

Nodejs クローラー フレームワーク スーパーエージェント
今回は、nodejs クローラー フレームワーク スーパーエージェントについて説明します。具体的なケースを見てみましょう。
はじめに クローラーについては長い間聞いてきましたが、ここ数日でnodejsを学び始め、クローラーを書きました
https://github.com/leichangchun/node-crawlers/tree/クロールする master/superagent_cheerio_demo ブログパークのトップページにある記事タイトル、ユーザー名、閲覧数、おすすめ数、ユーザーアバターの簡単なまとめです。 これらのポイントを使用してください:
1. ノードのコアモジュール --
ファイルシステム2. http リクエスト用のサードパーティモジュール -- superagent
3. DOM を解析するためのサードパーティモジュール -- Cheerio
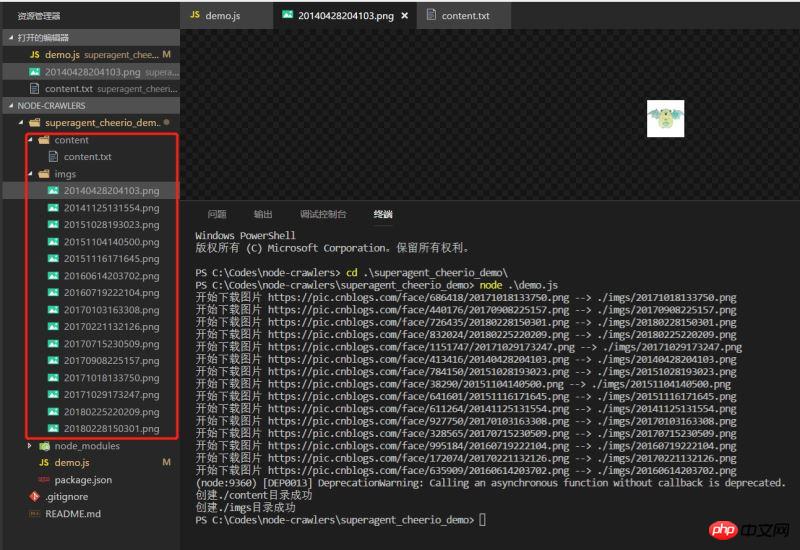
いくつかのモジュールの詳細な説明とAPIについては、それぞれのリンクを参照してください。デモでは簡単な使用方法のみです。 N 準備作業 p NPM管理の依存関係を利用し、package.json内のR
//安装用到的第三方模块 cnpm install --save superagent cheerio
//引入第三方模块,superagent用于http请求,cheerio用于解析DOM
const request = require('superagent');
const cheerio = require('cheerio');
const fs = require('fs'); HTMLコンテンツを取得した後、必要なデータを取得する必要があります。このとき、Cheerioを使用してDOMを解析する必要があります。Cheerioは、最初にターゲットのHTMLをロードしてから、それを解析する必要があります。 jquery の API に慣れている場合は、すぐに使い始めることができます。コードサンプルを直接見てくださいrequest.get(url)
.end(error,res){
//do something
}
//目标链接 博客园首页
let targetUrl = 'https://www.cnblogs.com/';
//用来暂时保存解析到的内容和图片地址数据
let content = '';
let imgs = [];
//发起请求
request.get(targetUrl)
.end( (error,res) => {
if(error){ //请求出错,打印错误,返回
console.log(error)
return;
}
// cheerio需要先load html
let $ = cheerio.load(res.text);
//抓取需要的数据,each为cheerio提供的方法用来遍历
$('#post_list .post_item').each( (index,element) => {
//分析所需要的数据的DOM结构
//通过选择器定位到目标元素,再获取到数据
let temp = {
'标题' : $(element).find('h3 a').text(),
'作者' : $(element).find('.post_item_foot > a').text(),
'阅读数' : +$(element).find('.article_view a').text().slice(3,-2),
'推荐数' : +$(element).find('.diggnum').text()
}
//拼接数据
content += JSON.stringify(temp) + '\n';
//同样的方式获取图片地址
if($(element).find('img.pfs').length > 0){
imgs.push($(element).find('img.pfs').attr('src'));
}
});
//存放数据
mkdir('./content',saveContent);
mkdir('./imgs',downloadImg);
})//创建目录
function mkdir(_path,callback){
if(fs.existsSync(_path)){
console.log(`${_path}目录已存在`)
}else{
fs.mkdir(_path,(error)=>{
if(error){
return console.log(`创建${_path}目录失败`);
}
console.log(`创建${_path}目录成功`)
})
}
callback(); //没有生成指定目录不会执行
}//将文字内容存入txt文件中
function saveContent() {
fs.writeFile('./content/content.txt',content.toString());
}シンプルなもの デモはそれほど厳密ではないかもしれませんが、常にノードに向けた最初の小さなステップです。 この記事の事例を読んだ後は、この方法を習得したと思います。さらに興味深い情報については、php 中国語 Web サイトの他の関連記事に注目してください。 推奨読書:
H5のセマンティックタグ ファイルを読み取ってサーバーにアップロードするH5の方法HTML5で画像の回転のアニメーション効果を実現する方法
以上がNodejs クローラー フレームワーク スーパーエージェントの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1658
1658
 14
1415
52
1309
25
1257
29
1231
24
14
1415
52
1309
25
1257
29
1231
24

 Nodejs はバックエンド フレームワークですか?
Apr 21, 2024 am 05:09 AM
Nodejs はバックエンド フレームワークですか?
Apr 21, 2024 am 05:09 AM
Node.js は、高いパフォーマンス、スケーラビリティ、クロスプラットフォーム サポート、豊富なエコシステム、開発の容易さなどの機能を備えているため、バックエンド フレームワークとして使用できます。
 Nodejsのグローバル変数とは何ですか
Apr 21, 2024 am 04:54 AM
Nodejsのグローバル変数とは何ですか
Apr 21, 2024 am 04:54 AM
Node.js には次のグローバル変数が存在します。 グローバル オブジェクト: グローバル コア モジュール: プロセス、コンソール、require ランタイム環境変数: __dirname、__filename、__line、__column 定数: unknown、null、NaN、Infinity、-Infinity
 Nodejsをmysqlデータベースに接続する方法
Apr 21, 2024 am 06:13 AM
Nodejsをmysqlデータベースに接続する方法
Apr 21, 2024 am 06:13 AM
MySQL データベースに接続するには、次の手順に従う必要があります。 mysql2 ドライバーをインストールします。 mysql2.createConnection() を使用して、ホスト アドレス、ポート、ユーザー名、パスワード、データベース名を含む接続オブジェクトを作成します。 connection.query() を使用してクエリを実行します。最後に connection.end() を使用して接続を終了します。
 Nodejs インストール ディレクトリ内の npm ファイルと npm.cmd ファイルの違いは何ですか?
Apr 21, 2024 am 05:18 AM
Nodejs インストール ディレクトリ内の npm ファイルと npm.cmd ファイルの違いは何ですか?
Apr 21, 2024 am 05:18 AM
Node.js インストール ディレクトリには、npm と npm.cmd という 2 つの npm 関連ファイルがあります。違いは次のとおりです。拡張子が異なります。npm は実行可能ファイルで、npm.cmd はコマンド ウィンドウのショートカットです。 Windows ユーザー: npm.cmd はコマンド プロンプトから使用できますが、npm はコマンド ラインからのみ実行できます。互換性: npm.cmd は Windows システムに固有ですが、npm はクロスプラットフォームで使用できます。使用上の推奨事項: Windows ユーザーは npm.cmd を使用し、他のオペレーティング システムは npm を使用します。
 NodejsとJavaの間に大きな違いはありますか?
Apr 21, 2024 am 06:12 AM
NodejsとJavaの間に大きな違いはありますか?
Apr 21, 2024 am 06:12 AM
Node.js と Java の主な違いは、設計と機能です。 イベント駆動型とスレッド駆動型: Node.js はイベント駆動型で、Java はスレッド駆動型です。シングルスレッドとマルチスレッド: Node.js はシングルスレッドのイベント ループを使用し、Java はマルチスレッド アーキテクチャを使用します。ランタイム環境: Node.js は V8 JavaScript エンジン上で実行され、Java は JVM 上で実行されます。構文: Node.js は JavaScript 構文を使用し、Java は Java 構文を使用します。目的: Node.js は I/O 集中型のタスクに適しており、Java は大規模なエンタープライズ アプリケーションに適しています。
 Nodejs はバックエンド開発言語ですか?
Apr 21, 2024 am 05:09 AM
Nodejs はバックエンド開発言語ですか?
Apr 21, 2024 am 05:09 AM
はい、Node.js はバックエンド開発言語です。これは、サーバー側のビジネス ロジックの処理、データベース接続の管理、API の提供などのバックエンド開発に使用されます。
 Nodejsはフロントエンドを書くことができますか?
Apr 21, 2024 am 05:00 AM
Nodejsはフロントエンドを書くことができますか?
Apr 21, 2024 am 05:00 AM
はい、Node.js はフロントエンド開発に使用でき、主な利点には、高性能、豊富なエコシステム、クロスプラットフォーム互換性が含まれます。考慮すべき点は、学習曲線、ツールのサポート、コミュニティの規模の小ささです。
 NodejsとJavaのどちらを選択しますか?
Apr 21, 2024 am 04:40 AM
NodejsとJavaのどちらを選択しますか?
Apr 21, 2024 am 04:40 AM
Web 開発において Node.js と Java にはそれぞれ長所と短所があり、どちらを選択するかはプロジェクトの要件によって異なります。 Node.js はリアルタイム アプリケーション、迅速な開発、マイクロサービス アーキテクチャに優れており、Java はエンタープライズ グレードのサポート、パフォーマンス、セキュリティに優れています。
