

JavaScript の基本的なデータ型
JavaScript はリテラルのスクリプト言語であり、型のサポートが組み込まれた、動的に型付けされた弱い型付けのプロトタイプベースの言語です。したがって、JavaScript は非常に基本的な知識であり、この記事では、JavaScript を必要とする友人が参照できるように、基本的なデータ型と参照データ型がどのように格納されているかを中心に紹介します。
基本データ構造
スタック
スタックは、セクション内での挿入または削除操作のみを許可する線形テーブルであり、先入れ後出しのデータ構造です。
Heap
Heapはハッシュアルゴリズムに基づいたデータ構造です。
Queue
Queue は先入れ先出し (FIFO) データ構造です。
JavaScript におけるデータ型の保存
JavaScript のデータ型は、基本データ型と参照データ型に分けられます。それらの違いの 1 つは、保存場所の違いです。
基本データ型
JavaScript の基本データ型は次のとおりであることは誰もが知っています:
String
Number
Boolean
Unknown
ヌル
シンボル (今は無視してください)
基本データ型は単純なデータセグメントであり、スタックメモリに格納されます。
参照データ型
JavaScript の参照データ型は次のとおりです:
Array
Object
参照データ型はヒープメモリに保存され、ペアをスタックに保存しますメモリ ヒープ メモリ内の実際のオブジェクトへの参照。したがって、JavaScript での参照データ型の操作は、実際のオブジェクトではなくオブジェクトへの参照に対して行われます。
スタックメモリにはアドレスが格納されており、このアドレスはヒープメモリ内の実際の値と関連付けられていることが分かります。
イラスト
それでは、いくつかの変数を宣言して試してみましょう:
var name="axuebin";
var age=25;
var job;
var arr=[1,2,3];
var obj={age:25};次の図を使用して、メモリ内のデータ型の格納状況を表すことができます:
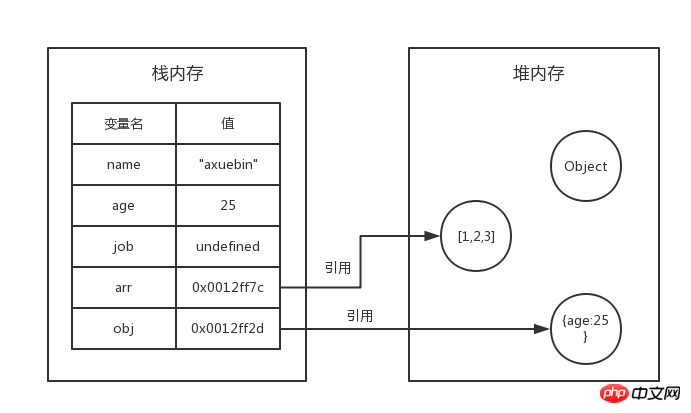
現時点ではname,age,job 3 つの基本データtype はスタック メモリに直接存在しますが、arr と obj はヒープ メモリへの参照を表すためにスタック メモリにアドレスを格納するだけです。
コピー
基本データ型
基本データ型の場合、コピーすると、システムはスタックメモリ内の新しい変数に新しい値を自動的に割り当てます。これは理解しやすいです。
参照データ型
配列やオブジェクトなどの参照データ型の場合、コピー時に違いが生じます。
システムはスタック メモリ内の新しい変数に値を自動的に割り当てますが、この値は単なる値です。アドレス。つまり、コピーされた変数は元の変数と同じアドレス値を持ち、ヒープ メモリ内の同じオブジェクトを指します。
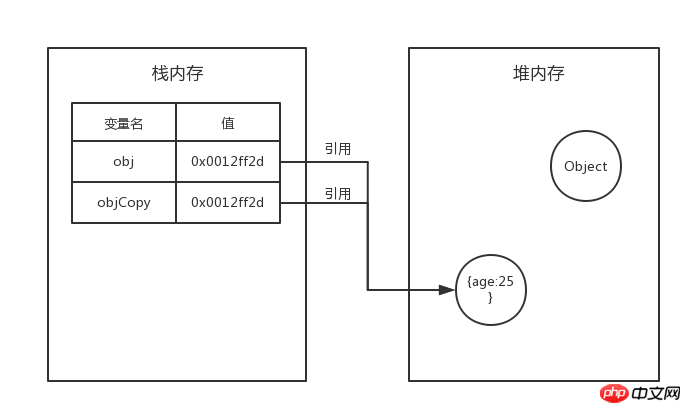
表示されている場合、var objCopy=obj を実行した後、obj と objCopy は同じアドレス値を持ち、ヒープ メモリ内の同じ実際のオブジェクトを実行します。
違いは何ですか?
obj または objCopy を変更すると、別の変数が変更されます。
なぜですか?
なぜ基本データ型はスタック上に存在するのに、参照データ型はヒープ上に存在するのでしょうか?
ヒープはスタックより大きく、スタックの比較は高速です。
基本的なデータ型は比較的安定しており、使用するメモリは比較的少なくなります。
参照データ型のサイズは動的で無制限です。
ヒープ メモリは順序付けされていないストレージであり、参照に基づいて直接取得できます。
参考記事
jsのメモリ割り当てを理解する
プリミティブ値と参照値
ECMAScriptでは変数にプリミティブ値と参照値の2種類の値を格納できます。
プライマリ値とは、元のデータ型(基本データ型)を表す値、つまり、Unknown、Null、Number、String、Boolean 型で表される値を指します。
参照値とは、複合データ型、つまりオブジェクト、関数、配列、カスタムオブジェクトなどの値を指します。
スタックとヒープ
元の値に対応するメモリの構造は2つありますおよび参照値、つまりスタックとヒープ
スタックは後入れ先出しのデータ構造です。JavaScript では、スタックの動作は Array を通じてシミュレートできます
元の値は、に格納されている単純なデータです。スタック、つまり、値は訪問先の変数に直接保存されます。
ヒープはハッシュアルゴリズムに基づいたデータ構造であり、JavaScriptでは参照値がヒープに格納されます。
参照値はヒープに格納されているオブジェクトです。つまり、変数に格納されている値 (つまり、スタックに格納されているオブジェクトを指す変数) は、ヒープに格納されている実際のオブジェクトを指すポインタです。
例:var obj = new Object(); obj存储在栈中它指向于new Object()这个对象,而new Object()是存放在堆中的。
那为什么引用值要放在堆中,而原始值要放在栈中,不都是在内存中吗,为什么不放在一起呢?那接下来,让我们来探索问题的答案!
首先,我们来看一下代码:
function Person(id,name,age){
this.id = id;
this.name = name;
this.age = age;
}
var num = 10;
var bol = true;
var str = "abc";
var obj = new Object();
var arr = ['a','b','c'];
var person = new Person(100,"笨蛋的座右铭",25);然后我们来看一下内存分析图:
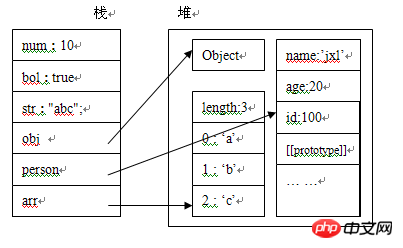
变量num,bol,str为基本数据类型,它们的值,直接存放在栈中,obj,person,arr为复合数据类型,他们的引用变量存储在栈中,指向于存储在堆中的实际对象。
由上图可知,我们无法直接操纵堆中的数据,也就是说我们无法直接操纵对象,但我们可以通过栈中对对象的引用来操作对象,就像我们通过遥控机操作电视机一样,区别在于这个电视机本身并没有控制按钮。
现在让我们来回答为什么引用值要放在堆中,而原始值要放在栈中的问题:
记住一句话:能量是守衡的,无非是时间换空间,空间换时间的问题
堆比栈大,栈比堆的运算速度快,对象是一个复杂的结构,并且可以自由扩展,如:数组可以无限扩充,对象可以自由添加属性。将他们放在堆中是为了不影响栈的效率。而是通过引用的方式查找到堆中的实际对象再进行操作。相对于简单数据类型而言,简单数据类型就比较稳定,并且它只占据很小的内存。不将简单数据类型放在堆是因为通过引用到堆中查找实际对象是要花费时间的,而这个综合成本远大于直接从栈中取得实际值的成本。所以简单数据类型的值直接存放在栈中。
相关推荐:
以上がJavaScript の基本的なデータ型の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7529
7529
 15
1378
52
82
11
21
76
15
1378
52
82
11
21
76

 ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
ddrescue を使用して Linux 上のデータを回復する
Mar 20, 2024 pm 01:37 PM
DDREASE は、ハード ドライブ、SSD、RAM ディスク、CD、DVD、USB ストレージ デバイスなどのファイル デバイスまたはブロック デバイスからデータを回復するためのツールです。あるブロック デバイスから別のブロック デバイスにデータをコピーし、破損したデータ ブロックを残して正常なデータ ブロックのみを移動します。 ddreasue は、回復操作中に干渉を必要としないため、完全に自動化された強力な回復ツールです。さらに、ddasue マップ ファイルのおかげでいつでも停止および再開できます。 DDREASE のその他の主要な機能は次のとおりです。 リカバリされたデータは上書きされませんが、反復リカバリの場合にギャップが埋められます。ただし、ツールに明示的に指示されている場合は切り詰めることができます。複数のファイルまたはブロックから単一のファイルにデータを復元します
 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 Excelのフィルター機能を複数条件で使う方法
Feb 26, 2024 am 10:19 AM
Excelのフィルター機能を複数条件で使う方法
Feb 26, 2024 am 10:19 AM
Excel で複数の条件によるフィルタリングを使用する方法を知る必要がある場合は、次のチュートリアルで、データを効果的にフィルタリングおよび並べ替えできるようにするための手順を説明します。 Excel のフィルタリング機能は非常に強力で、大量のデータから必要な情報を抽出するのに役立ちます。設定した条件でデータを絞り込み、条件に合致した部分のみを表示することができ、データ管理を効率化できます。フィルター機能を利用すると、目的のデータを素早く見つけることができ、データの検索や整理の時間を節約できます。この機能は、単純なデータ リストに適用できるだけでなく、複数の条件に基づいてフィルタリングすることもできるため、必要な情報をより正確に見つけることができます。全体として、Excel のフィルタリング機能は非常に実用的です。
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
顔の検出および認識テクノロジーは、すでに比較的成熟しており、広く使用されているテクノロジーです。現在、最も広く使用されているインターネット アプリケーション言語は JS ですが、Web フロントエンドでの顔検出と認識の実装には、バックエンドの顔認識と比較して利点と欠点があります。利点としては、ネットワーク インタラクションの削減とリアルタイム認識により、ユーザーの待ち時間が大幅に短縮され、ユーザー エクスペリエンスが向上することが挙げられます。欠点としては、モデル サイズによって制限されるため、精度も制限されることが挙げられます。 js を使用して Web 上に顔検出を実装するにはどうすればよいですか? Web 上で顔認識を実装するには、JavaScript、HTML、CSS、WebRTC など、関連するプログラミング言語とテクノロジに精通している必要があります。同時に、関連するコンピューター ビジョンと人工知能テクノロジーを習得する必要もあります。 Web 側の設計により、次の点に注意してください。
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 柔軟かつ高速な 5 本の指を備え、人間のタスクを自律的に完了する初のロボットが登場、大型モデルが仮想空間トレーニングをサポート
Mar 11, 2024 pm 12:10 PM
柔軟かつ高速な 5 本の指を備え、人間のタスクを自律的に完了する初のロボットが登場、大型モデルが仮想空間トレーニングをサポート
Mar 11, 2024 pm 12:10 PM
今週、OpenAI、Microsoft、Bezos、Nvidiaが投資するロボット企業FigureAIは、7億ドル近くの資金調達を受け、来年中に自立歩行できる人型ロボットを開発する計画であると発表した。そしてテスラのオプティマスプライムには繰り返し良い知らせが届いている。今年が人型ロボットが爆発的に普及する年になることを疑う人はいないだろう。カナダに拠点を置くロボット企業 SanctuaryAI は、最近新しい人型ロボット Phoenix をリリースしました。当局者らは、多くのタスクを人間と同じ速度で自律的に完了できると主張している。人間のスピードでタスクを自律的に完了できる世界初のロボットである Pheonix は、各オブジェクトを優しくつかみ、動かし、左右にエレガントに配置することができます。自律的に物体を識別できる
