
今回は、Cookie の有効期限切れ時の自動更新と自動取得を設定するための注意事項と、有効期限切れ時の Cookie の自動更新と自動取得を設定するための実際的なケースを紹介します。
この記事では、Cookieの自動取得と有効期限切れ時のCookieの自動更新を実装しています。
ソーシャル ネットワーキング サイトの多くの情報を取得するにはログインが必要です。Weibo を例に挙げると、ログインしないと、Big Vs の上位 10 件の Weibo 投稿しか見ることができません。ログイン状態を維持するには Cookie が必要です。例として www.weibo.cn へのログインを取り上げます:
Chrome に次のように入力します: http://login.weibo.cn/login/
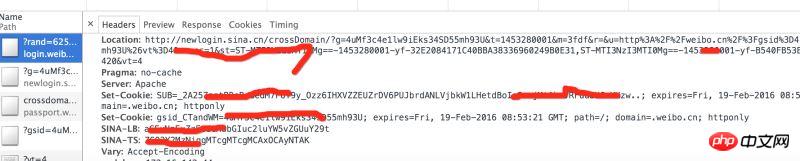
コンソールのヘッダーのリクエストの戻り値を分析すると、 weibo.cn には返された Cookie のセットがいくつかあることがわかります。
実装手順:
1、Seleniumを使用して自動的にログインし、Cookieを取得し、ファイルに保存します。
2、Cookieを読み取り、Cookieの有効期間を比較します(有効期限が切れている場合)。ステップ 1 を再度実行します。
3、他の Web ページをリクエストする場合は、ログイン状態を維持するために Cookie を入力します。
1. オンラインで Cookie を取得します
selenium + PhantomJS を使用してブラウザーのログインをシミュレートし、Cookie を取得します。
通常、Cookie は複数あり、Cookie は .weibo という接尾辞が付いたファイルに 1 つずつ保存されます。
def get_cookie_from_network():
from selenium import webdriver
url_login = 'http://login.weibo.cn/login/'
driver = webdriver.PhantomJS()
driver.get(url_login)
driver.find_element_by_xpath('//input[@type="text"]').send_keys('your_weibo_accout') # 改成你的微博账号
driver.find_element_by_xpath('//input[@type="password"]').send_keys('your_weibo_password') # 改成你的微博密码
driver.find_element_by_xpath('//input[@type="submit"]').click() # 点击登录
# 获得 cookie信息
cookie_list = driver.get_cookies()
print cookie_list
cookie_dict = {}
for cookie in cookie_list:
#写入文件
f = open(cookie['name']+'.weibo','w')
pickle.dump(cookie, f)
f.close()
if cookie.has_key('name') and cookie.has_key('value'):
cookie_dict[cookie['name']] = cookie['value']
return cookie_dict2、ファイルから Cookie を取得します
現在のディレクトリから .weibo で終わるファイル、つまり Cookie ファイルをスキャンします。 pickle を使用して dict に解凍し、有効期限値を現在の時刻と比較し、期限切れの場合は空を返します
def get_cookie_from_cache():
cookie_dict = {}
for parent, dirnames, filenames in os.walk('./'):
for filename in filenames:
if filename.endswith('.weibo'):
print filename
with open(self.dir_temp + filename, 'r') as f:
d = pickle.load(f)
if d.has_key('name') and d.has_key('value') and d.has_key('expiry'):
expiry_date = int(d['expiry'])
if expiry_date > (int)(time.time()):
cookie_dict[d['name']] = d['value']
else:
return {}
return cookie_dict3. キャッシュ Cookie の有効期限が切れた場合は、ネットワークから Cookie を再度取得します
def get_cookie(): cookie_dict = get_cookie_from_cache() if not cookie_dict: cookie_dict = get_cookie_from_network() return cookie_dict
4、他の Weibo ホームページをリクエストするための Cookie
def get_weibo_list(self, user_id):
import requests
from bs4 import BeautifulSoup as bs
cookdic = get_cookie()
url = 'http://weibo.cn/stocknews88'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36'}
timeout = 5
r = requests.get(url, headers=headers, cookies=cookdic,timeout=timeout)
soup = bs(r.text, 'lxml')
...
# 用BeautifulSoup 解析网页
...この記事の事例を読んだ後は、この方法を習得したと思います。さらに興味深い情報については、php 中国語 Web サイトの他の関連記事に注目してください。
推奨読書:
Reactネイティブはfetchを使用して画像をアップロードします
webpackでパッケージ化されたファイルを圧縮後に小さくする方法
JSをパッケージ化するためにimportとrequireを使用します
以上がCookie の有効期限を設定して自動的に更新および取得するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



