

Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードします

1. はじめに
クローラー プログラムを使用して Web ページをクロールする場合、静的ページのクロールは一般に比較的簡単であり、これまでにかなりの数のケースを作成しました。しかし、js を使用して動的に読み込まれたページをクロールするにはどうすればよいでしょうか?
動的 js ページにはいくつかのクロール方法があります:
selenium+phantomjs によって実装されます。
phantomjs はヘッドレス ブラウザであり、selenium は自動テスト フレームワークです。ヘッドレス ブラウザを通じてページをリクエストし、js がロードされるのを待ってから、自動テスト Selenium を通じてデータを取得します。ヘッドレス ブラウザは大量のリソースを消費するため、パフォーマンスが不足します。
Scrapy-splash フレームワーク:
Splash は、JS レンダリング サービスとして、Twisted と QT に基づいて開発された軽量ブラウザ エンジンであり、ダイレクト http API を提供します。高速かつ軽量な機能により、分散開発が容易になります。
スプラッシュ クローラー フレームワークとスクレイピー クローラー フレームワークは統合されており、この 2 つは相互に互換性があり、クローリング効率が向上します。
2. Splash環境の構築
Splashサービスはdockerコンテナをベースとしているため、最初にdockerコンテナをインストールする必要があります。
2.1 Docker のインストール (Windows 10 Home バージョン)
Win 10 Professional バージョンまたは他のオペレーティング システムの場合、Windows 10 Home バージョンに Docker をインストールするには、ツールボックスを介してインストールする必要があります (最新)ツールです。
docker のインストールについてはドキュメントを参照してください: WIN10 に Docker をインストール
2.2 Splash のインストール
docker pull scrapinghub/splash
2.3 Splash サービスを開始
docker run -p 8050:8050 scrapinghub/splash
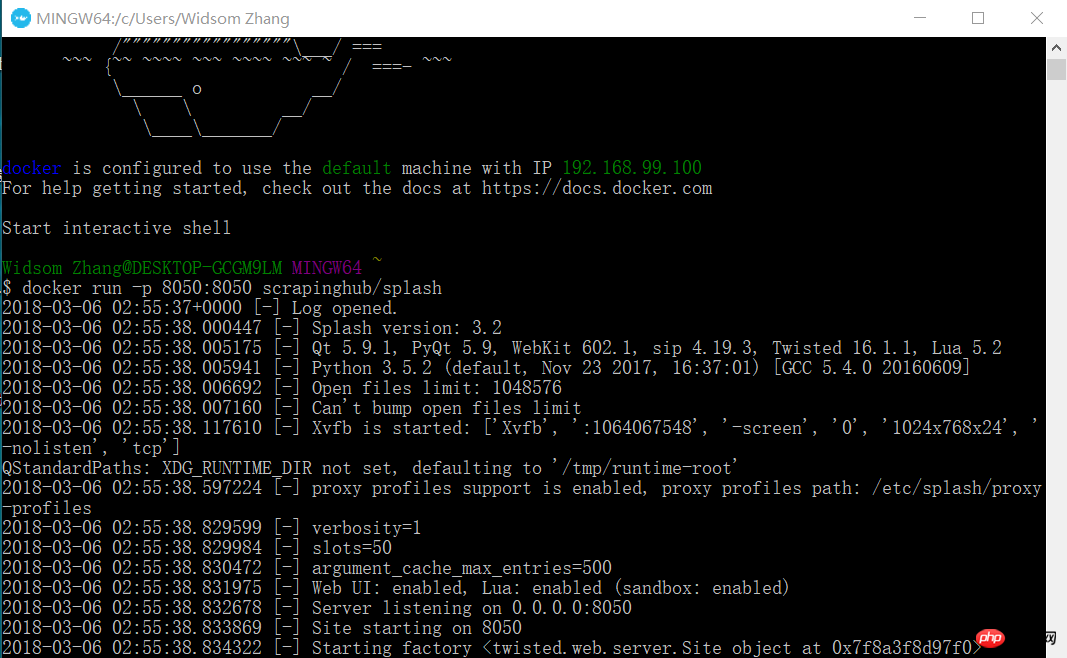
このとき、ブラウザを開いて 192.168.99.100:8050 と入力し、このようなインターフェースが表示されます。
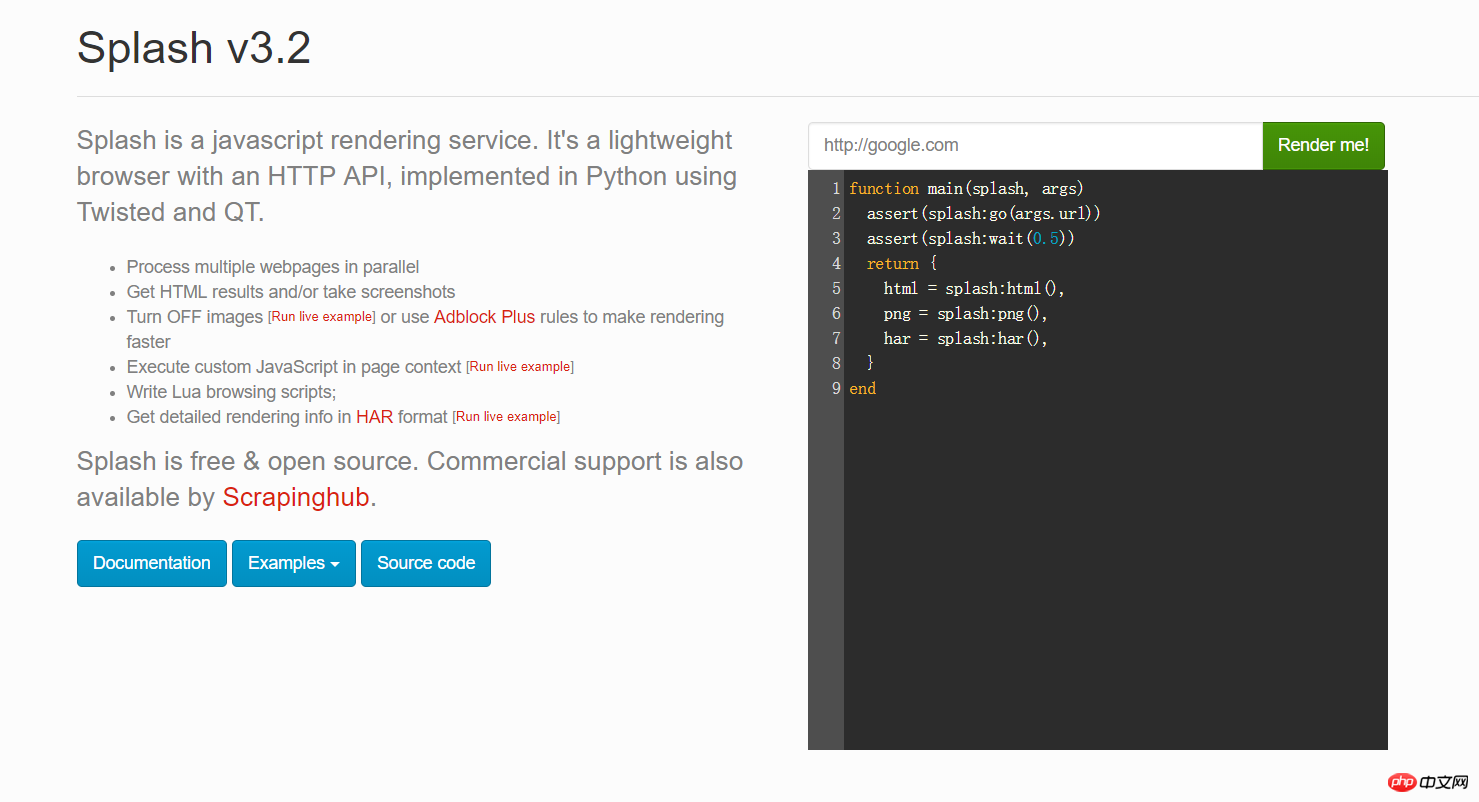
上の画像の赤いボックスに任意の URL を入力し、[レンダリングしてください] をクリックして、レンダリング後の様子を確認します
2.4 Python の Scrapy-splash パッケージをインストールします
pip install scrapy-splash
3。 Google ニュースを例としてテストを行います。
ビジネス上の必要により、Google ニュースなどの一部の海外ニュース ウェブサイトをクロールします。しかし、実際には js コードであることがわかりました。そこで私はscrapy-splashフレームワークを使い始め、Splashのjsレンダリングサービスと連携してデータを取得しました。具体的には、次のコードを確認してください:
3.1 settings.py 構成情報
# 渲染服务的urlSPLASH_URL = 'http://192.168.99.100:8050'# 去重过滤器DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'# 使用Splash的Http缓存HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}#下载器中间件DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}# 请求头DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}# 管道ITEM_PIPELINES = { 'news.pipelines.NewsPipeline': 300,
}3.2 items フィールド定義
class NewsItem(scrapy.Item): # 标题
title = scrapy.Field() # 图片的url链接
Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードします_url = scrapy.Field() # 新闻来源
source = scrapy.Field() # 点击的url
action_url = scrapy.Field()3.3 Spider コード
Spider ディレクトリに、次の内容を含む new_spider.py ファイルを作成します:
from scrapy import Spiderfrom scrapy_splash import SplashRequestfrom news.items import NewsItemclass GoolgeNewsSpider(Spider):
name = "google_news"
start_urls = ["https://news.google.com/news/headlines?ned=cn&gl=CN&hl=zh-CN"] def start_requests(self):
for url in self.start_urls: # 通过SplashRequest请求等待1秒
yield SplashRequest(url, self.parse, args={'wait': 1}) def parse(self, response):
for element in response.xpath('//p[@class="qx0yFc"]'):
actionUrl = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/@href').extract_first()
title = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/text()').extract_first()
source = element.xpath('.//span[@class="IH8C7b Pc0Wt"]/text()').extract_first()
Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードしますUrl = element.xpath('.//img[@class="lmFAjc"]/@src').extract_first()
item = NewsItem()
item['title'] = title
item['Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードします_url'] = Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードしますUrl
item['action_url'] = actionUrl
item['source'] = source yield item3.4 パイプライン .py コード
は、項目データを mysql データベースに保存します。
db_newsデータベースを作成する
CREATE DATABASE db_news
tb_newsテーブルを作成する
CREATE TABLE tb_google_news(
id INT AUTO_INCREMENT,
title VARCHAR(50),
Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードします_url VARCHAR(200),
action_url VARCHAR(200),
source VARCHAR(30), PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8;NewsPipelineクラス
class NewsPipeline(object):
def __init__(self):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='db_news',charset='utf8')
self.cursor = self.conn.cursor() def process_item(self, item, spider):
sql = '''insert into tb_google_news (title,Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードします_url,action_url,source) values(%s,%s,%s,%s)'''
self.cursor.execute(sql, (item["title"], item["Scrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードします_url"], item["action_url"], item["source"]))
self.conn.commit() return item def close_spider(self):
self.cursor.close()
self.conn.close()3.5 スクレイピークローラを実行する
コンソールで実行します:
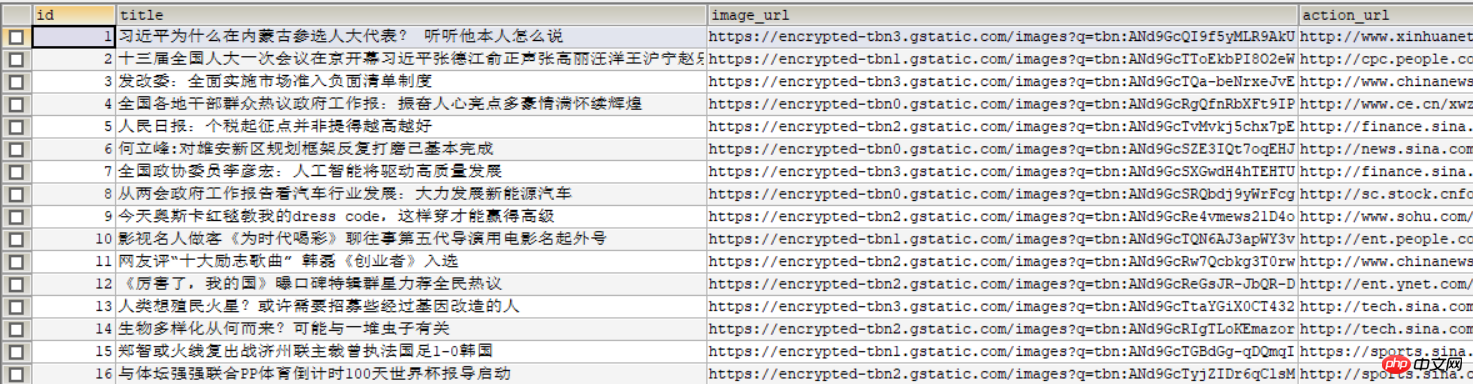
そうです次の画像がデータベースに表示されます:
関連する推奨事項:
以上がScrapy および Scrapy-Splash フレームワークは、JS ページを迅速にロードしますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7518
7518
 15
1378
52
80
11
21
67
15
1378
52
80
11
21
67

 WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法
Dec 17, 2023 pm 02:54 PM
WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法
Dec 17, 2023 pm 02:54 PM
WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法 はじめに: 技術の継続的な発展により、音声認識技術は人工知能の分野の重要な部分になりました。 WebSocket と JavaScript をベースとしたオンライン音声認識システムは、低遅延、リアルタイム、クロスプラットフォームという特徴があり、広く使用されるソリューションとなっています。この記事では、WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法を紹介します。
 WebSocket と JavaScript: リアルタイム監視システムを実装するための主要テクノロジー
Dec 17, 2023 pm 05:30 PM
WebSocket と JavaScript: リアルタイム監視システムを実装するための主要テクノロジー
Dec 17, 2023 pm 05:30 PM
WebSocketとJavaScript:リアルタイム監視システムを実現するためのキーテクノロジー はじめに: インターネット技術の急速な発展に伴い、リアルタイム監視システムは様々な分野で広く利用されています。リアルタイム監視を実現するための重要なテクノロジーの 1 つは、WebSocket と JavaScript の組み合わせです。この記事では、リアルタイム監視システムにおける WebSocket と JavaScript のアプリケーションを紹介し、コード例を示し、その実装原理を詳しく説明します。 1.WebSocketテクノロジー
 JavaScript と WebSocket を使用してリアルタイムのオンライン注文システムを実装する方法
Dec 17, 2023 pm 12:09 PM
JavaScript と WebSocket を使用してリアルタイムのオンライン注文システムを実装する方法
Dec 17, 2023 pm 12:09 PM
JavaScript と WebSocket を使用してリアルタイム オンライン注文システムを実装する方法の紹介: インターネットの普及とテクノロジーの進歩に伴い、ますます多くのレストランがオンライン注文サービスを提供し始めています。リアルタイムのオンライン注文システムを実装するには、JavaScript と WebSocket テクノロジを使用できます。 WebSocket は、TCP プロトコルをベースとした全二重通信プロトコルで、クライアントとサーバー間のリアルタイム双方向通信を実現します。リアルタイムオンラインオーダーシステムにおいて、ユーザーが料理を選択して注文するとき
 WebSocketとJavaScriptを使ったオンライン予約システムの実装方法
Dec 17, 2023 am 09:39 AM
WebSocketとJavaScriptを使ったオンライン予約システムの実装方法
Dec 17, 2023 am 09:39 AM
WebSocket と JavaScript を使用してオンライン予約システムを実装する方法 今日のデジタル時代では、ますます多くの企業やサービスがオンライン予約機能を提供する必要があります。効率的かつリアルタイムのオンライン予約システムを実装することが重要です。この記事では、WebSocket と JavaScript を使用してオンライン予約システムを実装する方法と、具体的なコード例を紹介します。 1. WebSocket とは何ですか? WebSocket は、単一の TCP 接続における全二重方式です。
 JavaScript と WebSocket: 効率的なリアルタイム天気予報システムの構築
Dec 17, 2023 pm 05:13 PM
JavaScript と WebSocket: 効率的なリアルタイム天気予報システムの構築
Dec 17, 2023 pm 05:13 PM
JavaScript と WebSocket: 効率的なリアルタイム天気予報システムの構築 はじめに: 今日、天気予報の精度は日常生活と意思決定にとって非常に重要です。テクノロジーの発展に伴い、リアルタイムで気象データを取得することで、より正確で信頼性の高い天気予報を提供できるようになりました。この記事では、JavaScript と WebSocket テクノロジを使用して効率的なリアルタイム天気予報システムを構築する方法を学びます。この記事では、具体的なコード例を通じて実装プロセスを説明します。私たちは
 簡単な JavaScript チュートリアル: HTTP ステータス コードを取得する方法
Jan 05, 2024 pm 06:08 PM
簡単な JavaScript チュートリアル: HTTP ステータス コードを取得する方法
Jan 05, 2024 pm 06:08 PM
JavaScript チュートリアル: HTTP ステータス コードを取得する方法、特定のコード例が必要です 序文: Web 開発では、サーバーとのデータ対話が頻繁に発生します。サーバーと通信するとき、多くの場合、返された HTTP ステータス コードを取得して操作が成功したかどうかを判断し、さまざまなステータス コードに基づいて対応する処理を実行する必要があります。この記事では、JavaScript を使用して HTTP ステータス コードを取得する方法を説明し、いくつかの実用的なコード例を示します。 XMLHttpRequestの使用
 JavaScriptでinsertBeforeを使用する方法
Nov 24, 2023 am 11:56 AM
JavaScriptでinsertBeforeを使用する方法
Nov 24, 2023 am 11:56 AM
使用法: JavaScript では、insertBefore() メソッドを使用して、DOM ツリーに新しいノードを挿入します。このメソッドには、挿入される新しいノードと参照ノード (つまり、新しいノードが挿入されるノード) の 2 つのパラメータが必要です。
 JavaScript と WebSocket: 効率的なリアルタイム画像処理システムの構築
Dec 17, 2023 am 08:41 AM
JavaScript と WebSocket: 効率的なリアルタイム画像処理システムの構築
Dec 17, 2023 am 08:41 AM
JavaScript は Web 開発で広く使用されているプログラミング言語であり、WebSocket はリアルタイム通信に使用されるネットワーク プロトコルです。 2 つの強力な機能を組み合わせることで、効率的なリアルタイム画像処理システムを構築できます。この記事では、JavaScript と WebSocket を使用してこのシステムを実装する方法と、具体的なコード例を紹介します。まず、リアルタイム画像処理システムの要件と目標を明確にする必要があります。リアルタイムの画像データを収集できるカメラ デバイスがあるとします。
