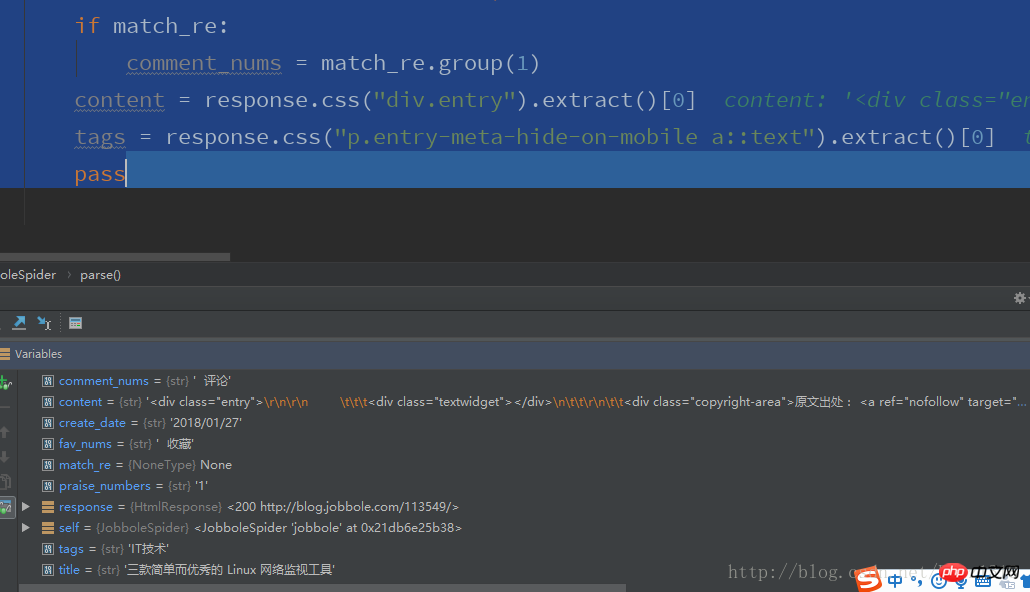
以上がCSS セレクター フィールドの解析を実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7514
7514
 15
1378
52
79
11
19
64
15
1378
52
79
11
19
64

 ブートストラップにスプリットラインを書く方法
Apr 07, 2025 pm 03:12 PM
ブートストラップにスプリットラインを書く方法
Apr 07, 2025 pm 03:12 PM
ブートストラップスプリットラインを作成するには2つの方法があります。タグを使用して、水平方向のスプリットラインを作成します。 CSS Borderプロパティを使用して、カスタムスタイルのスプリットラインを作成します。
 ブートストラップに写真を挿入する方法
Apr 07, 2025 pm 03:30 PM
ブートストラップに写真を挿入する方法
Apr 07, 2025 pm 03:30 PM
ブートストラップに画像を挿入する方法はいくつかあります。HTMLIMGタグを使用して、画像を直接挿入します。ブートストラップ画像コンポーネントを使用すると、レスポンシブ画像とより多くのスタイルを提供できます。画像サイズを設定し、IMG-Fluidクラスを使用して画像を適応可能にします。 IMGボーダークラスを使用して、境界線を設定します。丸い角を設定し、IMGラウンドクラスを使用します。影を設定し、影のクラスを使用します。 CSSスタイルを使用して、画像をサイズ変更して配置します。背景画像を使用して、背景イメージCSSプロパティを使用します。

 ブートストラップのフレームワークをセットアップする方法
Apr 07, 2025 pm 03:27 PM
ブートストラップのフレームワークをセットアップする方法
Apr 07, 2025 pm 03:27 PM
Bootstrapフレームワークをセットアップするには、次の手順に従う必要があります。1。CDNを介してブートストラップファイルを参照してください。 2。独自のサーバーでファイルをダウンロードしてホストします。 3。HTMLにブートストラップファイルを含めます。 4.必要に応じてSASS/LESSをコンパイルします。 5。カスタムファイルをインポートします(オプション)。セットアップが完了したら、Bootstrapのグリッドシステム、コンポーネント、スタイルを使用して、レスポンシブWebサイトとアプリケーションを作成できます。
 HTML、CSS、およびJavaScriptの役割:コアの責任
Apr 08, 2025 pm 07:05 PM
HTML、CSS、およびJavaScriptの役割:コアの責任
Apr 08, 2025 pm 07:05 PM
HTMLはWeb構造を定義し、CSSはスタイルとレイアウトを担当し、JavaScriptは動的な相互作用を提供します。 3人はWeb開発で職務を遂行し、共同でカラフルなWebサイトを構築します。
 ブートストラップボタンの使用方法
Apr 07, 2025 pm 03:09 PM
ブートストラップボタンの使用方法
Apr 07, 2025 pm 03:09 PM
ブートストラップボタンの使用方法は?ブートストラップCSSを導入してボタン要素を作成し、ブートストラップボタンクラスを追加してボタンテキストを追加します
 VueでBootstrapの使用方法
Apr 07, 2025 pm 11:33 PM
VueでBootstrapの使用方法
Apr 07, 2025 pm 11:33 PM
vue.jsでBootstrapを使用すると、5つのステップに分かれています。ブートストラップをインストールします。 main.jsにブートストラップをインポートしますブートストラップコンポーネントをテンプレートで直接使用します。オプション:カスタムスタイル。オプション:プラグインを使用します。
 ブートストラップの日付を表示する方法
Apr 07, 2025 pm 03:03 PM
ブートストラップの日付を表示する方法
Apr 07, 2025 pm 03:03 PM
回答:ブートストラップの日付ピッカーコンポーネントを使用して、ページで日付を表示できます。手順:ブートストラップフレームワークを紹介します。 HTMLで日付セレクター入力ボックスを作成します。ブートストラップは、セレクターにスタイルを自動的に追加します。 JavaScriptを使用して、選択した日付を取得します。
