

php-ml の簡単なテストと使用方法の共有

php-ml は、PHP で書かれた機械学習ライブラリです。 Python や C++ がより多くの機械学習ライブラリを提供していることはわかっていますが、実際には、それらのほとんどは少し複雑で、その構成により多くの初心者は絶望的に感じます。この記事では主にPHPの機械学習ライブラリphp-mlの簡単なテストと使い方を紹介します。編集者はこれが非常に良いものだと思ったので、皆さんの参考として今から共有します。編集者をフォローして見てみましょう。皆さんのお役に立てれば幸いです。
機械学習ライブラリ php-ml には特に高度なアルゴリズムはありませんが、最も基本的な機械学習、分類、その他のアルゴリズムが備わっています。私たちの小さな会社にとっては、簡単なデータ分析や予測などを行うのに十分です。私たちのプロジェクトでは、過剰な効率や精度ではなく、費用対効果を追求する必要があります。一部のアルゴリズムやライブラリは非常に強力に見えますが、すぐにオンライン化することを考えていて、技術スタッフに機械学習の経験がない場合、複雑なコードと構成が実際にプロジェクトの足を引っ張ることになります。そして、単純な機械学習アプリケーションを作成している場合、複雑なライブラリとアルゴリズムを学習するための学習コストは明らかに少し高くなります。さらに、プロジェクトで奇妙な問題が発生した場合、それらを解決できるでしょうか。ニーズが変わった場合はどうすればよいですか?作業中に突然プログラムがエラーを報告し、GoogleやBaiduで検索しても条件に合う質問が1つしか見つからなかった、という経験は誰でもあると思います。数年前、その後は返信ゼロ。 。 。
したがって、最も単純で、最も効率的で、最も費用対効果の高い方法を選択する必要があります。 php-ml の速度は遅くなく (すぐに php7 に変更できます)、精度も良好です。結局のところ、アルゴリズムは同じであり、php は c ベースです。ブロガーが最も嫌がることは、Python、Java、PHP の間でパフォーマンスとアプリケーションの範囲を比較することです。どうしてもパフォーマンスを求める場合はC言語で開発してください。応用範囲を徹底的に追求したい場合は、C またはアセンブリを使用してください。 。 。
まず第一に、このライブラリを使用したい場合は、最初にダウンロードする必要があります。このライブラリファイルはgithub (https://github.com/php-ai/php-ml)からダウンロードできます。もちろん、composer を使用してライブラリをダウンロードし、自動的に設定することをお勧めします。
ダウンロード後、このライブラリのドキュメントを参照して、自分でファイルを作成して試してみることができます。どれもわかりやすいですね。次に、実際のデータでテストしてみましょう。 1 つはアヤメのおしべのデータセットで、もう 1 つは記録が紛失しているため、データの内容がわかりません。 。 。
アイリスのおしべデータには 3 つの異なるカテゴリがあります:
未知のデータセット。小数点はカンマとしてマークされているため、計算中に処理する必要があります:

最初に未知のものを扱います。データセット。まず、未知のデータセットのファイル名は data.txt です。そして、このデータセットは、最初に X-Y 折れ線グラフに描画することができます。したがって、最初に元のデータを折れ線グラフに描画します。 X 軸は比較的長いため、その大まかな形状を確認するだけで済みます:
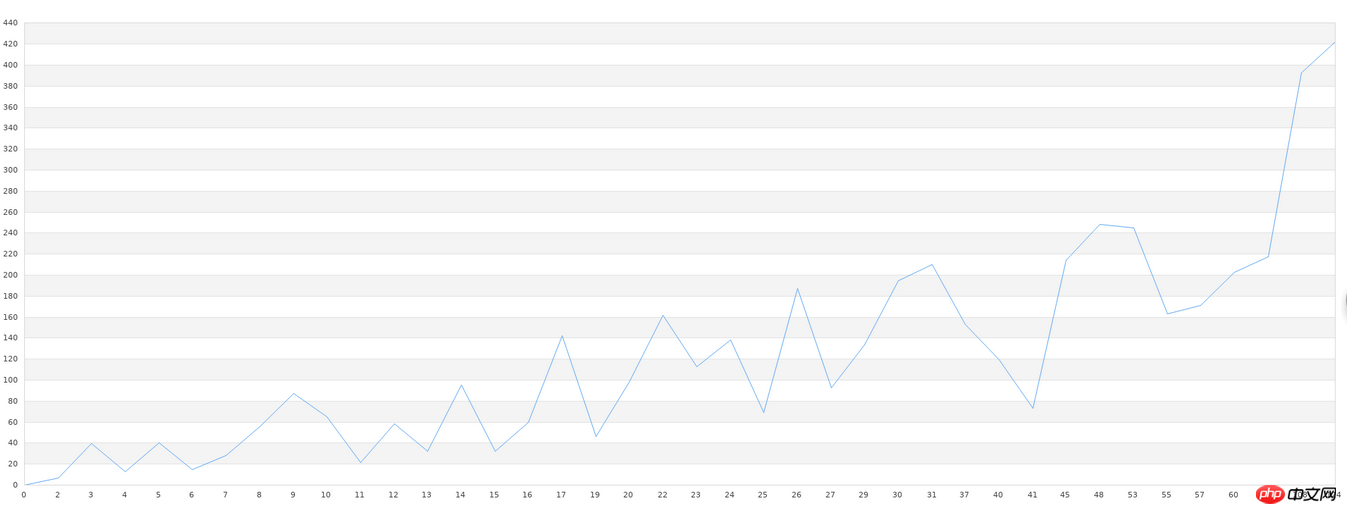
この描画では php の jpgraph ライブラリを使用しており、コードは次のとおりです:
<?php
include_once './src/jpgraph.php';
include_once './src/jpgraph_line.php';
$g = new Graph(1920,1080);//jpgraph的绘制操作
$g->SetScale("textint");
$g->title->Set('data');
//文件的处理
$file = fopen('data.txt','r');
$labels = array();
while(!feof($file)){
$data = explode(' ',fgets($file));
$data[1] = str_replace(',','.',$data[1]);//数据处理,将数据中的逗号修正为小数点
$labels[(int)$data[0]] = (float)$data[1];//这里将数据以键值的方式存入数组,方便我们根据键来排序
}
ksort($labels);//按键的大小排序
$x = array();//x轴的表示数据
$y = array();//y轴的表示数据
foreach($labels as $key=>$value){
array_push($x,$key);
array_push($y,$value);
}
$linePlot = new LinePlot($y);
$g->xaxis->SetTickLabels($x);
$linePlot->SetLegend('data');
$g->Add($linePlot);
$g->Stroke();比較のためにこの元の画像を使用して、次の手順を実行します。勉強。学習にはphp-mlのLeastSquarsを使用します。比較グラフを作成できるように、テストの出力をファイルに保存する必要があります。学習コードは次のとおりです:
<?php
require 'vendor/autoload.php';
use Phpml\Regression\LeastSquares;
use Phpml\ModelManager;
$file = fopen('data.txt','r');
$samples = array();
$labels = array();
$i = 0;
while(!feof($file)){
$data = explode(' ',fgets($file));
$samples[$i][0] = (int)$data[0];
$data[1] = str_replace(',','.',$data[1]);
$labels[$i] = (float)$data[1];
$i ++;
}
fclose($file);
$regression = new LeastSquares();
$regression->train($samples,$labels);
//这个a数组是根据我们对原数据处理后的x值给出的,做测试用。
$a = [0,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,20,22,23,24,25,26,27,29,30,31,37,40,41,45,48,53,55,57,60,61,108,124];
for($i = 0; $i < count($a); $i ++){
file_put_contents("putput.txt",($regression->predict([$a[$i]]))."\n",FILE_APPEND); //以追加的方式存入文件
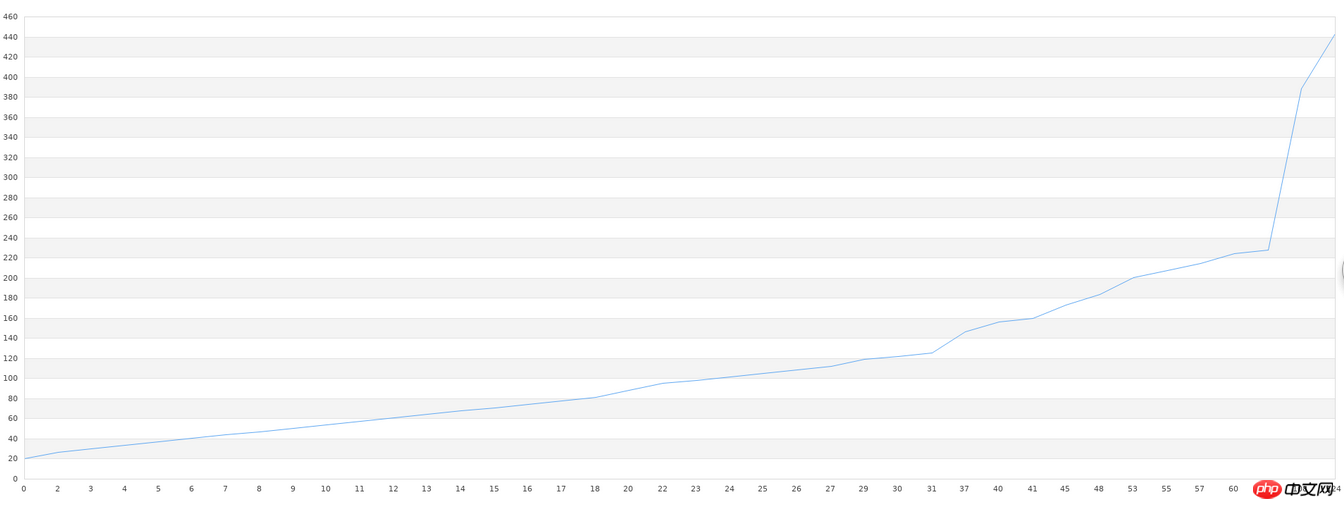
}その後、ファイルに保存されているデータを読み出し、グラフを描画し、最初に最終レンダリングを貼り付けます:
コードは次のとおりです:
<?php
include_once './src/jpgraph.php';
include_once './src/jpgraph_line.php';
$g = new Graph(1920,1080);
$g->SetScale("textint");
$g->title->Set('data');
$file = fopen('putput.txt','r');
$y = array();
$i = 0;
while(!feof($file)){
$y[$i] = (float)(fgets($file));
$i ++;
}
$x = [0,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,20,22,23,24,25,26,27,29,30,31,37,40,41,45,48,53,55,57,60,61,108,124];
$linePlot = new LinePlot($y);
$g->xaxis->SetTickLabels($x);
$linePlot->SetLegend('data');
$g->Add($linePlot);
$g->Stroke();特にギザギザのグラフィックスがある部分では、グラフィックスがまだ比較的大きいことがわかります。ただし、これは結局 40 セットのデータであり、全体的なグラフの傾向は一貫していることがわかります。一般的なライブラリがこのような学習を行う場合、データ量が少ない場合には精度が非常に低くなります。比較的高い精度を得るには大量のデータが必要となり、1万件以上のデータが必要となります。このデータ要件が満たされない場合、私たちが使用するライブラリは無駄になります。したがって、機械学習の実践における本当の困難は、精度の低さや構成の複雑さなどの技術的な問題ではなく、データ量の不足や品質の低さ(一連のデータに無駄なデータが多すぎること)にあります。機械学習を行う前には、データの前処理も必要です。
次に、雄しべのデータをテストしてみましょう。合計3つのカテゴリがあります。csvデータをダウンロードしたので、php-mlが提供する公式のcsvファイルの操作方法を使用できます。これは分類問題であるため、分類にはライブラリによって提供される SVC アルゴリズムを選択します。雌しべデータのファイル名を Iris.csv と名付け、コードは次のとおりです。
<?php require 'vendor/autoload.php'; use Phpml\Classification\SVC; use Phpml\SupportVectorMachine\Kernel; use Phpml\Dataset\CsvDataset; $dataset = new CsvDataset('Iris.csv' , 4, false); $classifier = new SVC(Kernel::LINEAR,$cost = 1000); $classifier->train($dataset->getSamples(),$dataset->getTargets()); echo $classifier->predict([$argv[1],$argv[2],$argv[3],$argv[4]]);//$argv是命令行参数,调试这种程序使用命令行较方便
是不是很简单?短短12行代码就搞定了。接下来,我们来测试一下。根据我们上面贴出的图,当我们输入5 3.3 1.4 0.2的时候,输出应该是Iris-setosa。我们看一下:

看,至少我们输入一个原来就有的数据,得到了正确的结果。但是,我们输入原数据集中没有的数据呢?我们来测试两组:
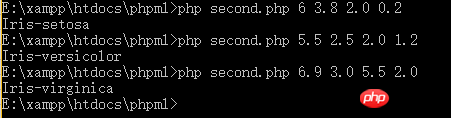
由我们之前贴出的两张图的数据看,我们输入的数据在数据集中并不存在,但分类按照我们初步的观察来看,是合理的。
所以,这个机器学习库对于大多数的人来说,都是够用的。而大多数鄙视这个库鄙视那个库,大谈性能的人,基本上也不是什么大牛。真正的大牛已经忙着捞钱去了,或者正在做学术研究等等。我们更多的应该是掌握算法,了解其中的道理和玄机,而不是夸夸其谈。当然,这个库并不建议用在大型项目上,只推荐小型项目或者个人项目等。
jpgraph只依赖GD库,所以下载引用之后就可以使用,大量的代码都放在了绘制图形和初期的数据处理上。由于库的出色封装,学习代码并不复杂。需要所有代码或者测试数据集的小伙伴可以留言或者私信等,我提供完整的代码,解压即用。
相关推荐:
以上がphp-ml の簡単なテストと使用方法の共有の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1385
52
84
11
28
99
15
1385
52
84
11
28
99

 Ubuntu および Debian 用の PHP 8.4 インストールおよびアップグレード ガイド
Dec 24, 2024 pm 04:42 PM
Ubuntu および Debian 用の PHP 8.4 インストールおよびアップグレード ガイド
Dec 24, 2024 pm 04:42 PM
PHP 8.4 では、いくつかの新機能、セキュリティの改善、パフォーマンスの改善が行われ、かなりの量の機能の非推奨と削除が行われています。 このガイドでは、Ubuntu、Debian、またはその派生版に PHP 8.4 をインストールする方法、または PHP 8.4 にアップグレードする方法について説明します。
 PHP 開発用に Visual Studio Code (VS Code) をセットアップする方法
Dec 20, 2024 am 11:31 AM
PHP 開発用に Visual Studio Code (VS Code) をセットアップする方法
Dec 20, 2024 am 11:31 AM
Visual Studio Code (VS Code とも呼ばれる) は、すべての主要なオペレーティング システムで利用できる無料のソース コード エディター (統合開発環境 (IDE)) です。 多くのプログラミング言語の拡張機能の大規模なコレクションを備えた VS Code は、
 今まで知らなかったことを後悔している 7 つの PHP 関数
Nov 13, 2024 am 09:42 AM
今まで知らなかったことを後悔している 7 つの PHP 関数
Nov 13, 2024 am 09:42 AM
あなたが経験豊富な PHP 開発者であれば、すでにそこにいて、すでにそれを行っていると感じているかもしれません。あなたは、運用を達成するために、かなりの数のアプリケーションを開発し、数百万行のコードをデバッグし、大量のスクリプトを微調整してきました。
 PHPでHTML/XMLを解析および処理するにはどうすればよいですか?
Feb 07, 2025 am 11:57 AM
PHPでHTML/XMLを解析および処理するにはどうすればよいですか?
Feb 07, 2025 am 11:57 AM
このチュートリアルでは、PHPを使用してXMLドキュメントを効率的に処理する方法を示しています。 XML(拡張可能なマークアップ言語)は、人間の読みやすさとマシン解析の両方に合わせて設計された多用途のテキストベースのマークアップ言語です。一般的にデータストレージに使用されます
 JSON Web Tokens(JWT)とPHP APIでのユースケースを説明してください。
Apr 05, 2025 am 12:04 AM
JSON Web Tokens(JWT)とPHP APIでのユースケースを説明してください。
Apr 05, 2025 am 12:04 AM
JWTは、JSONに基づくオープン標準であり、主にアイデンティティ認証と情報交換のために、当事者間で情報を安全に送信するために使用されます。 1。JWTは、ヘッダー、ペイロード、署名の3つの部分で構成されています。 2。JWTの実用的な原則には、JWTの生成、JWTの検証、ペイロードの解析という3つのステップが含まれます。 3. PHPでの認証にJWTを使用する場合、JWTを生成および検証でき、ユーザーの役割と許可情報を高度な使用に含めることができます。 4.一般的なエラーには、署名検証障害、トークンの有効期限、およびペイロードが大きくなります。デバッグスキルには、デバッグツールの使用とロギングが含まれます。 5.パフォーマンスの最適化とベストプラクティスには、適切な署名アルゴリズムの使用、有効期間を合理的に設定することが含まれます。
 母音を文字列にカウントするPHPプログラム
Feb 07, 2025 pm 12:12 PM
母音を文字列にカウントするPHPプログラム
Feb 07, 2025 pm 12:12 PM
文字列は、文字、数字、シンボルを含む一連の文字です。このチュートリアルでは、さまざまな方法を使用してPHPの特定の文字列内の母音の数を計算する方法を学びます。英語の母音は、a、e、i、o、u、そしてそれらは大文字または小文字である可能性があります。 母音とは何ですか? 母音は、特定の発音を表すアルファベットのある文字です。大文字と小文字など、英語には5つの母音があります。 a、e、i、o、u 例1 入力:string = "tutorialspoint" 出力:6 説明する 文字列「TutorialSpoint」の母音は、u、o、i、a、o、iです。合計で6元があります
 PHPでの後期静的結合を説明します(静的::)。
Apr 03, 2025 am 12:04 AM
PHPでの後期静的結合を説明します(静的::)。
Apr 03, 2025 am 12:04 AM
静的結合(静的::) PHPで後期静的結合(LSB)を実装し、クラスを定義するのではなく、静的コンテキストで呼び出しクラスを参照できるようにします。 1)解析プロセスは実行時に実行されます。2)継承関係のコールクラスを検索します。3)パフォーマンスオーバーヘッドをもたらす可能性があります。
 PHPマジックメソッド(__construct、__destruct、__call、__get、__setなど)とは何ですか?
Apr 03, 2025 am 12:03 AM
PHPマジックメソッド(__construct、__destruct、__call、__get、__setなど)とは何ですか?
Apr 03, 2025 am 12:03 AM
PHPの魔法の方法は何ですか? PHPの魔法の方法には次のものが含まれます。1。\ _ \ _コンストラクト、オブジェクトの初期化に使用されます。 2。\ _ \ _リソースのクリーンアップに使用される破壊。 3。\ _ \ _呼び出し、存在しないメソッド呼び出しを処理します。 4。\ _ \ _ get、dynamic属性アクセスを実装します。 5。\ _ \ _セット、動的属性設定を実装します。これらの方法は、特定の状況で自動的に呼び出され、コードの柔軟性と効率を向上させます。
